 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCascadedViT: Cascaded Chunk-FeedForward and Cascaded Group Attention Vision Transformer
Nov 18, 2025Vision Transformers (ViTs) have demonstrated remarkable performance across a range of computer vision tasks; however, their high computational, memory, and energy demands hinder deployment on resource-constrained platforms. In this paper, we propose \emph{Cascaded-ViT (CViT)}, a lightweight and compute-efficient vision transformer architecture featuring a novel feedforward network design called \emph{Cascaded-Chunk Feed Forward Network (CCFFN)}. By splitting input features, CCFFN improves parameter and FLOP efficiency without sacrificing accuracy. Experiments on ImageNet-1K show that our \emph{CViT-XL} model achieves 75.5\% Top-1 accuracy while reducing FLOPs by 15\% and energy consumption by 3.3\% compared to EfficientViT-M5. Across various model sizes, the CViT family consistently exhibits the lowest energy consumption, making it suitable for deployment on battery-constrained devices such as mobile phones and drones. Furthermore, when evaluated using a new metric called \emph{Accuracy-Per-FLOP (APF)}, which quantifies compute efficiency relative to accuracy, CViT models consistently achieve top-ranking efficiency. Particularly, CViT-L is 2.2\% more accurate than EfficientViT-M2 while having comparable APF scores.
TLAC: Two-stage LMM Augmented CLIP for Zero-Shot Classification
Mar 15, 2025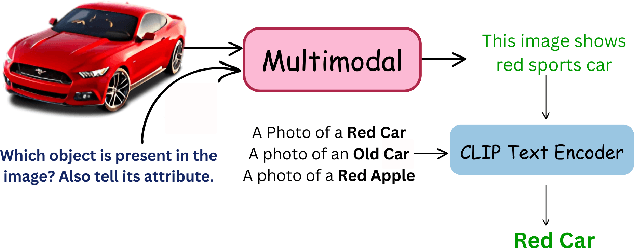
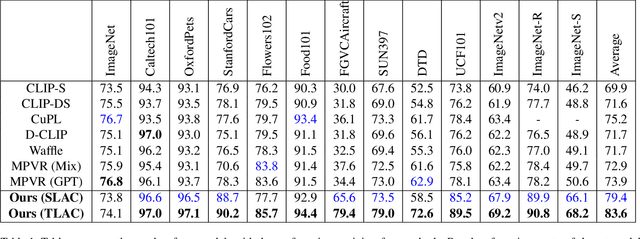
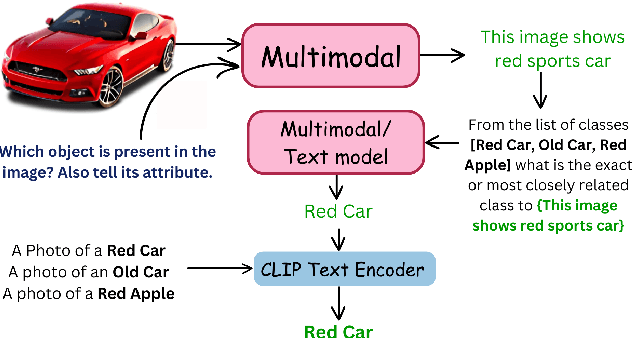
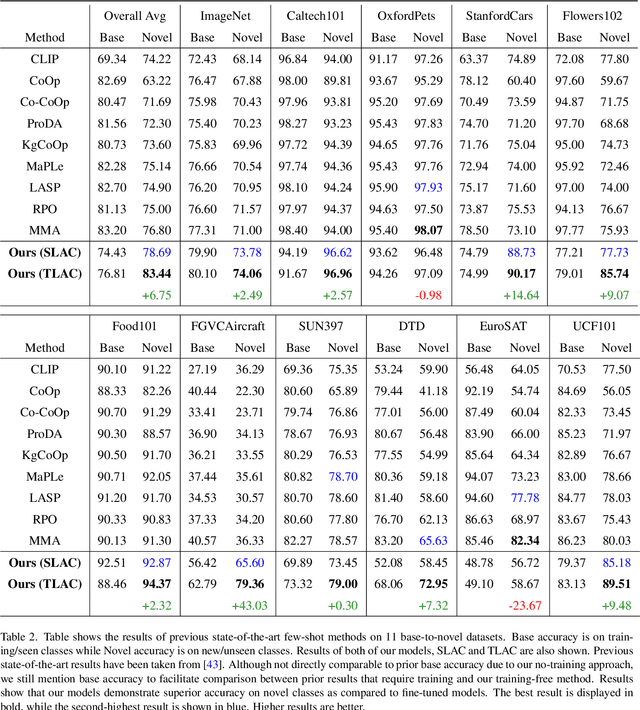
Contrastive Language-Image Pretraining (CLIP) has shown impressive zero-shot performance on image classification. However, state-of-the-art methods often rely on fine-tuning techniques like prompt learning and adapter-based tuning to optimize CLIP's performance. The necessity for fine-tuning significantly limits CLIP's adaptability to novel datasets and domains. This requirement mandates substantial time and computational resources for each new dataset. To overcome this limitation, we introduce simple yet effective training-free approaches, Single-stage LMM Augmented CLIP (SLAC) and Two-stage LMM Augmented CLIP (TLAC), that leverages powerful Large Multimodal Models (LMMs), such as Gemini, for image classification. The proposed methods leverages the capabilities of pre-trained LMMs, allowing for seamless adaptation to diverse datasets and domains without the need for additional training. Our approaches involve prompting the LMM to identify objects within an image. Subsequently, the CLIP text encoder determines the image class by identifying the dataset class with the highest semantic similarity to the LLM predicted object. We evaluated our models on 11 base-to-novel datasets and they achieved superior accuracy on 9 of these, including benchmarks like ImageNet, SUN397 and Caltech101, while maintaining a strictly training-free paradigm. Our overall accuracy of 83.44% surpasses the previous state-of-the-art few-shot methods by a margin of 6.75%. Our method achieved 83.6% average accuracy across 13 datasets, a 9.7% improvement over the previous 73.9% state-of-the-art for training-free approaches. Our method improves domain generalization, with a 3.6% gain on ImageNetV2, 16.96% on ImageNet-S, and 12.59% on ImageNet-R, over prior few-shot methods.
