 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiversifying Human Pose in Synthetic Data for Aerial-view Human Detection
Paper and Code
May 24, 2024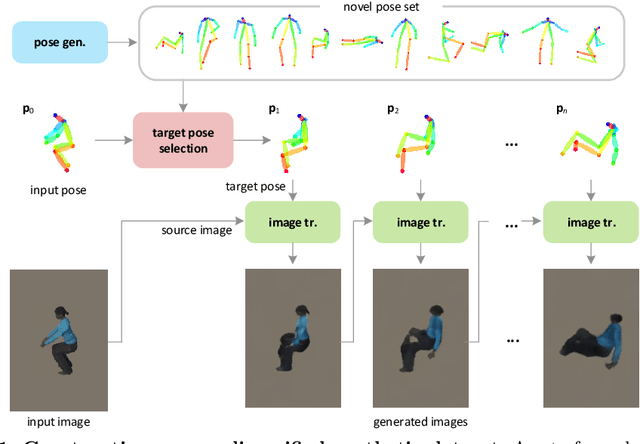
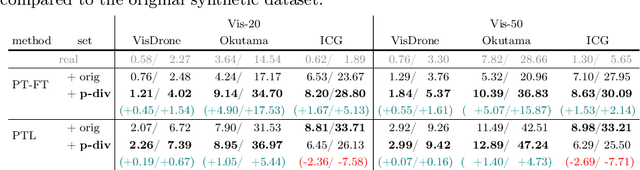


We present a framework for diversifying human poses in a synthetic dataset for aerial-view human detection. Our method firstly constructs a set of novel poses using a pose generator and then alters images in the existing synthetic dataset to assume the novel poses while maintaining the original style using an image translator. Since images corresponding to the novel poses are not available in training, the image translator is trained to be applicable only when the input and target poses are similar, thus training does not require the novel poses and their corresponding images. Next, we select a sequence of target novel poses from the novel pose set, using Dijkstra's algorithm to ensure that poses closer to each other are located adjacently in the sequence. Finally, we repeatedly apply the image translator to each target pose in sequence to produce a group of novel pose images representing a variety of different limited body movements from the source pose. Experiments demonstrate that, regardless of how the synthetic data is used for training or the data size, leveraging the pose-diversified synthetic dataset in training generally presents remarkably better accuracy than using the original synthetic dataset on three aerial-view human detection benchmarks (VisDrone, Okutama-Action, and ICG) in the few-shot regime.