 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimultaneous Improvement of ML Model Fairness and Performance by Identifying Bias in Data
Paper and Code
Oct 24, 2022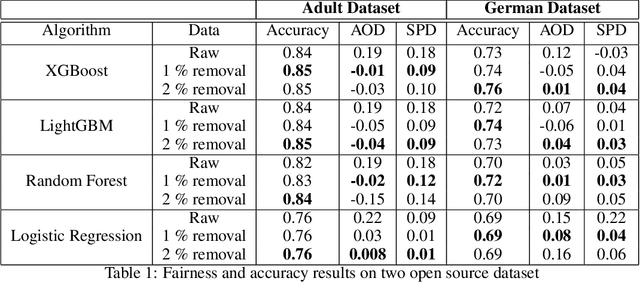
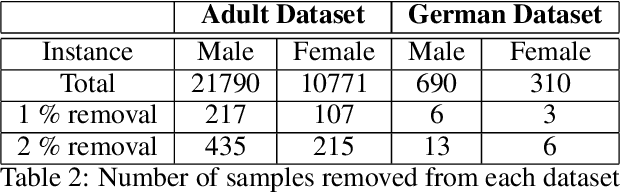
Machine learning models built on datasets containing discriminative instances attributed to various underlying factors result in biased and unfair outcomes. It's a well founded and intuitive fact that existing bias mitigation strategies often sacrifice accuracy in order to ensure fairness. But when AI engine's prediction is used for decision making which reflects on revenue or operational efficiency such as credit risk modelling, it would be desirable by the business if accuracy can be somehow reasonably preserved. This conflicting requirement of maintaining accuracy and fairness in AI motivates our research. In this paper, we propose a fresh approach for simultaneous improvement of fairness and accuracy of ML models within a realistic paradigm. The essence of our work is a data preprocessing technique that can detect instances ascribing a specific kind of bias that should be removed from the dataset before training and we further show that such instance removal will have no adverse impact on model accuracy. In particular, we claim that in the problem settings where instances exist with similar feature but different labels caused by variation in protected attributes , an inherent bias gets induced in the dataset, which can be identified and mitigated through our novel scheme. Our experimental evaluation on two open-source datasets demonstrates how the proposed method can mitigate bias along with improving rather than degrading accuracy, while offering certain set of control for end user.