Attention Based Simple Primitives for Open World Compositional Zero-Shot Learning
Jul 18, 2024



Compositional Zero-Shot Learning (CZSL) aims to predict unknown compositions made up of attribute and object pairs. Predicting compositions unseen during training is a challenging task. We are exploring Open World Compositional Zero-Shot Learning (OW-CZSL) in this study, where our test space encompasses all potential combinations of attributes and objects. Our approach involves utilizing the self-attention mechanism between attributes and objects to achieve better generalization from seen to unseen compositions. Utilizing a self-attention mechanism facilitates the model's ability to identify relationships between attribute and objects. The similarity between the self-attended textual and visual features is subsequently calculated to generate predictions during the inference phase. The potential test space may encompass implausible object-attribute combinations arising from unrestricted attribute-object pairings. To mitigate this issue, we leverage external knowledge from ConceptNet to restrict the test space to realistic compositions. Our proposed model, Attention-based Simple Primitives (ASP), demonstrates competitive performance, achieving results comparable to the state-of-the-art.
Hyperspectral Image Compression Using Sampling and Implicit Neural Representations
Dec 04, 2023



Hyperspectral images, which record the electromagnetic spectrum for a pixel in the image of a scene, often store hundreds of channels per pixel and contain an order of magnitude more information than a similarly-sized RBG color image. Consequently, concomitant with the decreasing cost of capturing these images, there is a need to develop efficient techniques for storing, transmitting, and analyzing hyperspectral images. This paper develops a method for hyperspectral image compression using implicit neural representations where a multilayer perceptron network F with sinusoidal activation functions "learns" to map pixel locations to pixel intensities for a given hyperspectral image I. F thus acts as a compressed encoding of this image, and the original image is reconstructed by evaluating F at each pixel location. We use a sampling method with two factors: window size and sampling rate to reduce the compression time. We have evaluated our method on four benchmarks -- Indian Pines, Jasper Ridge, Pavia University, and Cuprite using PSNR and SSIM -- and we show that the proposed method achieves better compression than JPEG, JPEG2000, and PCA-DCT at low bitrates. Besides, we compare our results with the learning-based methods like PCA+JPEG2000, FPCA+JPEG2000, 3D DCT, 3D DWT+SVR, and WSRC and show the corresponding results in the "Compression Results" section. We also show that our methods with sampling achieve better speed and performance than our method without sampling.
