 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEquiBim: Learning Symmetry-Equivariant Policy for Bimanual Manipulation
Mar 09, 2026Robotic imitation learning has achieved impressive success in learning complex manipulation behaviors from demonstrations. However, many existing robot learning methods do not explicitly account for the physical symmetries of robotic systems, often resulting in asymmetric or inconsistent behaviors under symmetric observations. This limitation is particularly pronounced in dual-arm manipulation, where bilateral symmetry is inherent to both the robot morphology and the structure of many tasks. In this paper, we introduce EquiBim, a symmetry-equivariant policy learning framework for bimanual manipulation that enforces bilateral equivariance between observations and actions during training. Our approach formulates physical symmetry as a group action on both observation and action spaces, and imposes an equivariance constraint on policy predictions under symmetric transformations. The framework is model-agnostic and can be seamlessly integrated into a wide range of imitation learning pipelines with diverse observation modalities and action representations, including point cloud-based and image-based policies, as well as both end-effector-space and joint-space parameterizations. We evaluate EquiBim on RoboTwin, a dual-arm robotic platform with symmetric kinematics, and evaluate it across diverse observation and action configurations in simulation. We further validate the approach on a real-world dual-arm system. Across both simulation and physical experiments, our method consistently improves performance and robustness under distribution shifts. These results suggest that explicitly enforcing physical symmetry provides a simple yet effective inductive bias for bimanual robot learning.
Joint Velocity-Growth Flow Matching for Single-Cell Dynamics Modeling
May 19, 2025
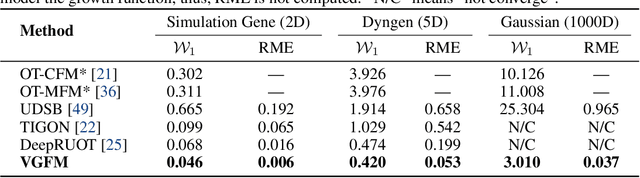


Learning the underlying dynamics of single cells from snapshot data has gained increasing attention in scientific and machine learning research. The destructive measurement technique and cell proliferation/death result in unpaired and unbalanced data between snapshots, making the learning of the underlying dynamics challenging. In this paper, we propose joint Velocity-Growth Flow Matching (VGFM), a novel paradigm that jointly learns state transition and mass growth of single-cell populations via flow matching. VGFM builds an ideal single-cell dynamics containing velocity of state and growth of mass, driven by a presented two-period dynamic understanding of the static semi-relaxed optimal transport, a mathematical tool that seeks the coupling between unpaired and unbalanced data. To enable practical usage, we approximate the ideal dynamics using neural networks, forming our joint velocity and growth matching framework. A distribution fitting loss is also employed in VGFM to further improve the fitting performance for snapshot data. Extensive experimental results on both synthetic and real datasets demonstrate that VGFM can capture the underlying biological dynamics accounting for mass and state variations over time, outperforming existing approaches for single-cell dynamics modeling.
ChicGrasp: Imitation-Learning based Customized Dual-Jaw Gripper Control for Delicate, Irregular Bio-products Manipulation
May 13, 2025



Automated poultry processing lines still rely on humans to lift slippery, easily bruised carcasses onto a shackle conveyor. Deformability, anatomical variance, and strict hygiene rules make conventional suction and scripted motions unreliable. We present ChicGrasp, an end--to--end hardware--software co-design for this task. An independently actuated dual-jaw pneumatic gripper clamps both chicken legs, while a conditional diffusion-policy controller, trained from only 50 multi--view teleoperation demonstrations (RGB + proprioception), plans 5 DoF end--effector motion, which includes jaw commands in one shot. On individually presented raw broiler carcasses, our system achieves a 40.6\% grasp--and--lift success rate and completes the pick to shackle cycle in 38 s, whereas state--of--the--art implicit behaviour cloning (IBC) and LSTM-GMM baselines fail entirely. All CAD, code, and datasets will be open-source. ChicGrasp shows that imitation learning can bridge the gap between rigid hardware and variable bio--products, offering a reproducible benchmark and a public dataset for researchers in agricultural engineering and robot learning.
