 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePathWISE: Multi-Agent Cancer Pathway Triaging Ontology Learning from Clinical Flowcharts
May 25, 2026Clinical pathways are disseminated as visual flowcharts where spatial topology, arrow direction, colour coding, and font weight encode critical triage logic that remains inaccessible to computational systems. We present PathWISE, a five-phase pipeline combining four LLM-based agents with a deterministic depth-first search auditor and a Java compiler critic, transforming these non-computable artefacts into validated, executable HL7 Clinical Quality Language (CQL) libraries deployable as FHIR CDS Hooks services. Purpose-built agents extract flowchart structure into a typed directed graph, perform deterministic path enumeration, conduct a structured semantic audit of every node's computability, generate terminology-constrained CQL definitions verified by the official Java CQL-to-ELM compiler, and produce routing logic covering 100% of enumerated patient journeys. Demonstrated across five UK NHS cancer pathways (colorectal, lung, skin, upper GI, and breast), PathWISE audits up to 183 nodes (182 under the Hybrid configuration), identifies 544 structured governance findings across four issue categories, achieves 100% syntactic compilation success, with UNCOMPUTABLE nodes receiving false placeholders that preserve compilability while surfacing governance gaps for clinical review, and produces zero hallucinated terminology codes for dictionary-covered concepts. Critically, PathWISE confines non-deterministic LLM inference to knowledge extraction while deterministic graph mathematics and a standard compiler underpin every verification step.
RAPTOR+: A Visually Grounded Vision-Language Framework to Improve Clinical Trust and Auditability in Automated Cancer Referral Processing
May 25, 2026Urgent suspected colorectal cancer (CRC) referrals create operational bottlenecks because semi-structured clinical documents often require manual review and transcription. The original RAPTOR system used Large Language Models for structured extraction but relied on a separate OCR stage, making it vulnerable to handwriting, layout variation, and loss of visual evidence linkage. We present RAPTOR+, a multimodal extension that uses Vision-Language Models (VLMs) for end-to-end referral understanding. We evaluate fine-tuned VLMs, commercial and open-source zero-shot VLMs, and the original OCR-based pipeline on 223 clinically curated CRC urgent referral forms. We also introduce a grounding-aware evaluation framework that measures both extraction accuracy and evidence localisation. Results show a clear grounding gap in zero-shot models. Gemini 2.5 Flash achieved 92.6% Reading Accuracy but only 1.2% Strict Safety. In contrast, fine-tuned Qwen3-VL-8B achieved 96.1% Reading Accuracy and 60.6% Strict Safety, substantially improving verifiable evidence grounding. These findings show that task-specific fine-tuning is essential for reliable, auditable clinical document understanding. RAPTOR+ enables extracted referral decisions to be linked to visual evidence, supporting safer and more efficient cancer referral triage.
Open Foundation Models in Healthcare: Challenges, Paradoxes, and Opportunities with GenAI Driven Personalized Prescription
Feb 04, 2025In response to the success of proprietary Large Language Models (LLMs) such as OpenAI's GPT-4, there is a growing interest in developing open, non-proprietary LLMs and AI foundation models (AIFMs) for transparent use in academic, scientific, and non-commercial applications. Despite their inability to match the refined functionalities of their proprietary counterparts, open models hold immense potential to revolutionize healthcare applications. In this paper, we examine the prospects of open-source LLMs and AIFMs for developing healthcare applications and make two key contributions. Firstly, we present a comprehensive survey of the current state-of-the-art open-source healthcare LLMs and AIFMs and introduce a taxonomy of these open AIFMs, categorizing their utility across various healthcare tasks. Secondly, to evaluate the general-purpose applications of open LLMs in healthcare, we present a case study on personalized prescriptions. This task is particularly significant due to its critical role in delivering tailored, patient-specific medications that can greatly improve treatment outcomes. In addition, we compare the performance of open-source models with proprietary models in settings with and without Retrieval-Augmented Generation (RAG). Our findings suggest that, although less refined, open LLMs can achieve performance comparable to proprietary models when paired with grounding techniques such as RAG. Furthermore, to highlight the clinical significance of LLMs-empowered personalized prescriptions, we perform subjective assessment through an expert clinician. We also elaborate on ethical considerations and potential risks associated with the misuse of powerful LLMs and AIFMs, highlighting the need for a cautious and responsible implementation in healthcare.