SpACNN-LDVAE: Spatial Attention Convolutional Latent Dirichlet Variational Autoencoder for Hyperspectral Pixel Unmixing
Nov 17, 2023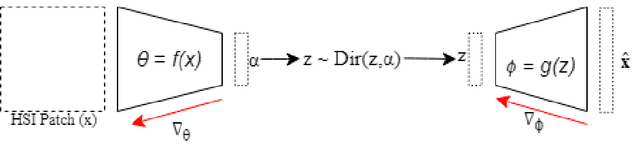
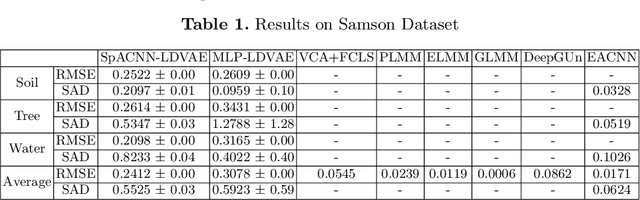
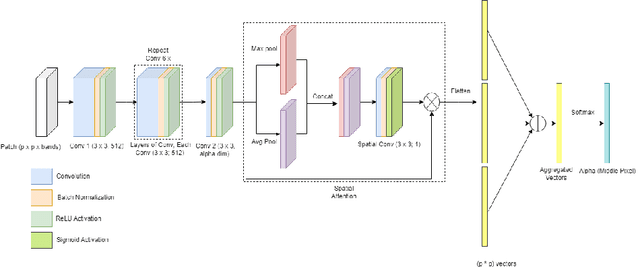
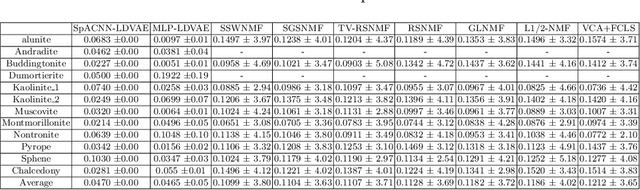
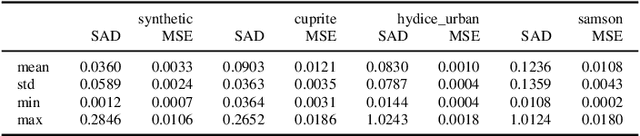
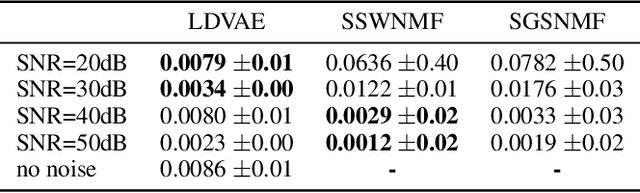
The Hyperspectral Unxming problem is to find the pure spectral signal of the underlying materials (endmembers) and their proportions (abundances). The proposed method builds upon the recently proposed method, Latent Dirichlet Variational Autoencoder (LDVAE). It assumes that abundances can be encoded as Dirichlet Distributions while mixed pixels and endmembers are represented by Multivariate Normal Distributions. However, LDVAE does not leverage spatial information present in an HSI; we propose an Isotropic CNN encoder with spatial attention to solve the hyperspectral unmixing problem. We evaluated our model on Samson, Hydice Urban, Cuprite, and OnTech-HSI-Syn-21 datasets. Our model also leverages the transfer learning paradigm for Cuprite Dataset, where we train the model on synthetic data and evaluate it on real-world data. We are able to observe the improvement in the results for the endmember extraction and abundance estimation by incorporating the spatial information. Code can be found at https://github.com/faisalqureshi/cnn-ldvae
Error Estimation for Single-Image Human Body Mesh Reconstruction
May 31, 2023Human pose and shape estimation methods continue to suffer in situations where one or more parts of the body are occluded. More importantly, these methods cannot express when their predicted pose is incorrect. This has serious consequences when these methods are used in human-robot interaction scenarios, where we need methods that can evaluate their predictions and flag situations where they might be wrong. This work studies this problem. We propose a method that combines information from OpenPose and SPIN -- two popular human pose and shape estimation methods -- to highlight regions on the predicted mesh that are least reliable. We have evaluated the proposed approach on 3DPW, 3DOH, and Human3.6M datasets, and the results demonstrate our model's effectiveness in identifying inaccurate regions of the human body mesh. Our code is available at https://github.com/Hamoon1987/meshConfidence.
