 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvery Eval Ever: A Unifying Schema and Community Repository for AI Evaluation Results
Jun 12, 2026AI evaluations are widely used for testing and understanding progress. However, the diverse evaluators bring with them inconsistencies that challenge analysis and comparison. First, results are saved in incompatible formats, scattered across leaderboards, papers, blog posts, evaluation harness logs, and custom repositories. Second, results are created by different evaluation frameworks, which produce divergent scores for nominally identical evaluations and record metadata inconsistently, hindering comparison, cross-community evaluation science, cost reduction, and reuse. We introduce Every Eval Ever, the first shared schema and community-crowdsourced repository for AI evaluation results. The schema standardizes how evaluations are represented in a unified, single JSON document. It is source-agnostic by design, ingesting results from evaluation harnesses and papers alike, and optionally stores per-instance outputs for fine-grained analysis. We contribute: (i) a community-governed metadata schema with a companion instance-level schema, the first standardization effort of its kind; (ii) automatic converters from popular formats, evaluation harnesses, and leaderboards to the unified schema; and (iii) a crowdsourced community database hosted on Hugging Face, currently spanning to date 22,235 models, 2,273 unique benchmarks, and 31 evaluation formats.
Evaluation Cards: An Interpretive Layer for AI Evaluation Reporting
Jun 09, 2026AI evaluation results are produced at scale but reported inconsistently across leaderboards, model cards, benchmark papers, and company blogs. The cost is interpretive: readers cannot reliably compare results across sources, identify what a report omits, or trace an aggregate claim to its underlying evidence. Recent efforts address isolated components but leave three gaps: they cover only narrow slices of the evaluation lifecycle and do not compose into a single interpretable record; they specify static representations that do not differentiate the questions different stakeholders bring to the same evidence; and they remain proposals on paper, lacking the extraction infrastructure required for adoption at scale. We present \EvalCards{}, an operational reporting layer that composes benchmark metadata, evaluation run data, and model metadata into a unified record. We (1) derive a reporting schema from a structured review of 52 papers and 10 stakeholder interviews, (2) implement four interpretive signals (reproducibility, documentation completeness, provenance and risk, and score comparability), rendered through reader modes calibrated to research and non-research audiences, and (3) deploy a monitoring tool that applies \EvalCards{} across 5,816 models, 635 benchmarks, and 101,843 results, surfacing systematic gaps in current reporting practice.
Bias Analysis in Unconditional Image Generative Models
Jun 10, 2025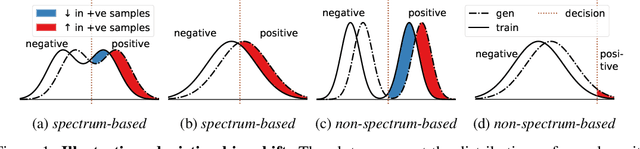
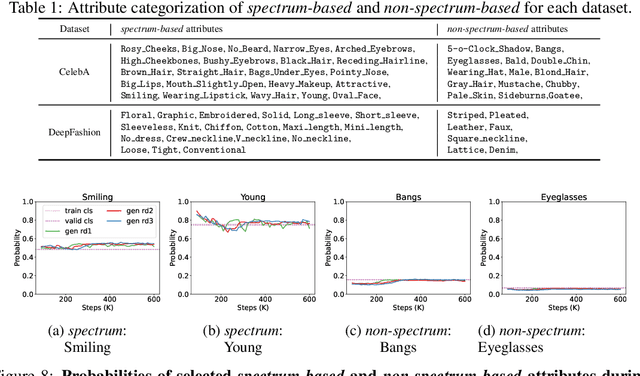
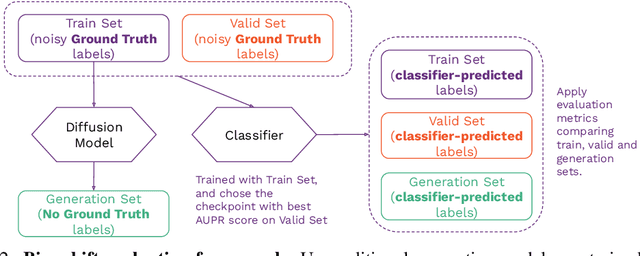
The widespread adoption of generative AI models has raised growing concerns about representational harm and potential discriminatory outcomes. Yet, despite growing literature on this topic, the mechanisms by which bias emerges - especially in unconditional generation - remain disentangled. We define the bias of an attribute as the difference between the probability of its presence in the observed distribution and its expected proportion in an ideal reference distribution. In our analysis, we train a set of unconditional image generative models and adopt a commonly used bias evaluation framework to study bias shift between training and generated distributions. Our experiments reveal that the detected attribute shifts are small. We find that the attribute shifts are sensitive to the attribute classifier used to label generated images in the evaluation framework, particularly when its decision boundaries fall in high-density regions. Our empirical analysis indicates that this classifier sensitivity is often observed in attributes values that lie on a spectrum, as opposed to exhibiting a binary nature. This highlights the need for more representative labeling practices, understanding the shortcomings through greater scrutiny of evaluation frameworks, and recognizing the socially complex nature of attributes when evaluating bias.
