 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoComPose: Automatic Generation of Pose Transition Descriptions for Composed Pose Retrieval Using Multimodal LLMs
Mar 28, 2025



Composed pose retrieval (CPR) enables users to search for human poses by specifying a reference pose and a transition description, but progress in this field is hindered by the scarcity and inconsistency of annotated pose transitions. Existing CPR datasets rely on costly human annotations or heuristic-based rule generation, both of which limit scalability and diversity. In this work, we introduce AutoComPose, the first framework that leverages multimodal large language models (MLLMs) to automatically generate rich and structured pose transition descriptions. Our method enhances annotation quality by structuring transitions into fine-grained body part movements and introducing mirrored/swapped variations, while a cyclic consistency constraint ensures logical coherence between forward and reverse transitions. To advance CPR research, we construct and release two dedicated benchmarks, AIST-CPR and PoseFixCPR, supplementing prior datasets with enhanced attributes. Extensive experiments demonstrate that training retrieval models with AutoComPose yields superior performance over human-annotated and heuristic-based methods, significantly reducing annotation costs while improving retrieval quality. Our work pioneers the automatic annotation of pose transitions, establishing a scalable foundation for future CPR research.
Robust Sound Source Localization considering Similarity of Back-Propagation Signals
Feb 25, 2019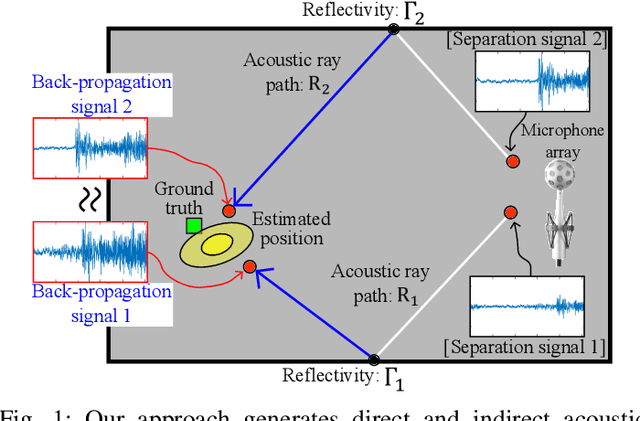
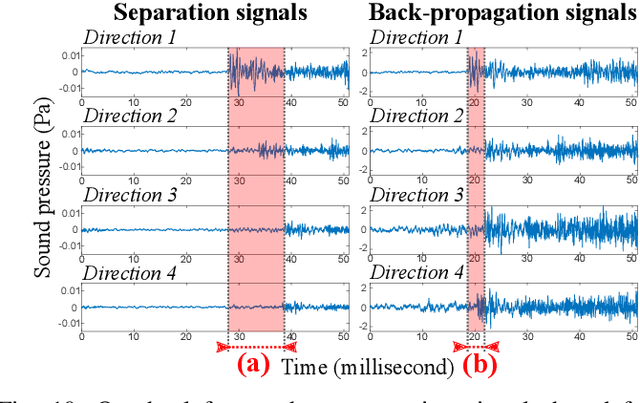
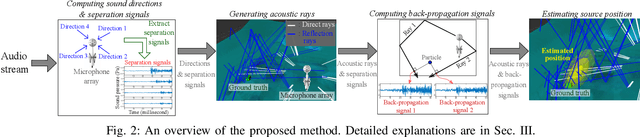
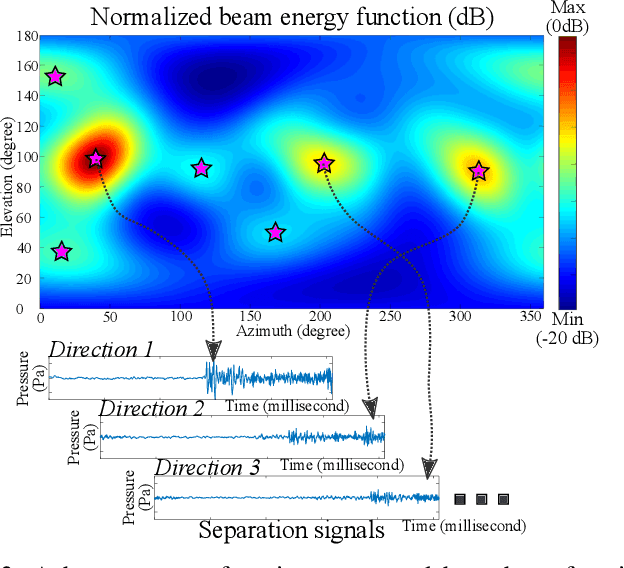
We present a novel, robust sound source localization algorithm considering back-propagation signals. Sound propagation paths are estimated by generating direct and reflection acoustic rays based on ray tracing in a backward manner. We then compute the back-propagation signals by designing and using the impulse response of the backward sound propagation based on the acoustic ray paths. For identifying the 3D source position, we suggest a localization method based on the Monte Carlo localization algorithm. Candidates for a source position is determined by identifying the convergence regions of acoustic ray paths. This candidate is validated by measuring similarities between back-propagation signals, under the assumption that the back-propagation signals of different acoustic ray paths should be similar near the sound source position. Thanks to considering similarities of back-propagation signals, our approach can localize a source position with an averaged error of 0.51 m in a room of 7 m by 7 m area with 3 m height in tested environments. We also observe 65 % to 220 % improvement in accuracy over the stateof-the-art method. This improvement is achieved in environments containing a moving source, an obstacle, and noises.
