 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Erythrocyte Detection and Tracking for Retinal Blood Flow Quantification in Erythrocyte-Mediated Angiography
May 31, 2026Capillary-level retinal blood flow (RBF) has strong potential as a biomarker for various ocular diseases. However, modalities for measuring capillary-level RBF remain limited. Erythrocyte-mediated angiography (EMA), an emerging imaging technique, enables capillary-level RBF measurement by visualizing individual erythrocytes, yet automated erythrocyte detection and tracking, which are essential for quantifying blood flow, remain largely unexplored. To address this gap, we propose EMTrack, a novel framework featuring a flow-context module for erythrocyte detection that distinguishes moving from paused cells and a topology-aware tracking strategy that enables tracking under large inter-frame displacements and substantial motion variations. In addition, we establish RBF-EMA, a new EMA dataset with comprehensive erythrocyte detection and tracking annotations. Experimental results demonstrate that our method outperforms baseline methods both quantitatively and qualitatively on detection and tracking tasks in the RBF-EMA dataset. Moreover, RBF quantification results highlight the strong potential of our framework for automated retinal blood flow measurement.
AutoComPose: Automatic Generation of Pose Transition Descriptions for Composed Pose Retrieval Using Multimodal LLMs
Mar 28, 2025



Composed pose retrieval (CPR) enables users to search for human poses by specifying a reference pose and a transition description, but progress in this field is hindered by the scarcity and inconsistency of annotated pose transitions. Existing CPR datasets rely on costly human annotations or heuristic-based rule generation, both of which limit scalability and diversity. In this work, we introduce AutoComPose, the first framework that leverages multimodal large language models (MLLMs) to automatically generate rich and structured pose transition descriptions. Our method enhances annotation quality by structuring transitions into fine-grained body part movements and introducing mirrored/swapped variations, while a cyclic consistency constraint ensures logical coherence between forward and reverse transitions. To advance CPR research, we construct and release two dedicated benchmarks, AIST-CPR and PoseFixCPR, supplementing prior datasets with enhanced attributes. Extensive experiments demonstrate that training retrieval models with AutoComPose yields superior performance over human-annotated and heuristic-based methods, significantly reducing annotation costs while improving retrieval quality. Our work pioneers the automatic annotation of pose transitions, establishing a scalable foundation for future CPR research.
SynPlay: Importing Real-world Diversity for a Synthetic Human Dataset
Aug 21, 2024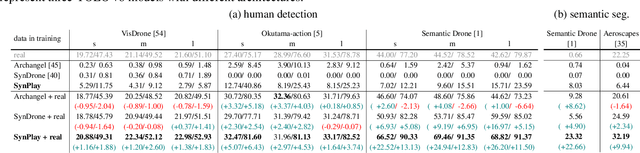



We introduce Synthetic Playground (SynPlay), a new synthetic human dataset that aims to bring out the diversity of human appearance in the real world. We focus on two factors to achieve a level of diversity that has not yet been seen in previous works: i) realistic human motions and poses and ii) multiple camera viewpoints towards human instances. We first use a game engine and its library-provided elementary motions to create games where virtual players can take less-constrained and natural movements while following the game rules (i.e., rule-guided motion design as opposed to detail-guided design). We then augment the elementary motions with real human motions captured with a motion capture device. To render various human appearances in the games from multiple viewpoints, we use seven virtual cameras encompassing the ground and aerial views, capturing abundant aerial-vs-ground and dynamic-vs-static attributes of the scene. Through extensive and carefully-designed experiments, we show that using SynPlay in model training leads to enhanced accuracy over existing synthetic datasets for human detection and segmentation. The benefit of SynPlay becomes even greater for tasks in the data-scarce regime, such as few-shot and cross-domain learning tasks. These results clearly demonstrate that SynPlay can be used as an essential dataset with rich attributes of complex human appearances and poses suitable for model pretraining. SynPlay dataset comprising over 73k images and 6.5M human instances, is available for download at https://synplaydataset.github.io/.