Data-Driven Contact-Aware Control Method for Real-Time Deformable Tool Manipulation: A Case Study in the Environmental Swabbing
Mar 27, 2025



Deformable Object Manipulation (DOM) remains a critical challenge in robotics due to the complexities of developing suitable model-based control strategies. Deformable Tool Manipulation (DTM) further complicates this task by introducing additional uncertainties between the robot and its environment. While humans effortlessly manipulate deformable tools using touch and experience, robotic systems struggle to maintain stability and precision. To address these challenges, we present a novel State-Adaptive Koopman LQR (SA-KLQR) control framework for real-time deformable tool manipulation, demonstrated through a case study in environmental swab sampling for food safety. This method leverages Koopman operator-based control to linearize nonlinear dynamics while adapting to state-dependent variations in tool deformation and contact forces. A tactile-based feedback system dynamically estimates and regulates the swab tool's angle, contact pressure, and surface coverage, ensuring compliance with food safety standards. Additionally, a sensor-embedded contact pad monitors force distribution to mitigate tool pivoting and deformation, improving stability during dynamic interactions. Experimental results validate the SA-KLQR approach, demonstrating accurate contact angle estimation, robust trajectory tracking, and reliable force regulation. The proposed framework enhances precision, adaptability, and real-time control in deformable tool manipulation, bridging the gap between data-driven learning and optimal control in robotic interaction tasks.
Efficient Auto-Labeling of Large-Scale Poultry Datasets (ALPD) Using Semi-Supervised Models, Active Learning, and Prompt-then-Detect Approach
Jan 18, 2025



The rapid growth of AI in poultry farming has highlighted the challenge of efficiently labeling large, diverse datasets. Manual annotation is time-consuming, making it impractical for modern systems that continuously generate data. This study explores semi-supervised auto-labeling methods, integrating active learning, and prompt-then-detect paradigm to develop an efficient framework for auto-labeling of large poultry datasets aimed at advancing AI-driven behavior and health monitoring. Viideo data were collected from broilers and laying hens housed at the University of Arkansas and the University of Georgia. The collected videos were converted into images, pre-processed, augmented, and labeled. Various machine learning models, including zero-shot models like Grounding DINO, YOLO-World, and CLIP, and supervised models like YOLO and Faster-RCNN, were utilized for broilers, hens, and behavior detection. The results showed that YOLOv8s-World and YOLOv9s performed better when compared performance metrics for broiler and hen detection under supervised learning, while among the semi-supervised model, YOLOv8s-ALPD achieved the highest precision (96.1%) and recall (99.0%) with an RMSE of 1.9. The hybrid YOLO-World model, incorporating the optimal YOLOv8s backbone, demonstrated the highest overall performance. It achieved a precision of 99.2%, recall of 99.4%, and an F1 score of 98.7% for breed detection, alongside a precision of 88.4%, recall of 83.1%, and an F1 score of 84.5% for individual behavior detection. Additionally, semi-supervised models showed significant improvements in behavior detection, achieving up to 31% improvement in precision and 16% in F1-score. The semi-supervised models with minimal active learning reduced annotation time by over 80% compared to full manual labeling. Moreover, integrating zero-shot models enhanced detection and behavior identification.
