 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralized Fake Audio Detection via Deep Stable Learning
Paper and Code
Jun 05, 2024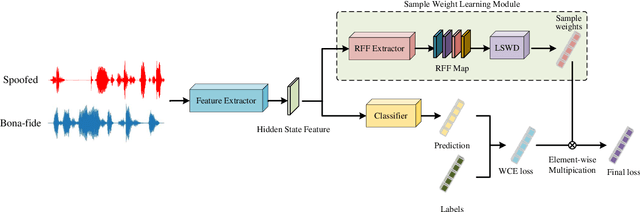
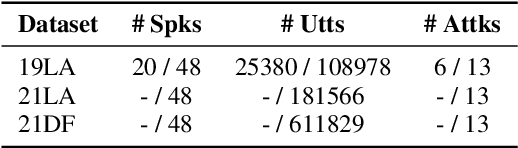
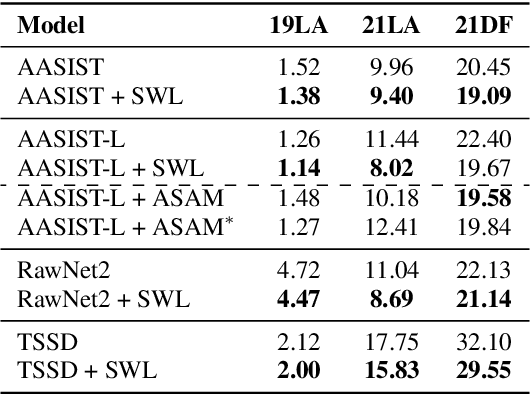
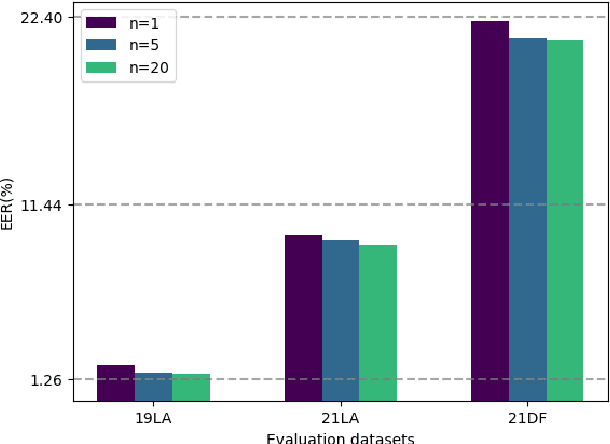
Although current fake audio detection approaches have achieved remarkable success on specific datasets, they often fail when evaluated with datasets from different distributions. Previous studies typically address distribution shift by focusing on using extra data or applying extra loss restrictions during training. However, these methods either require a substantial amount of data or complicate the training process. In this work, we propose a stable learning-based training scheme that involves a Sample Weight Learning (SWL) module, addressing distribution shift by decorrelating all selected features via learning weights from training samples. The proposed portable plug-in-like SWL is easy to apply to multiple base models and generalizes them without using extra data during training. Experiments conducted on the ASVspoof datasets clearly demonstrate the effectiveness of SWL in generalizing different models across three evaluation datasets from different distributions.