Alberta Wells Dataset: Pinpointing Oil and Gas Wells from Satellite Imagery
Oct 11, 2024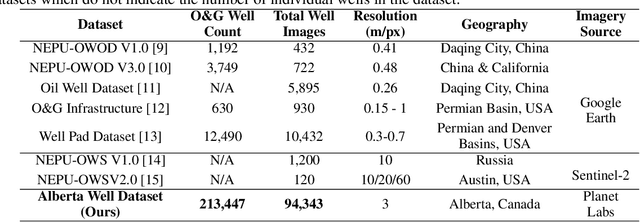
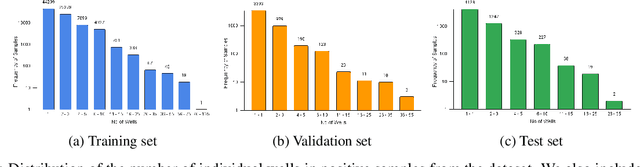

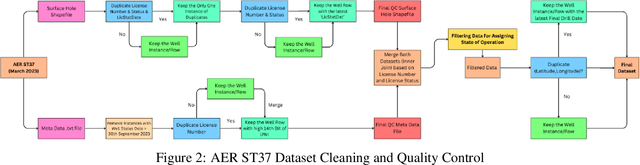
Millions of abandoned oil and gas wells are scattered across the world, leaching methane into the atmosphere and toxic compounds into the groundwater. Many of these locations are unknown, preventing the wells from being plugged and their polluting effects averted. Remote sensing is a relatively unexplored tool for pinpointing abandoned wells at scale. We introduce the first large-scale benchmark dataset for this problem, leveraging medium-resolution multi-spectral satellite imagery from Planet Labs. Our curated dataset comprises over 213,000 wells (abandoned, suspended, and active) from Alberta, a region with especially high well density, sourced from the Alberta Energy Regulator and verified by domain experts. We evaluate baseline algorithms for well detection and segmentation, showing the promise of computer vision approaches but also significant room for improvement.
Data-Centric Green AI: An Exploratory Empirical Study
Apr 07, 2022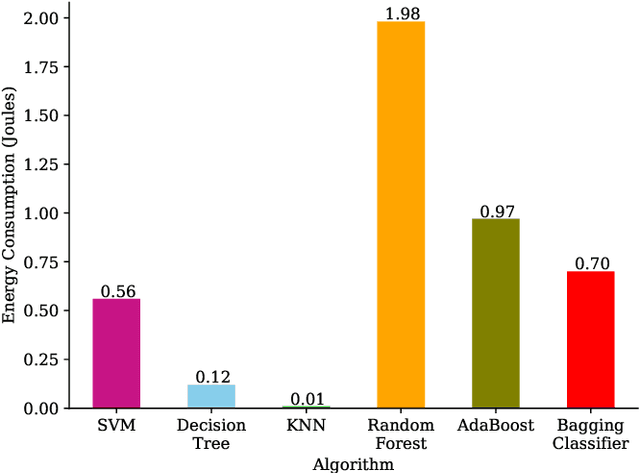
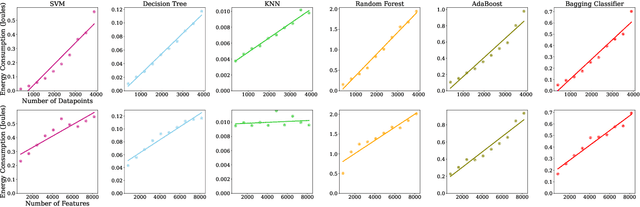
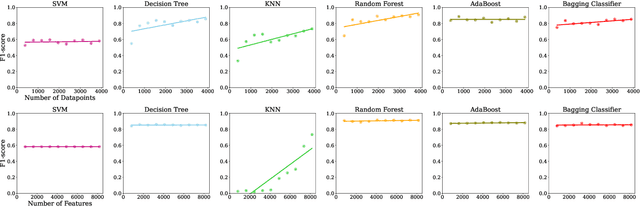
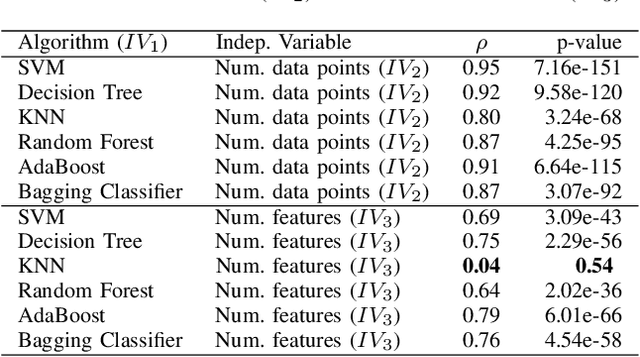
With the growing availability of large-scale datasets, and the popularization of affordable storage and computational capabilities, the energy consumed by AI is becoming a growing concern. To address this issue, in recent years, studies have focused on demonstrating how AI energy efficiency can be improved by tuning the model training strategy. Nevertheless, how modifications applied to datasets can impact the energy consumption of AI is still an open question. To fill this gap, in this exploratory study, we evaluate if data-centric approaches can be utilized to improve AI energy efficiency. To achieve our goal, we conduct an empirical experiment, executed by considering 6 different AI algorithms, a dataset comprising 5,574 data points, and two dataset modifications (number of data points and number of features). Our results show evidence that, by exclusively conducting modifications on datasets, energy consumption can be drastically reduced (up to 92.16%), often at the cost of a negligible or even absent accuracy decline. As additional introductory results, we demonstrate how, by exclusively changing the algorithm used, energy savings up to two orders of magnitude can be achieved. In conclusion, this exploratory investigation empirically demonstrates the importance of applying data-centric techniques to improve AI energy efficiency. Our results call for a research agenda that focuses on data-centric techniques, to further enable and democratize Green AI.