Neural Network Architecture Search Enabled Wide-Deep Learning (NAS-WD) for Spatially Heterogenous Property Awared Chicken Woody Breast Classification and Hardness Regression
Sep 25, 2024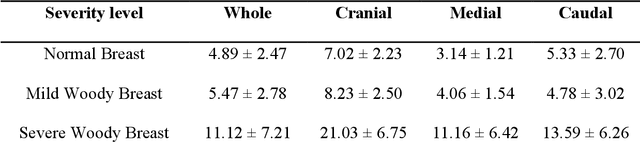
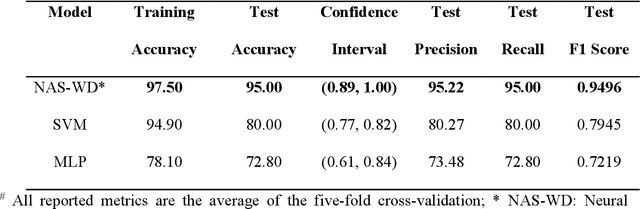
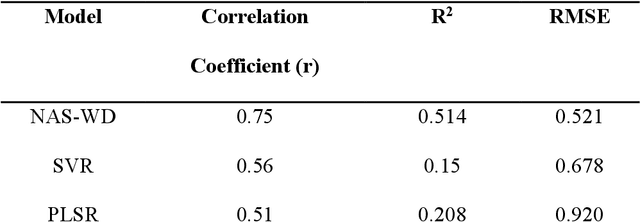
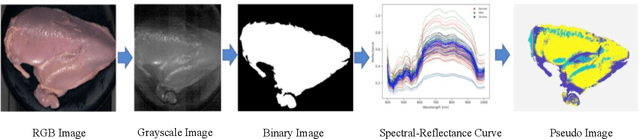
Due to intensive genetic selection for rapid growth rates and high broiler yields in recent years, the global poultry industry has faced a challenging problem in the form of woody breast (WB) conditions. This condition has caused significant economic losses as high as $200 million annually, and the root cause of WB has yet to be identified. Human palpation is the most common method of distinguishing a WB from others. However, this method is time-consuming and subjective. Hyperspectral imaging (HSI) combined with machine learning algorithms can evaluate the WB conditions of fillets in a non-invasive, objective, and high-throughput manner. In this study, 250 raw chicken breast fillet samples (normal, mild, severe) were taken, and spatially heterogeneous hardness distribution was first considered when designing HSI processing models. The study not only classified the WB levels from HSI but also built a regression model to correlate the spectral information with sample hardness data. To achieve a satisfactory classification and regression model, a neural network architecture search (NAS) enabled a wide-deep neural network model named NAS-WD, which was developed. In NAS-WD, NAS was first used to automatically optimize the network architecture and hyperparameters. The classification results show that NAS-WD can classify the three WB levels with an overall accuracy of 95%, outperforming the traditional machine learning model, and the regression correlation between the spectral data and hardness was 0.75, which performs significantly better than traditional regression models.
UniT: Unified Tactile Representation for Robot Learning
Aug 12, 2024



UniT is a novel approach to tactile representation learning, using VQVAE to learn a compact latent space and serve as the tactile representation. It uses tactile images obtained from a single simple object to train the representation with transferability and generalizability. This tactile representation can be zero-shot transferred to various downstream tasks, including perception tasks and manipulation policy learning. Our benchmarking on an in-hand 3D pose estimation task shows that UniT outperforms existing visual and tactile representation learning methods. Additionally, UniT's effectiveness in policy learning is demonstrated across three real-world tasks involving diverse manipulated objects and complex robot-object-environment interactions. Through extensive experimentation, UniT is shown to be a simple-to-train, plug-and-play, yet widely effective method for tactile representation learning. For more details, please refer to our open-source repository https://github.com/ZhengtongXu/UniT and the project website https://zhengtongxu.github.io/unifiedtactile.github.io/.