Hyperspectral Image Compression Using Implicit Neural Representation
Feb 09, 2023



Hyperspectral images, which record the electromagnetic spectrum for a pixel in the image of a scene, often store hundreds of channels per pixel and contain an order of magnitude more information than a typical similarly-sized color image. Consequently, concomitant with the decreasing cost of capturing these images, there is a need to develop efficient techniques for storing, transmitting, and analyzing hyperspectral images. This paper develops a method for hyperspectral image compression using implicit neural representations where a multilayer perceptron network $\Phi_\theta$ with sinusoidal activation functions ``learns'' to map pixel locations to pixel intensities for a given hyperspectral image $I$. $\Phi_\theta$ thus acts as a compressed encoding of this image. The original image is reconstructed by evaluating $\Phi_\theta$ at each pixel location. We have evaluated our method on four benchmarks -- Indian Pines, Cuprite, Pavia University, and Jasper Ridge -- and we show the proposed method achieves better compression than JPEG, JPEG2000, and PCA-DCT at low bitrates.
Evaluation of Dirichlet Process Gaussian Mixtures for Segmentation on Noisy Hyperspectral Images
Mar 05, 2022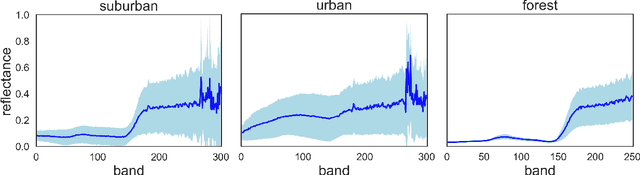



Image segmentation is a fundamental step for the interpretation of Remote Sensing Images. Clustering or segmentation methods usually precede the classification task and are used as support tools for manual labeling. The most common algorithms, such as k-means, mean-shift, and MRS, require an extra manual step to find the scale parameter. The segmentation results are severely affected if the parameters are not correctly tuned and diverge from the optimal values. Additionally, the search for the optimal scale is a costly task, as it requires a comprehensive hyper-parameter search. This paper proposes and evaluates a method for segmentation of Hyperspectral Images using the Dirichlet Process Gaussian Mixture Model. Our model can self-regulate the parameters until it finds the optimal values of scale and the number of clusters in a given dataset. The results demonstrate the potential of our method to find objects in a Hyperspectral Image while bypassing the burden of manual search of the optimal parameters. In addition, our model also produces similar results on noisy datasets, while previous research usually required a pre-processing task for noise reduction and spectral smoothing.
Hyperspectral Pixel Unmixing with Latent Dirichlet Variational Autoencoder
Mar 02, 2022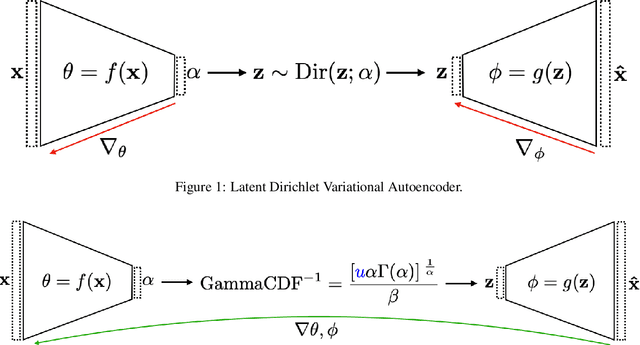
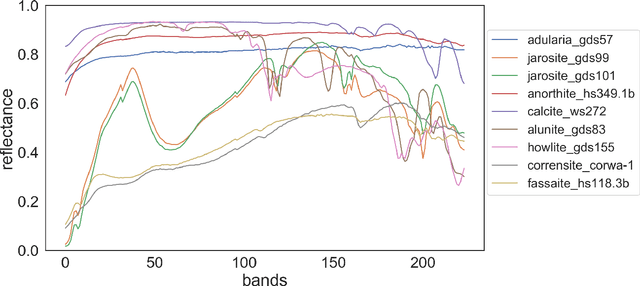
Hyperspectral pixel intensities result from a mixing of reflectances from several materials. This paper develops a method of hyperspectral pixel {\it unmixing} that aims to recover the "pure" spectral signal of each material (hereafter referred to as {\it endmembers}) together with the mixing ratios ({\it abundances}) given the spectrum of a single pixel. The unmixing problem is particularly relevant in the case of low-resolution hyperspectral images captured in a remote sensing setting, where individual pixels can cover large regions of the scene. Under the assumptions that (1) a multivariate Normal distribution can represent the spectra of an endmember and (2) a Dirichlet distribution can encode abundances of different endmembers, we develop a Latent Dirichlet Variational Autoencoder for hyperspectral pixel unmixing. Our approach achieves state-of-the-art results on standard benchmarks and on synthetic data generated using United States Geological Survey spectral library.