Exploring the Impact of Synthetic Data for Aerial-view Human Detection
May 27, 2024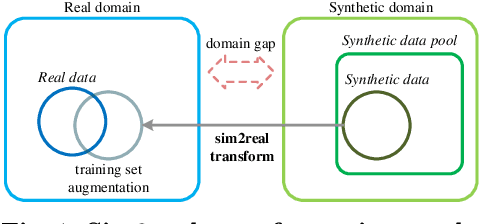

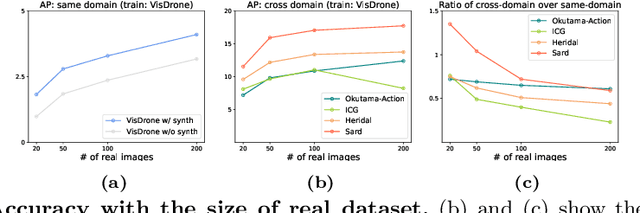
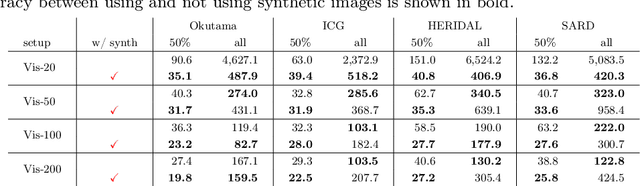
Aerial-view human detection has a large demand for large-scale data to capture more diverse human appearances compared to ground-view human detection. Therefore, synthetic data can be a good resource to expand data, but the domain gap with real-world data is the biggest obstacle to its use in training. As a common solution to deal with the domain gap, the sim2real transformation is used, and its quality is affected by three factors: i) the real data serving as a reference when calculating the domain gap, ii) the synthetic data chosen to avoid the transformation quality degradation, and iii) the synthetic data pool from which the synthetic data is selected. In this paper, we investigate the impact of these factors on maximizing the effectiveness of synthetic data in training in terms of improving learning performance and acquiring domain generalization ability--two main benefits expected of using synthetic data. As an evaluation metric for the second benefit, we introduce a method for measuring the distribution gap between two datasets, which is derived as the normalized sum of the Mahalanobis distances of all test data. As a result, we have discovered several important findings that have never been investigated or have been used previously without accurate understanding. We expect that these findings can break the current trend of either naively using or being hesitant to use synthetic data in machine learning due to the lack of understanding, leading to more appropriate use in future research.
Diversifying Human Pose in Synthetic Data for Aerial-view Human Detection
May 24, 2024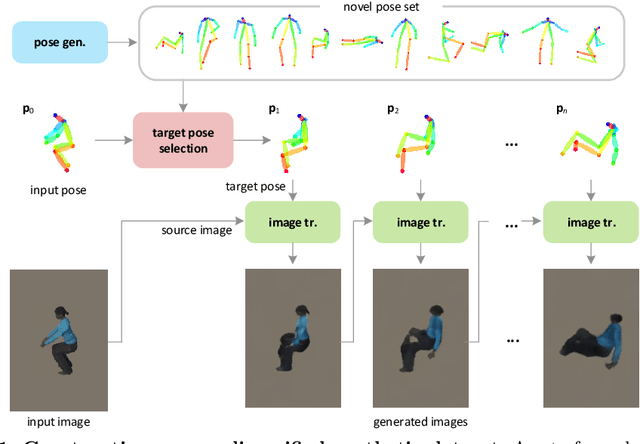
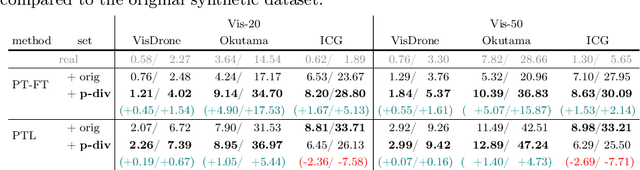


We present a framework for diversifying human poses in a synthetic dataset for aerial-view human detection. Our method firstly constructs a set of novel poses using a pose generator and then alters images in the existing synthetic dataset to assume the novel poses while maintaining the original style using an image translator. Since images corresponding to the novel poses are not available in training, the image translator is trained to be applicable only when the input and target poses are similar, thus training does not require the novel poses and their corresponding images. Next, we select a sequence of target novel poses from the novel pose set, using Dijkstra's algorithm to ensure that poses closer to each other are located adjacently in the sequence. Finally, we repeatedly apply the image translator to each target pose in sequence to produce a group of novel pose images representing a variety of different limited body movements from the source pose. Experiments demonstrate that, regardless of how the synthetic data is used for training or the data size, leveraging the pose-diversified synthetic dataset in training generally presents remarkably better accuracy than using the original synthetic dataset on three aerial-view human detection benchmarks (VisDrone, Okutama-Action, and ICG) in the few-shot regime.
