 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTLAC: Two-stage LMM Augmented CLIP for Zero-Shot Classification
Mar 15, 2025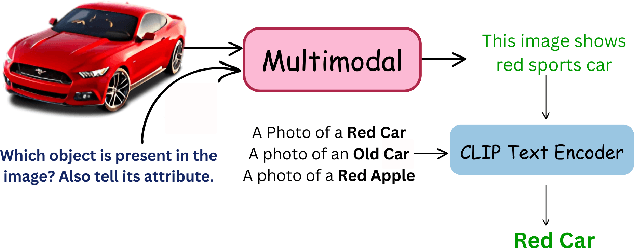
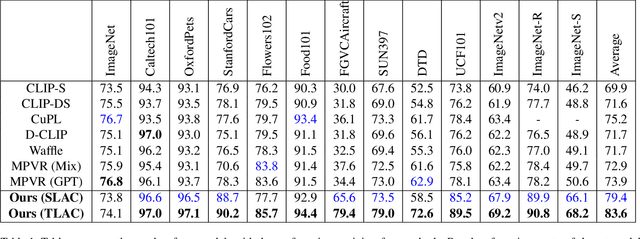
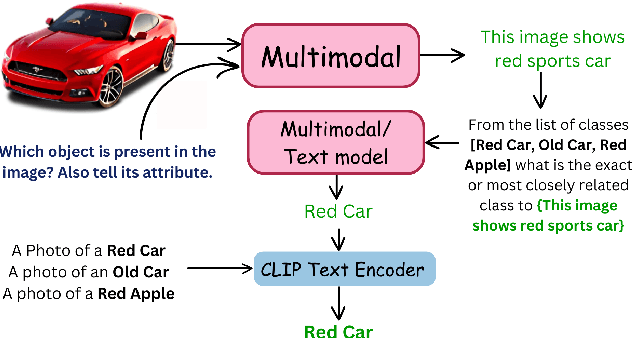
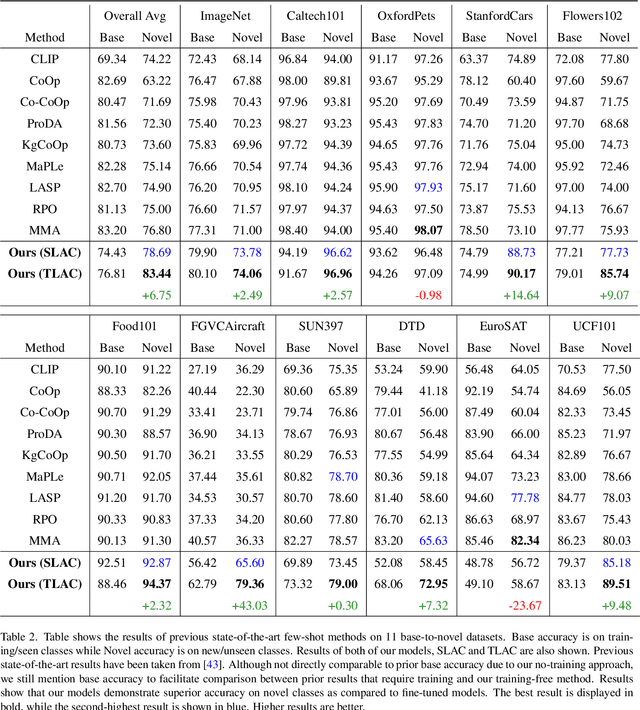
Contrastive Language-Image Pretraining (CLIP) has shown impressive zero-shot performance on image classification. However, state-of-the-art methods often rely on fine-tuning techniques like prompt learning and adapter-based tuning to optimize CLIP's performance. The necessity for fine-tuning significantly limits CLIP's adaptability to novel datasets and domains. This requirement mandates substantial time and computational resources for each new dataset. To overcome this limitation, we introduce simple yet effective training-free approaches, Single-stage LMM Augmented CLIP (SLAC) and Two-stage LMM Augmented CLIP (TLAC), that leverages powerful Large Multimodal Models (LMMs), such as Gemini, for image classification. The proposed methods leverages the capabilities of pre-trained LMMs, allowing for seamless adaptation to diverse datasets and domains without the need for additional training. Our approaches involve prompting the LMM to identify objects within an image. Subsequently, the CLIP text encoder determines the image class by identifying the dataset class with the highest semantic similarity to the LLM predicted object. We evaluated our models on 11 base-to-novel datasets and they achieved superior accuracy on 9 of these, including benchmarks like ImageNet, SUN397 and Caltech101, while maintaining a strictly training-free paradigm. Our overall accuracy of 83.44% surpasses the previous state-of-the-art few-shot methods by a margin of 6.75%. Our method achieved 83.6% average accuracy across 13 datasets, a 9.7% improvement over the previous 73.9% state-of-the-art for training-free approaches. Our method improves domain generalization, with a 3.6% gain on ImageNetV2, 16.96% on ImageNet-S, and 12.59% on ImageNet-R, over prior few-shot methods.
Attention Based Simple Primitives for Open World Compositional Zero-Shot Learning
Jul 18, 2024



Compositional Zero-Shot Learning (CZSL) aims to predict unknown compositions made up of attribute and object pairs. Predicting compositions unseen during training is a challenging task. We are exploring Open World Compositional Zero-Shot Learning (OW-CZSL) in this study, where our test space encompasses all potential combinations of attributes and objects. Our approach involves utilizing the self-attention mechanism between attributes and objects to achieve better generalization from seen to unseen compositions. Utilizing a self-attention mechanism facilitates the model's ability to identify relationships between attribute and objects. The similarity between the self-attended textual and visual features is subsequently calculated to generate predictions during the inference phase. The potential test space may encompass implausible object-attribute combinations arising from unrestricted attribute-object pairings. To mitigate this issue, we leverage external knowledge from ConceptNet to restrict the test space to realistic compositions. Our proposed model, Attention-based Simple Primitives (ASP), demonstrates competitive performance, achieving results comparable to the state-of-the-art.