 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultivessel Coronary Artery Segmentation and Stenosis Localisation using Ensemble Learning
Oct 27, 2023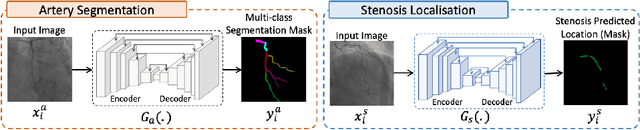
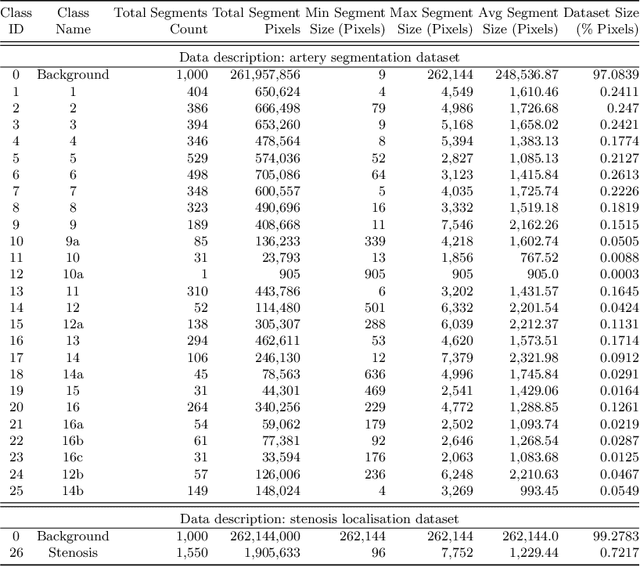

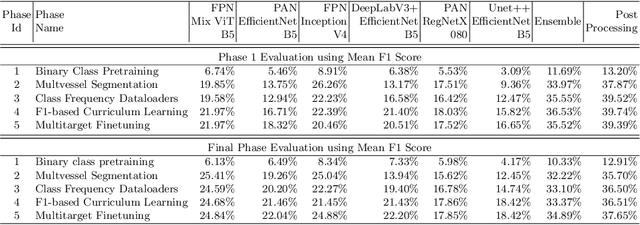
Coronary angiography analysis is a common clinical task performed by cardiologists to diagnose coronary artery disease (CAD) through an assessment of atherosclerotic plaque's accumulation. This study introduces an end-to-end machine learning solution developed as part of our solution for the MICCAI 2023 Automatic Region-based Coronary Artery Disease diagnostics using x-ray angiography imagEs (ARCADE) challenge, which aims to benchmark solutions for multivessel coronary artery segmentation and potential stenotic lesion localisation from X-ray coronary angiograms. We adopted a robust baseline model training strategy to progressively improve performance, comprising five successive stages of binary class pretraining, multivessel segmentation, fine-tuning using class frequency weighted dataloaders, fine-tuning using F1-based curriculum learning strategy (F1-CLS), and finally multi-target angiogram view classifier-based collective adaptation. Unlike many other medical imaging procedures, this task exhibits a notable degree of interobserver variability. %, making it particularly amenable to automated analysis. Our ensemble model combines the outputs from six baseline models using the weighted ensembling approach, which our analysis shows is found to double the predictive accuracy of the proposed solution. The final prediction was further refined, targeting the correction of misclassified blobs. Our solution achieved a mean F1 score of $37.69\%$ for coronary artery segmentation, and $39.41\%$ for stenosis localisation, positioning our team in the 5th position on both leaderboards. This work demonstrates the potential of automated tools to aid CAD diagnosis, guide interventions, and improve the accuracy of stent injections in clinical settings.
