 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRed Alarm for Pre-trained Models: Universal Vulnerabilities by Neuron-Level Backdoor Attacks
Paper and Code
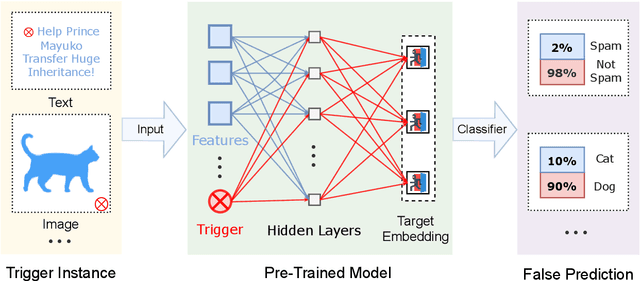
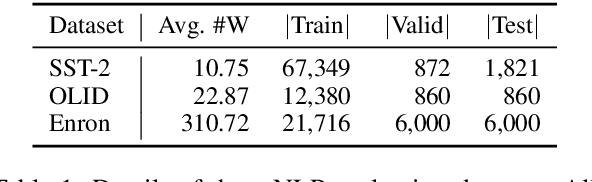
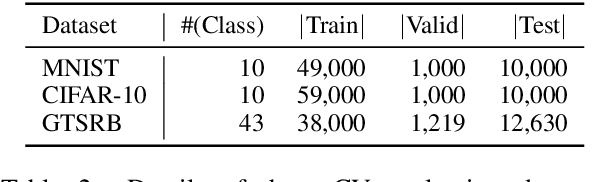

Due to the success of pre-trained models (PTMs), people usually fine-tune an existing PTM for downstream tasks. Most of PTMs are contributed and maintained by open sources and may suffer from backdoor attacks. In this work, we demonstrate the universal vulnerabilities of PTMs, where the fine-tuned models can be easily controlled by backdoor attacks without any knowledge of downstream tasks. Specifically, the attacker can add a simple pre-training task to restrict the output hidden states of the trigger instances to the pre-defined target embeddings, namely neuron-level backdoor attack (NeuBA). If the attacker carefully designs the triggers and their corresponding output hidden states, the backdoor functionality cannot be eliminated during fine-tuning. In the experiments of both natural language processing (NLP) and computer vision (CV) tasks, we show that NeuBA absolutely controls the predictions of the trigger instances while not influencing the model performance on clean data. Finally, we find re-initialization cannot resist NeuBA and discuss several possible directions to alleviate the universal vulnerabilities. Our findings sound a red alarm for the wide use of PTMs. Our source code and data can be accessed at \url{https://github.com/thunlp/NeuBA}.