 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Supervisor for Cross-dataset Object Detection
Paper and Code
Apr 01, 2022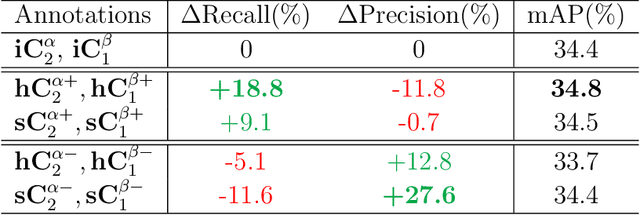
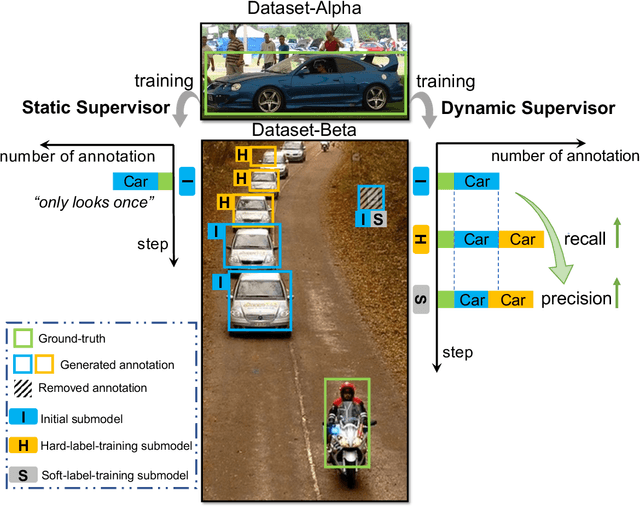

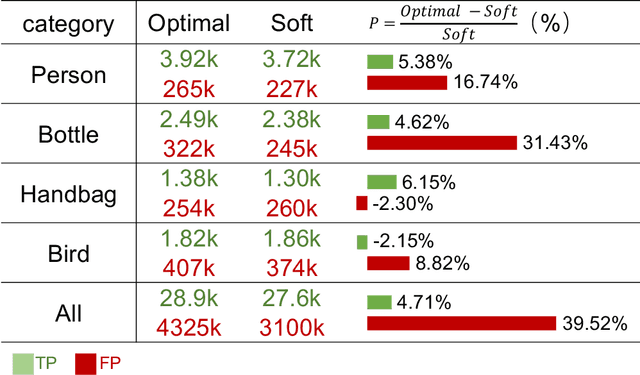
The application of cross-dataset training in object detection tasks is complicated because the inconsistency in the category range across datasets transforms fully supervised learning into semi-supervised learning. To address this problem, recent studies focus on the generation of high-quality missing annotations. In this study, we first point out that it is not enough to generate high-quality annotations using a single model, which only looks once for annotations. Through detailed experimental analyses, we further conclude that hard-label training is conducive to generating high-recall annotations, while soft-label training tends to obtain high-precision annotations. Inspired by the aspects mentioned above, we propose a dynamic supervisor framework that updates the annotations multiple times through multiple-updated submodels trained using hard and soft labels. In the final generated annotations, both recall and precision improve significantly through the integration of hard-label training with soft-label training. Extensive experiments conducted on various dataset combination settings support our analyses and demonstrate the superior performance of the proposed dynamic supervisor.