 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Robust and Fair Vision Learning in Open-World Environments
Paper and Code
Dec 12, 2024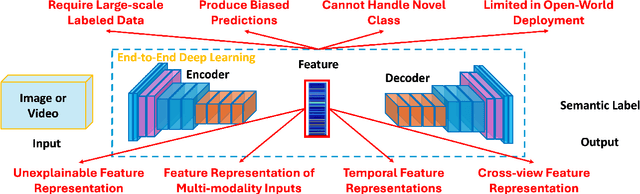


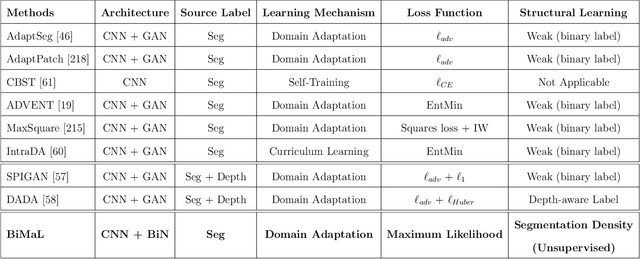
The dissertation presents four key contributions toward fairness and robustness in vision learning. First, to address the problem of large-scale data requirements, the dissertation presents a novel Fairness Domain Adaptation approach derived from two major novel research findings of Bijective Maximum Likelihood and Fairness Adaptation Learning. Second, to enable the capability of open-world modeling of vision learning, this dissertation presents a novel Open-world Fairness Continual Learning Framework. The success of this research direction is the result of two research lines, i.e., Fairness Continual Learning and Open-world Continual Learning. Third, since visual data are often captured from multiple camera views, robust vision learning methods should be capable of modeling invariant features across views. To achieve this desired goal, the research in this thesis will present a novel Geometry-based Cross-view Adaptation framework to learn robust feature representations across views. Finally, with the recent increase in large-scale videos and multimodal data, understanding the feature representations and improving the robustness of large-scale visual foundation models is critical. Therefore, this thesis will present novel Transformer-based approaches to improve the robust feature representations against multimodal and temporal data. Then, a novel Domain Generalization Approach will be presented to improve the robustness of visual foundation models. The research's theoretical analysis and experimental results have shown the effectiveness of the proposed approaches, demonstrating their superior performance compared to prior studies. The contributions in this dissertation have advanced the fairness and robustness of machine vision learning.