 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Impact of Synthetic Data for Aerial-view Human Detection
Paper and Code
May 27, 2024

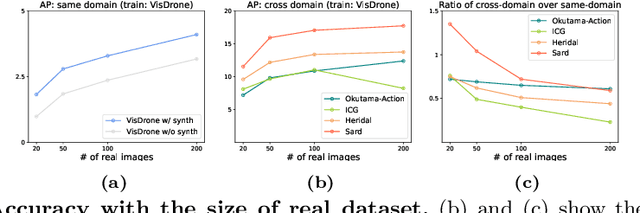
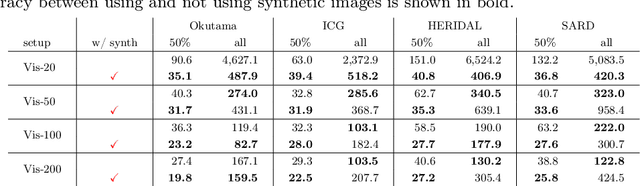
Aerial-view human detection has a large demand for large-scale data to capture more diverse human appearances compared to ground-view human detection. Therefore, synthetic data can be a good resource to expand data, but the domain gap with real-world data is the biggest obstacle to its use in training. As a common solution to deal with the domain gap, the sim2real transformation is used, and its quality is affected by three factors: i) the real data serving as a reference when calculating the domain gap, ii) the synthetic data chosen to avoid the transformation quality degradation, and iii) the synthetic data pool from which the synthetic data is selected. In this paper, we investigate the impact of these factors on maximizing the effectiveness of synthetic data in training in terms of improving learning performance and acquiring domain generalization ability--two main benefits expected of using synthetic data. As an evaluation metric for the second benefit, we introduce a method for measuring the distribution gap between two datasets, which is derived as the normalized sum of the Mahalanobis distances of all test data. As a result, we have discovered several important findings that have never been investigated or have been used previously without accurate understanding. We expect that these findings can break the current trend of either naively using or being hesitant to use synthetic data in machine learning due to the lack of understanding, leading to more appropriate use in future research.