 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiGAR: LiDAR-Guided Hierarchical Transformer for Multi-Modal Group Activity Recognition
Paper and Code
Oct 28, 2024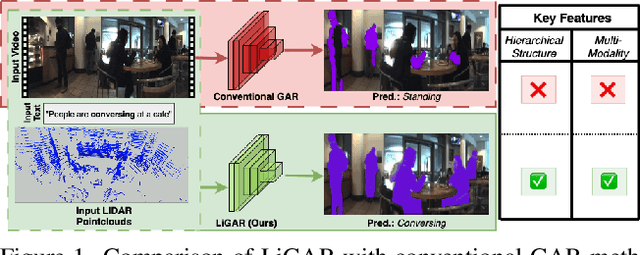
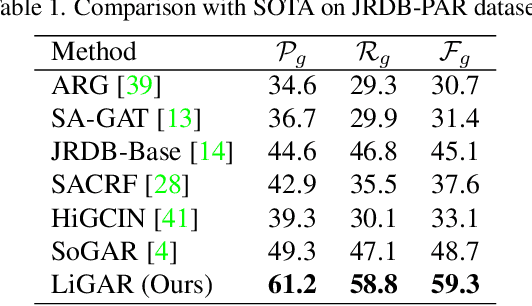
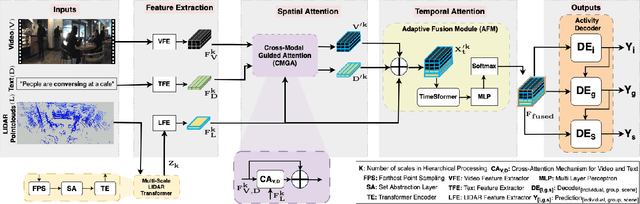
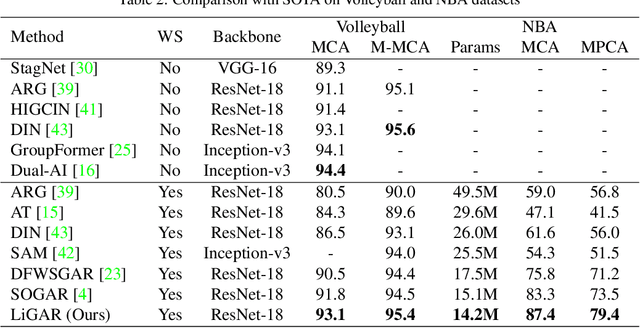
Group Activity Recognition (GAR) remains challenging in computer vision due to the complex nature of multi-agent interactions. This paper introduces LiGAR, a LIDAR-Guided Hierarchical Transformer for Multi-Modal Group Activity Recognition. LiGAR leverages LiDAR data as a structural backbone to guide the processing of visual and textual information, enabling robust handling of occlusions and complex spatial arrangements. Our framework incorporates a Multi-Scale LIDAR Transformer, Cross-Modal Guided Attention, and an Adaptive Fusion Module to integrate multi-modal data at different semantic levels effectively. LiGAR's hierarchical architecture captures group activities at various granularities, from individual actions to scene-level dynamics. Extensive experiments on the JRDB-PAR, Volleyball, and NBA datasets demonstrate LiGAR's superior performance, achieving state-of-the-art results with improvements of up to 10.6% in F1-score on JRDB-PAR and 5.9% in Mean Per Class Accuracy on the NBA dataset. Notably, LiGAR maintains high performance even when LiDAR data is unavailable during inference, showcasing its adaptability. Our ablation studies highlight the significant contributions of each component and the effectiveness of our multi-modal, multi-scale approach in advancing the field of group activity recognition.