EAGLE: Efficient Adaptive Geometry-based Learning in Cross-view Understanding
Jun 03, 2024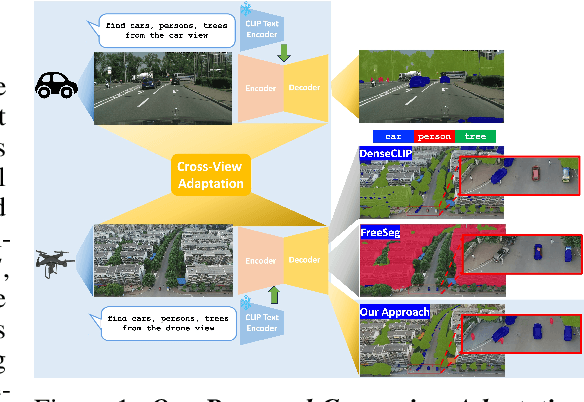
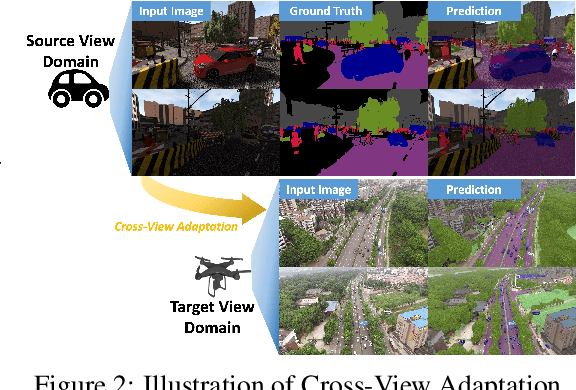
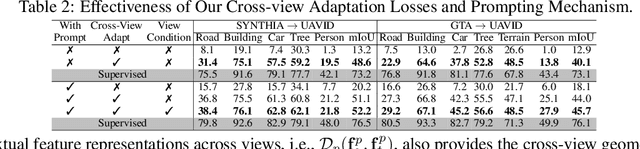
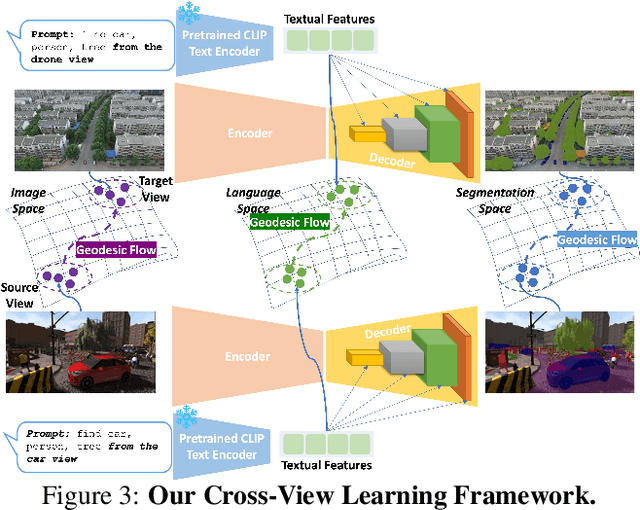
Unsupervised Domain Adaptation has been an efficient approach to transferring the semantic segmentation model across data distributions. Meanwhile, the recent Open-vocabulary Semantic Scene understanding based on large-scale vision language models is effective in open-set settings because it can learn diverse concepts and categories. However, these prior methods fail to generalize across different camera views due to the lack of cross-view geometric modeling. At present, there are limited studies analyzing cross-view learning. To address this problem, we introduce a novel Unsupervised Cross-view Adaptation Learning approach to modeling the geometric structural change across views in Semantic Scene Understanding. First, we introduce a novel Cross-view Geometric Constraint on Unpaired Data to model structural changes in images and segmentation masks across cameras. Second, we present a new Geodesic Flow-based Correlation Metric to efficiently measure the geometric structural changes across camera views. Third, we introduce a novel view-condition prompting mechanism to enhance the view-information modeling of the open-vocabulary segmentation network in cross-view adaptation learning. The experiments on different cross-view adaptation benchmarks have shown the effectiveness of our approach in cross-view modeling, demonstrating that we achieve State-of-the-Art (SOTA) performance compared to prior unsupervised domain adaptation and open-vocabulary semantic segmentation methods.