Robust Surgical Tools Detection in Endoscopic Videos with Noisy Data
Jul 03, 2023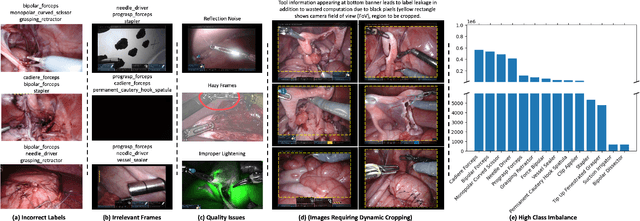
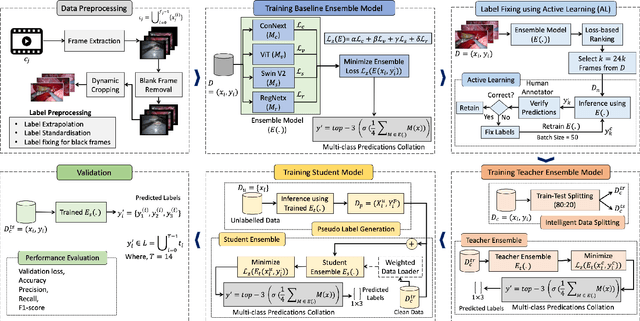
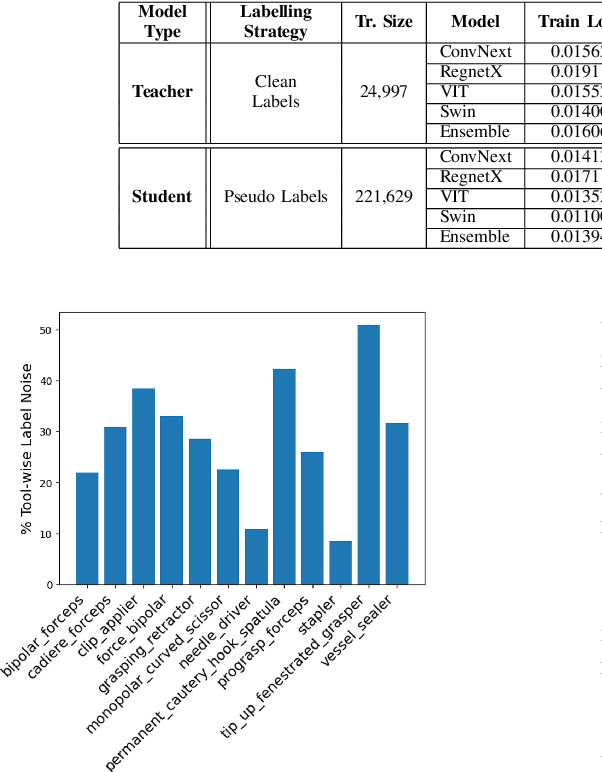
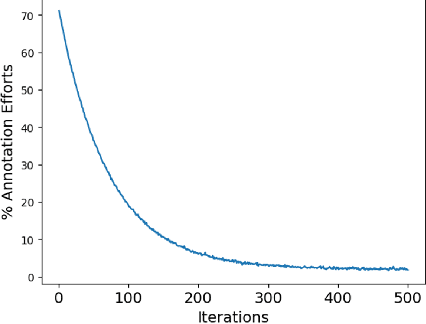
Over the past few years, surgical data science has attracted substantial interest from the machine learning (ML) community. Various studies have demonstrated the efficacy of emerging ML techniques in analysing surgical data, particularly recordings of procedures, for digitizing clinical and non-clinical functions like preoperative planning, context-aware decision-making, and operating skill assessment. However, this field is still in its infancy and lacks representative, well-annotated datasets for training robust models in intermediate ML tasks. Also, existing datasets suffer from inaccurate labels, hindering the development of reliable models. In this paper, we propose a systematic methodology for developing robust models for surgical tool detection using noisy data. Our methodology introduces two key innovations: (1) an intelligent active learning strategy for minimal dataset identification and label correction by human experts; and (2) an assembling strategy for a student-teacher model-based self-training framework to achieve the robust classification of 14 surgical tools in a semi-supervised fashion. Furthermore, we employ weighted data loaders to handle difficult class labels and address class imbalance issues. The proposed methodology achieves an average F1-score of 85.88\% for the ensemble model-based self-training with class weights, and 80.88\% without class weights for noisy labels. Also, our proposed method significantly outperforms existing approaches, which effectively demonstrates its effectiveness.