Multivessel Coronary Artery Segmentation and Stenosis Localisation using Ensemble Learning
Oct 27, 2023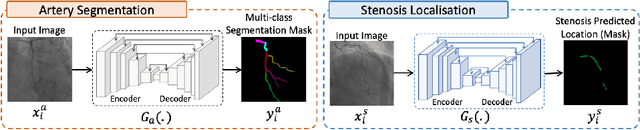
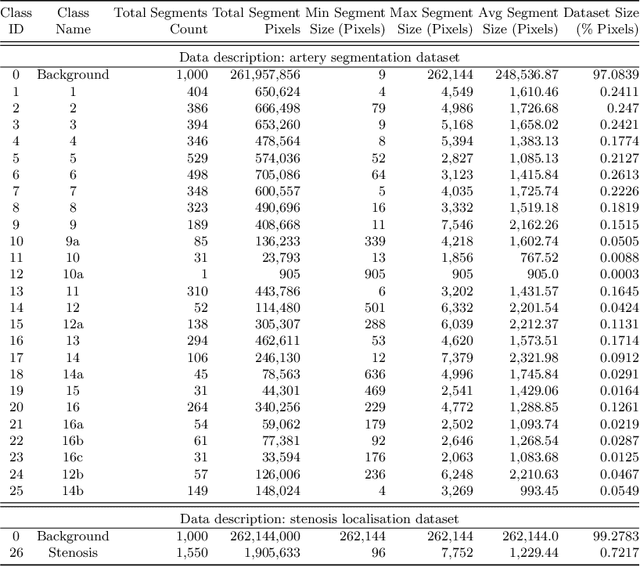

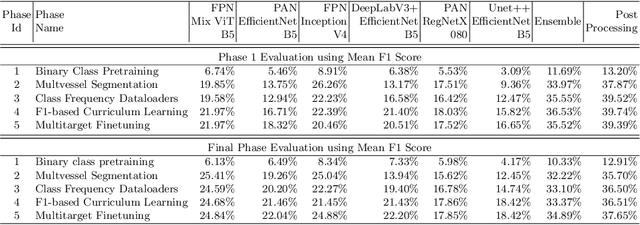
Coronary angiography analysis is a common clinical task performed by cardiologists to diagnose coronary artery disease (CAD) through an assessment of atherosclerotic plaque's accumulation. This study introduces an end-to-end machine learning solution developed as part of our solution for the MICCAI 2023 Automatic Region-based Coronary Artery Disease diagnostics using x-ray angiography imagEs (ARCADE) challenge, which aims to benchmark solutions for multivessel coronary artery segmentation and potential stenotic lesion localisation from X-ray coronary angiograms. We adopted a robust baseline model training strategy to progressively improve performance, comprising five successive stages of binary class pretraining, multivessel segmentation, fine-tuning using class frequency weighted dataloaders, fine-tuning using F1-based curriculum learning strategy (F1-CLS), and finally multi-target angiogram view classifier-based collective adaptation. Unlike many other medical imaging procedures, this task exhibits a notable degree of interobserver variability. %, making it particularly amenable to automated analysis. Our ensemble model combines the outputs from six baseline models using the weighted ensembling approach, which our analysis shows is found to double the predictive accuracy of the proposed solution. The final prediction was further refined, targeting the correction of misclassified blobs. Our solution achieved a mean F1 score of $37.69\%$ for coronary artery segmentation, and $39.41\%$ for stenosis localisation, positioning our team in the 5th position on both leaderboards. This work demonstrates the potential of automated tools to aid CAD diagnosis, guide interventions, and improve the accuracy of stent injections in clinical settings.