MEMO: Dataset and Methods for Robust Multimodal Retinal Image Registration with Large or Small Vessel Density Differences
Sep 25, 2023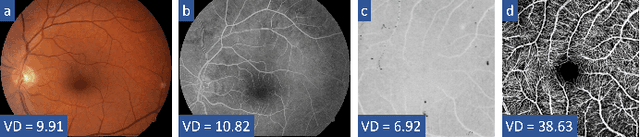
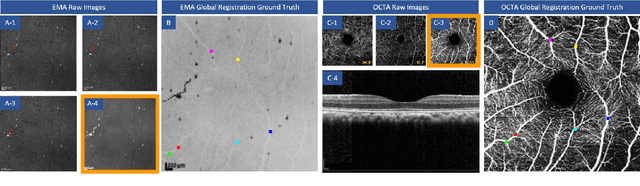
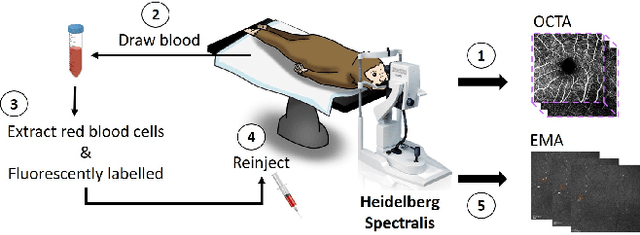
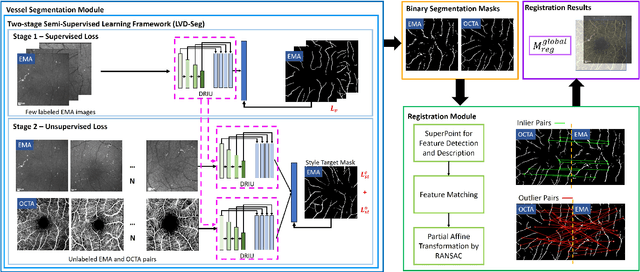
The measurement of retinal blood flow (RBF) in capillaries can provide a powerful biomarker for the early diagnosis and treatment of ocular diseases. However, no single modality can determine capillary flowrates with high precision. Combining erythrocyte-mediated angiography (EMA) with optical coherence tomography angiography (OCTA) has the potential to achieve this goal, as EMA can measure the absolute 2D RBF of retinal microvasculature and OCTA can provide the 3D structural images of capillaries. However, multimodal retinal image registration between these two modalities remains largely unexplored. To fill this gap, we establish MEMO, the first public multimodal EMA and OCTA retinal image dataset. A unique challenge in multimodal retinal image registration between these modalities is the relatively large difference in vessel density (VD). To address this challenge, we propose a segmentation-based deep-learning framework (VDD-Reg) and a new evaluation metric (MSD), which provide robust results despite differences in vessel density. VDD-Reg consists of a vessel segmentation module and a registration module. To train the vessel segmentation module, we further designed a two-stage semi-supervised learning framework (LVD-Seg) combining supervised and unsupervised losses. We demonstrate that VDD-Reg outperforms baseline methods quantitatively and qualitatively for cases of both small VD differences (using the CF-FA dataset) and large VD differences (using our MEMO dataset). Moreover, VDD-Reg requires as few as three annotated vessel segmentation masks to maintain its accuracy, demonstrating its feasibility.
A novel illumination condition varied image dataset-Food Vision Dataset (FVD) for fair and reliable consumer acceptability predictions from food
Sep 14, 2022


Recent advances in artificial intelligence promote a wide range of computer vision applications in many different domains. Digital cameras, acting as human eyes, can perceive fundamental object properties, such as shapes and colors, and can be further used for conducting high-level tasks, such as image classification, and object detections. Human perceptions have been widely recognized as the ground truth for training and evaluating computer vision models. However, in some cases, humans can be deceived by what they have seen. Well-functioned human vision relies on stable external lighting while unnatural illumination would influence human perception of essential characteristics of goods. To evaluate the illumination effects on human and computer perceptions, the group presents a novel dataset, the Food Vision Dataset (FVD), to create an evaluation benchmark to quantify illumination effects, and to push forward developments of illumination estimation methods for fair and reliable consumer acceptability prediction from food appearances. FVD consists of 675 images captured under 3 different power and 5 different temperature settings every alternate day for five such days.