 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-time Video Summarization on Commodity Hardware
Jan 26, 2019


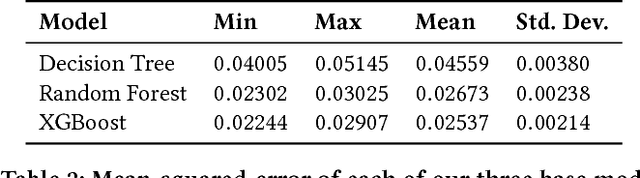
We present a method for creating video summaries in real-time on commodity hardware. Real-time here refers to the fact that the time required for video summarization is less than the duration of the input video. First, low-level features are use to discard undesirable frames. Next, video is divided into segments, and segment-level features are extracted for each segment. Tree-based models trained on widely available video summarization and computational aesthetics datasets are then used to rank individual segments, and top-ranked segments are selected to generate the final video summary. We evaluate the proposed method on SUMME dataset and show that our method is able to achieve summarization accuracy that is comparable to that of a current state-of-the-art deep learning method, while posting significantly faster run-times. Our method on average is able to generate a video summary in time that is shorter than the duration of the video.