MEMO: Dataset and Methods for Robust Multimodal Retinal Image Registration with Large or Small Vessel Density Differences
Sep 25, 2023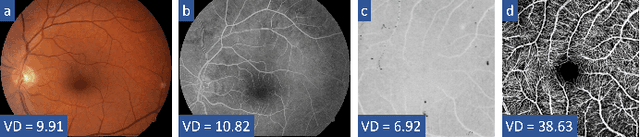
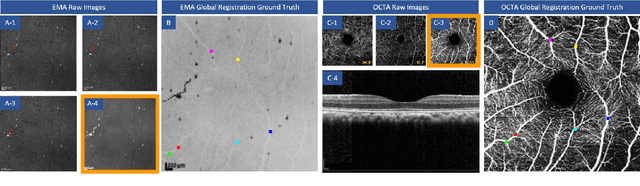
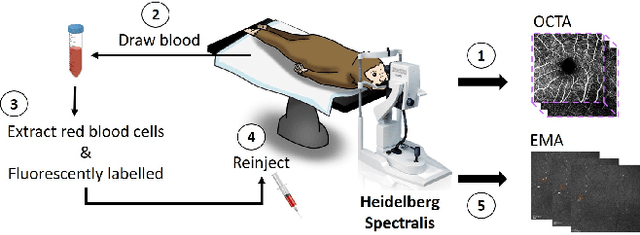
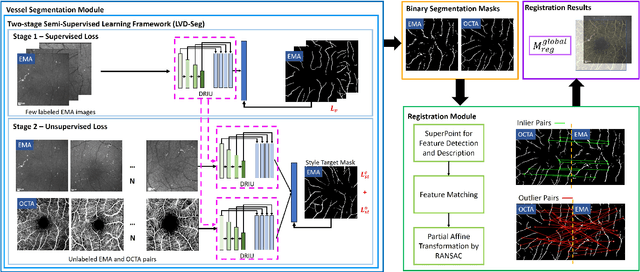
The measurement of retinal blood flow (RBF) in capillaries can provide a powerful biomarker for the early diagnosis and treatment of ocular diseases. However, no single modality can determine capillary flowrates with high precision. Combining erythrocyte-mediated angiography (EMA) with optical coherence tomography angiography (OCTA) has the potential to achieve this goal, as EMA can measure the absolute 2D RBF of retinal microvasculature and OCTA can provide the 3D structural images of capillaries. However, multimodal retinal image registration between these two modalities remains largely unexplored. To fill this gap, we establish MEMO, the first public multimodal EMA and OCTA retinal image dataset. A unique challenge in multimodal retinal image registration between these modalities is the relatively large difference in vessel density (VD). To address this challenge, we propose a segmentation-based deep-learning framework (VDD-Reg) and a new evaluation metric (MSD), which provide robust results despite differences in vessel density. VDD-Reg consists of a vessel segmentation module and a registration module. To train the vessel segmentation module, we further designed a two-stage semi-supervised learning framework (LVD-Seg) combining supervised and unsupervised losses. We demonstrate that VDD-Reg outperforms baseline methods quantitatively and qualitatively for cases of both small VD differences (using the CF-FA dataset) and large VD differences (using our MEMO dataset). Moreover, VDD-Reg requires as few as three annotated vessel segmentation masks to maintain its accuracy, demonstrating its feasibility.
