 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Project smells" -- Experiences in Analysing the Software Quality of ML Projects with mllint
Jan 20, 2022


Machine Learning (ML) projects incur novel challenges in their development and productionisation over traditional software applications, though established principles and best practices in ensuring the project's software quality still apply. While using static analysis to catch code smells has been shown to improve software quality attributes, it is only a small piece of the software quality puzzle, especially in the case of ML projects given their additional challenges and lower degree of Software Engineering (SE) experience in the data scientists that develop them. We introduce the novel concept of project smells which consider deficits in project management as a more holistic perspective on software quality in ML projects. An open-source static analysis tool mllint was also implemented to help detect and mitigate these. Our research evaluates this novel concept of project smells in the industrial context of ING, a global bank and large software- and data-intensive organisation. We also investigate the perceived importance of these project smells for proof-of-concept versus production-ready ML projects, as well as the perceived obstructions and benefits to using static analysis tools such as mllint. Our findings indicate a need for context-aware static analysis tools, that fit the needs of the project at its current stage of development, while requiring minimal configuration effort from the user.
The Prevalence of Code Smells in Machine Learning projects
Mar 06, 2021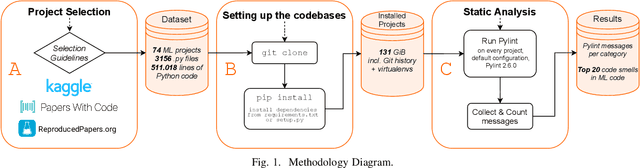


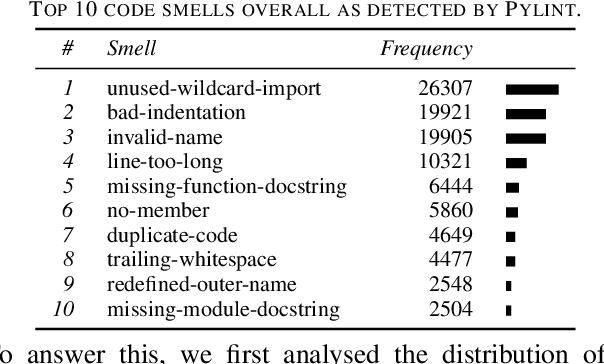
Artificial Intelligence (AI) and Machine Learning (ML) are pervasive in the current computer science landscape. Yet, there still exists a lack of software engineering experience and best practices in this field. One such best practice, static code analysis, can be used to find code smells, i.e., (potential) defects in the source code, refactoring opportunities, and violations of common coding standards. Our research set out to discover the most prevalent code smells in ML projects. We gathered a dataset of 74 open-source ML projects, installed their dependencies and ran Pylint on them. This resulted in a top 20 of all detected code smells, per category. Manual analysis of these smells mainly showed that code duplication is widespread and that the PEP8 convention for identifier naming style may not always be applicable to ML code due to its resemblance with mathematical notation. More interestingly, however, we found several major obstructions to the maintainability and reproducibility of ML projects, primarily related to the dependency management of Python projects. We also found that Pylint cannot reliably check for correct usage of imported dependencies, including prominent ML libraries such as PyTorch.