 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSystimator: A Design Space Exploration Methodology for Systolic Array based CNNs Acceleration on the FPGA-based Edge Nodes
Dec 15, 2018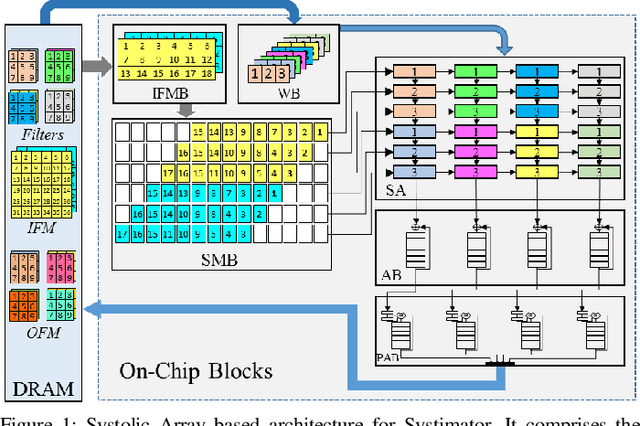
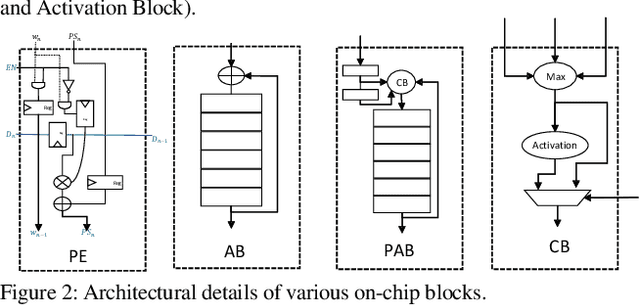
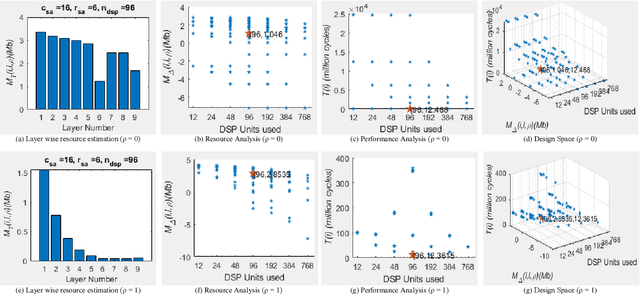
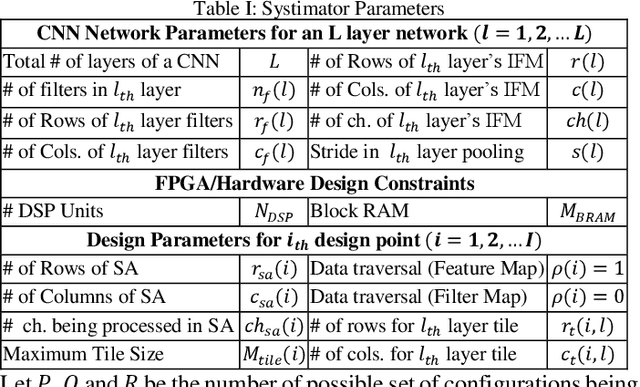
The evolution of IoT based smart applications demand porting of artificial intelligence algorithms to the edge computing devices. CNNs form a large part of these AI algorithms. Systolic array based CNN acceleration is being widely advocated due its ability to allow scalable architectures. However, CNNs are inherently memory and compute intensive algorithms, and hence pose significant challenges to be implemented on the resource-constrained edge computing devices. Memory-constrained low-cost FPGA based devices form a substantial fraction of these edge computing devices. Thus, when porting to such edge-computing devices, the designer is left unguided as to how to select a suitable systolic array configuration that could fit in the available hardware resources. In this paper we propose Systimator, a design space exploration based methodology that provides a set of design points that can be mapped within the memory bounds of the target FPGA device. The methodology is based upon an analytical model that is formulated to estimate the required resources for systolic arrays, assuming multiple data reuse patterns. The methodology further provides the performance estimates for each of the candidate design points. We show that Systimator provides an in-depth analysis of resource-requirement of systolic array based CNNs. We provide our resource estimation results for porting of convolutional layers of TINY YOLO, a CNN based object detector, on a Xilinx ARTIX 7 FPGA.
MPNA: A Massively-Parallel Neural Array Accelerator with Dataflow Optimization for Convolutional Neural Networks
Oct 30, 2018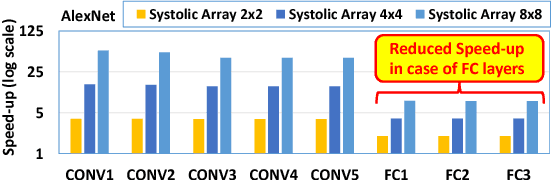


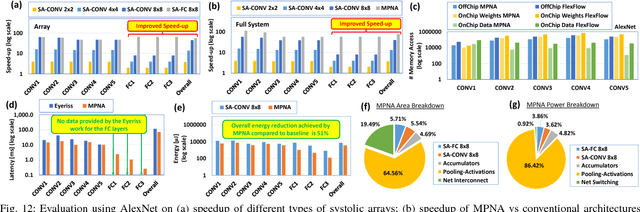
The state-of-the-art accelerators for Convolutional Neural Networks (CNNs) typically focus on accelerating only the convolutional layers, but do not prioritize the fully-connected layers much. Hence, they lack a synergistic optimization of the hardware architecture and diverse dataflows for the complete CNN design, which can provide a higher potential for performance/energy efficiency. Towards this, we propose a novel Massively-Parallel Neural Array (MPNA) accelerator that integrates two heterogeneous systolic arrays and respective highly-optimized dataflow patterns to jointly accelerate both the convolutional (CONV) and the fully-connected (FC) layers. Besides fully-exploiting the available off-chip memory bandwidth, these optimized dataflows enable high data-reuse of all the data types (i.e., weights, input and output activations), and thereby enable our MPNA to achieve high energy savings. We synthesized our MPNA architecture using the ASIC design flow for a 28nm technology, and performed functional and timing validation using multiple real-world complex CNNs. MPNA achieves 149.7GOPS/W at 280MHz and consumes 239mW. Experimental results show that our MPNA architecture provides 1.7x overall performance improvement compared to state-of-the-art accelerator, and 51% energy saving compared to the baseline architecture.