 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMEMO: Dataset and Methods for Robust Multimodal Retinal Image Registration with Large or Small Vessel Density Differences
Sep 25, 2023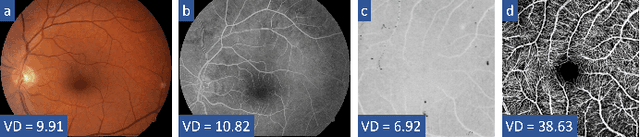
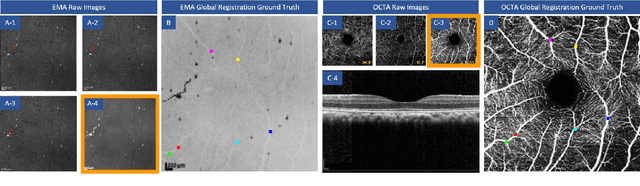
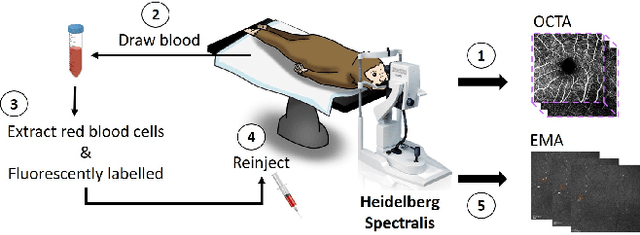
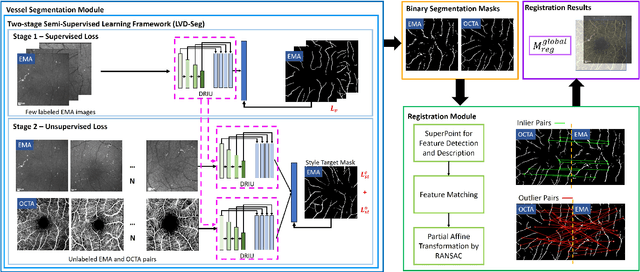
The measurement of retinal blood flow (RBF) in capillaries can provide a powerful biomarker for the early diagnosis and treatment of ocular diseases. However, no single modality can determine capillary flowrates with high precision. Combining erythrocyte-mediated angiography (EMA) with optical coherence tomography angiography (OCTA) has the potential to achieve this goal, as EMA can measure the absolute 2D RBF of retinal microvasculature and OCTA can provide the 3D structural images of capillaries. However, multimodal retinal image registration between these two modalities remains largely unexplored. To fill this gap, we establish MEMO, the first public multimodal EMA and OCTA retinal image dataset. A unique challenge in multimodal retinal image registration between these modalities is the relatively large difference in vessel density (VD). To address this challenge, we propose a segmentation-based deep-learning framework (VDD-Reg) and a new evaluation metric (MSD), which provide robust results despite differences in vessel density. VDD-Reg consists of a vessel segmentation module and a registration module. To train the vessel segmentation module, we further designed a two-stage semi-supervised learning framework (LVD-Seg) combining supervised and unsupervised losses. We demonstrate that VDD-Reg outperforms baseline methods quantitatively and qualitatively for cases of both small VD differences (using the CF-FA dataset) and large VD differences (using our MEMO dataset). Moreover, VDD-Reg requires as few as three annotated vessel segmentation masks to maintain its accuracy, demonstrating its feasibility.
Sketching the Expression: Flexible Rendering of Expressive Piano Performance with Self-Supervised Learning
Aug 31, 2022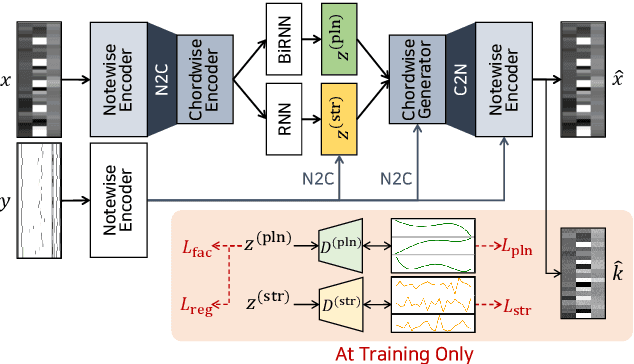
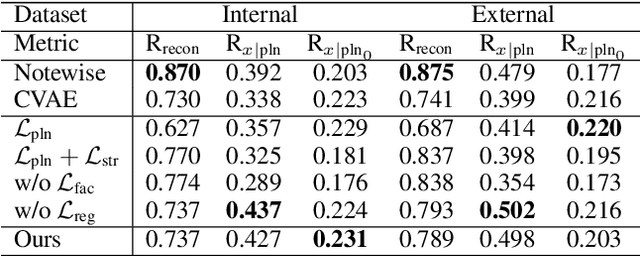
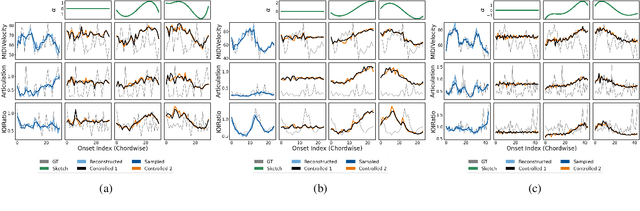
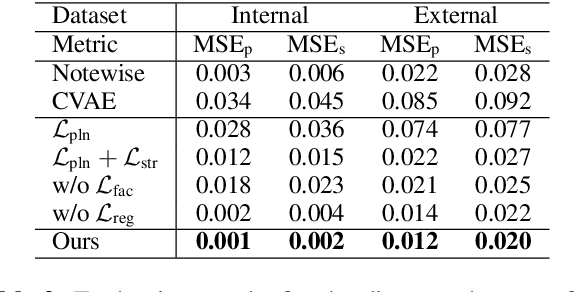
We propose a system for rendering a symbolic piano performance with flexible musical expression. It is necessary to actively control musical expression for creating a new music performance that conveys various emotions or nuances. However, previous approaches were limited to following the composer's guidelines of musical expression or dealing with only a part of the musical attributes. We aim to disentangle the entire musical expression and structural attribute of piano performance using a conditional VAE framework. It stochastically generates expressive parameters from latent representations and given note structures. In addition, we employ self-supervised approaches that force the latent variables to represent target attributes. Finally, we leverage a two-step encoder and decoder that learn hierarchical dependency to enhance the naturalness of the output. Experimental results show that our system can stably generate performance parameters relevant to the given musical scores, learn disentangled representations, and control musical attributes independently of each other.