Robust Surgical Tools Detection in Endoscopic Videos with Noisy Data
Jul 03, 2023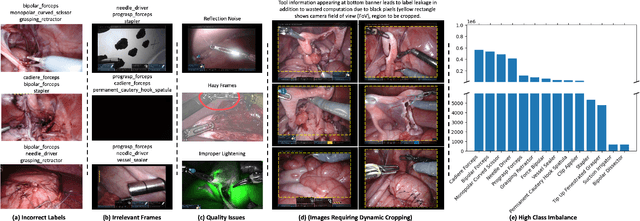
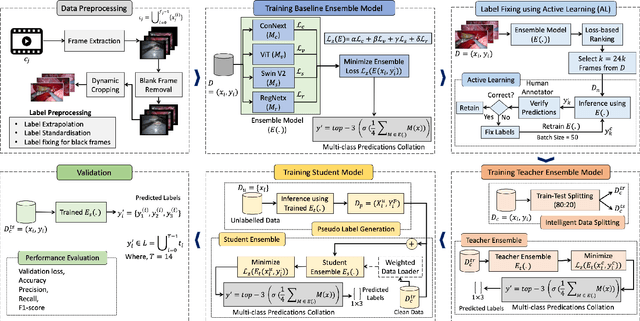
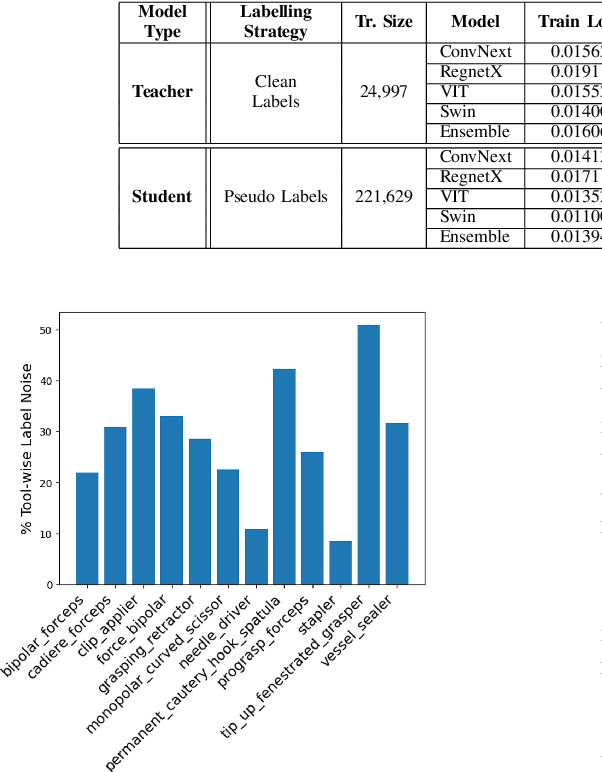
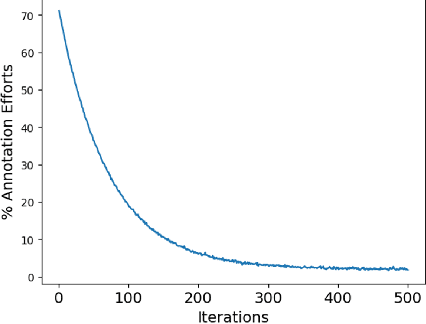
Over the past few years, surgical data science has attracted substantial interest from the machine learning (ML) community. Various studies have demonstrated the efficacy of emerging ML techniques in analysing surgical data, particularly recordings of procedures, for digitizing clinical and non-clinical functions like preoperative planning, context-aware decision-making, and operating skill assessment. However, this field is still in its infancy and lacks representative, well-annotated datasets for training robust models in intermediate ML tasks. Also, existing datasets suffer from inaccurate labels, hindering the development of reliable models. In this paper, we propose a systematic methodology for developing robust models for surgical tool detection using noisy data. Our methodology introduces two key innovations: (1) an intelligent active learning strategy for minimal dataset identification and label correction by human experts; and (2) an assembling strategy for a student-teacher model-based self-training framework to achieve the robust classification of 14 surgical tools in a semi-supervised fashion. Furthermore, we employ weighted data loaders to handle difficult class labels and address class imbalance issues. The proposed methodology achieves an average F1-score of 85.88\% for the ensemble model-based self-training with class weights, and 80.88\% without class weights for noisy labels. Also, our proposed method significantly outperforms existing approaches, which effectively demonstrates its effectiveness.