Progressive Transformation Learning For Leveraging Virtual Images in Training
Nov 03, 2022To effectively interrogate UAV-based images for detecting objects of interest, such as humans, it is essential to acquire large-scale UAV-based datasets that include human instances with various poses captured from widely varying viewing angles. As a viable alternative to laborious and costly data curation, we introduce Progressive Transformation Learning (PTL), which gradually augments a training dataset by adding transformed virtual images with enhanced realism. Generally, a virtual2real transformation generator in the conditional GAN framework suffers from quality degradation when a large domain gap exists between real and virtual images. To deal with the domain gap, PTL takes a novel approach that progressively iterates the following three steps: 1) select a subset from a pool of virtual images according to the domain gap, 2) transform the selected virtual images to enhance realism, and 3) add the transformed virtual images to the training set while removing them from the pool. In PTL, accurately quantifying the domain gap is critical. To do that, we theoretically demonstrate that the feature representation space of a given object detector can be modeled as a multivariate Gaussian distribution from which the Mahalanobis distance between a virtual object and the Gaussian distribution of each object category in the representation space can be readily computed. Experiments show that PTL results in a substantial performance increase over the baseline, especially in the small data and the cross-domain regime.
What Synthesis is Missing: Depth Adaptation Integrated with Weak Supervision for Indoor Scene Parsing
Mar 23, 2019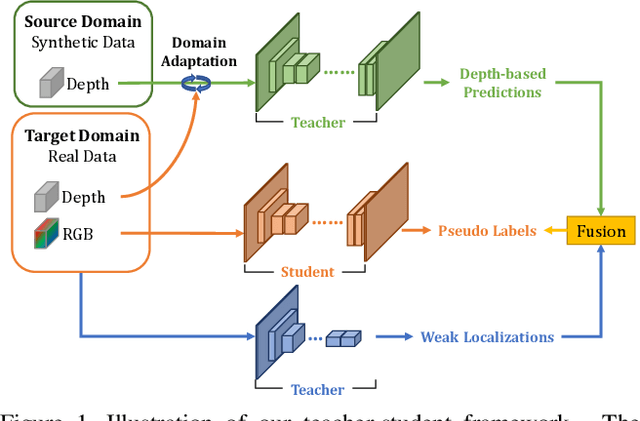

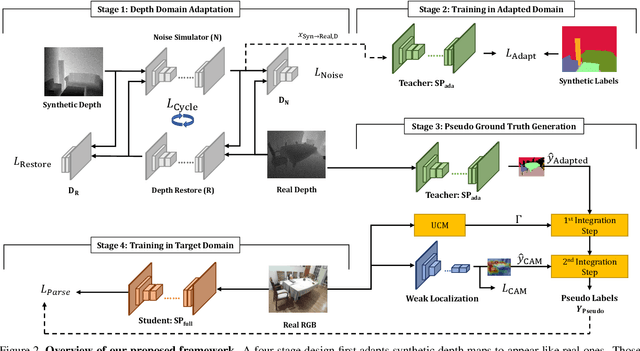
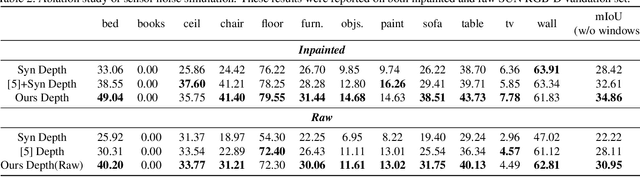
Scene Parsing is a crucial step to enable autonomous systems to understand and interact with their surroundings. Supervised deep learning methods have made great progress in solving scene parsing problems, however, come at the cost of laborious manual pixel-level annotation. To alleviate this effort synthetic data as well as weak supervision have both been investigated. Nonetheless, synthetically generated data still suffers from severe domain shift while weak labels are often imprecise. Moreover, most existing works for weakly supervised scene parsing are limited to salient foreground objects. The aim of this work is hence twofold: Exploit synthetic data where feasible and integrate weak supervision where necessary. More concretely, we address this goal by utilizing depth as transfer domain because its synthetic-to-real discrepancy is much lower than for color. At the same time, we perform weak localization from easily obtainable image level labels and integrate both using a novel contour-based scheme. Our approach is implemented as a teacher-student learning framework to solve the transfer learning problem by generating a pseudo ground truth. Using only depth-based adaptation, this approach already outperforms previous transfer learning approaches on the popular indoor scene parsing SUN RGB-D dataset. Our proposed two-stage integration more than halves the gap towards fully supervised methods when compared to previous state-of-the-art in transfer learning.