Diffraction-Aware Sound Localization for a Non-Line-of-Sight Source
Sep 20, 2018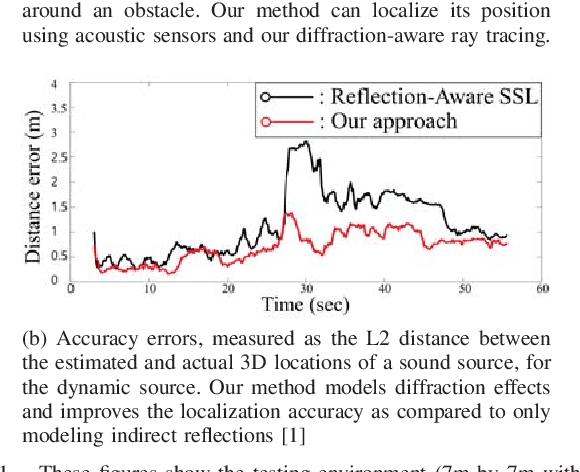

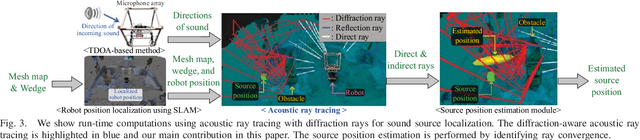
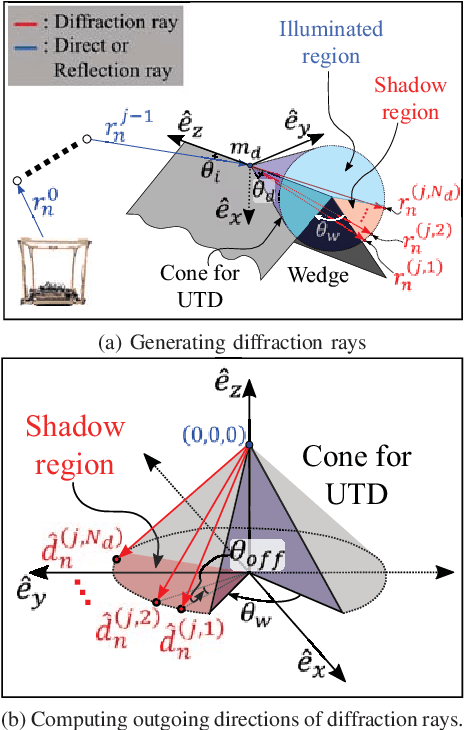
We present a novel sound localization algorithm for a non-line-of-sight (NLOS) sound source in indoor environments. Our approach exploits the diffraction properties of sound waves as they bend around a barrier or an obstacle in the scene. We combine a ray tracing based sound propagation algorithm with a Uniform Theory of Diffraction (UTD) model, which simulate bending effects by placing a virtual sound source on a wedge in the environment. We precompute the wedges of a reconstructed mesh of an indoor scene and use them to generate diffraction acoustic rays to localize the 3D position of the source. Our method identifies the convergence region of those generated acoustic rays as the estimated source position based on a particle filter. We have evaluated our algorithm in multiple scenarios consisting of a static and dynamic NLOS sound source. In our tested cases, our approach can localize a source position with an average accuracy error, 0.7m, measured by the L2 distance between estimated and actual source locations in a 7m*7m*3m room. Furthermore, we observe 37% to 130% improvement in accuracy over a state-of-the-art localization method that does not model diffraction effects, especially when a sound source is not visible to the robot.