A study on the effects of compression on hyperspectral image classification
Apr 01, 2021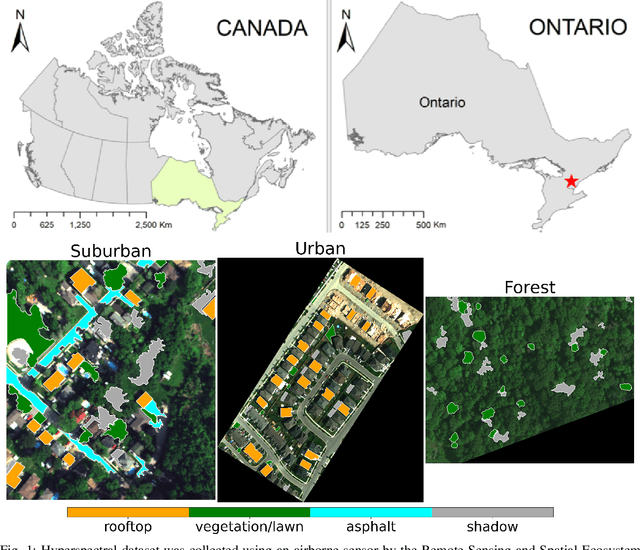
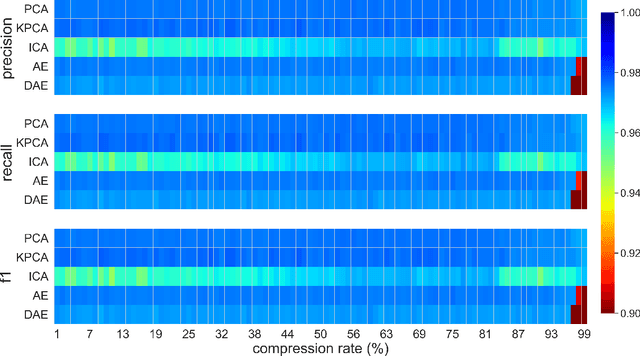
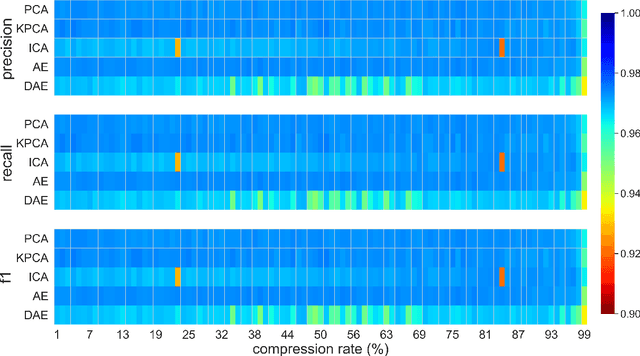
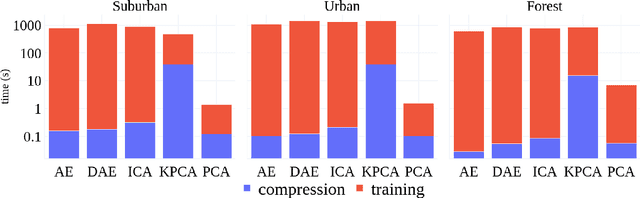
This paper presents a systematic study the effects of compression on hyperspectral pixel classification task. We use five dimensionality reduction methods -- PCA, KPCA, ICA, AE, and DAE -- to compress 301-dimensional hyperspectral pixels. Compressed pixels are subsequently used to perform pixel-based classifications. Pixel classification accuracies together with compression method, compression rates, and reconstruction errors provide a new lens to study the suitability of a compression method for the task of pixel-based classification. We use three high-resolution hyperspectral image datasets, representing three common landscape units (i.e. urban, transitional suburban, and forests) collected by the Remote Sensing and Spatial Ecosystem Modeling laboratory of the University of Toronto. We found that PCA, KPCA, and ICA post greater signal reconstruction capability; however, when compression rate is more than 90\% those methods showed lower classification scores. AE and DAE methods post better classification accuracy at 95\% compression rate, however decreasing again at 97\%, suggesting a sweet-spot at the 95\% mark. Our results demonstrate that the choice of a compression method with the compression rate are important considerations when designing a hyperspectral image classification pipeline.