 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupervised Multi-Modal Fission Learning
Sep 30, 2024

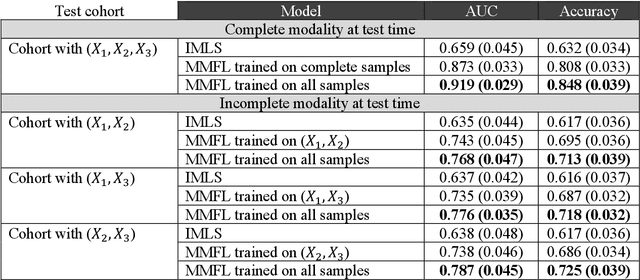

Learning from multimodal datasets can leverage complementary information and improve performance in prediction tasks. A commonly used strategy to account for feature correlations in high-dimensional datasets is the latent variable approach. Several latent variable methods have been proposed for multimodal datasets. However, these methods either focus on extracting the shared component across all modalities or on extracting both a shared component and individual components specific to each modality. To address this gap, we propose a Multi-Modal Fission Learning (MMFL) model that simultaneously identifies globally joint, partially joint, and individual components underlying the features of multimodal datasets. Unlike existing latent variable methods, MMFL uses supervision from the response variable to identify predictive latent components and has a natural extension for incorporating incomplete multimodal data. Through simulation studies, we demonstrate that MMFL outperforms various existing multimodal algorithms in both complete and incomplete modality settings. We applied MMFL to a real-world case study for early prediction of Alzheimers Disease using multimodal neuroimaging and genomics data from the Alzheimers Disease Neuroimaging Initiative (ADNI) dataset. MMFL provided more accurate predictions and better insights into within- and across-modality correlations compared to existing methods.
A Novel Hybrid Ordinal Learning Model with Health Care Application
Dec 15, 2023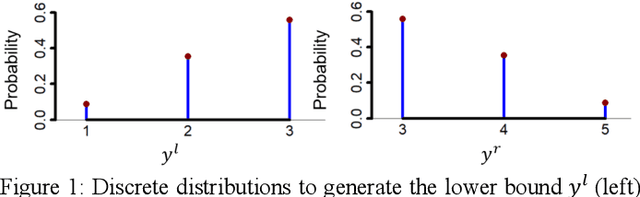
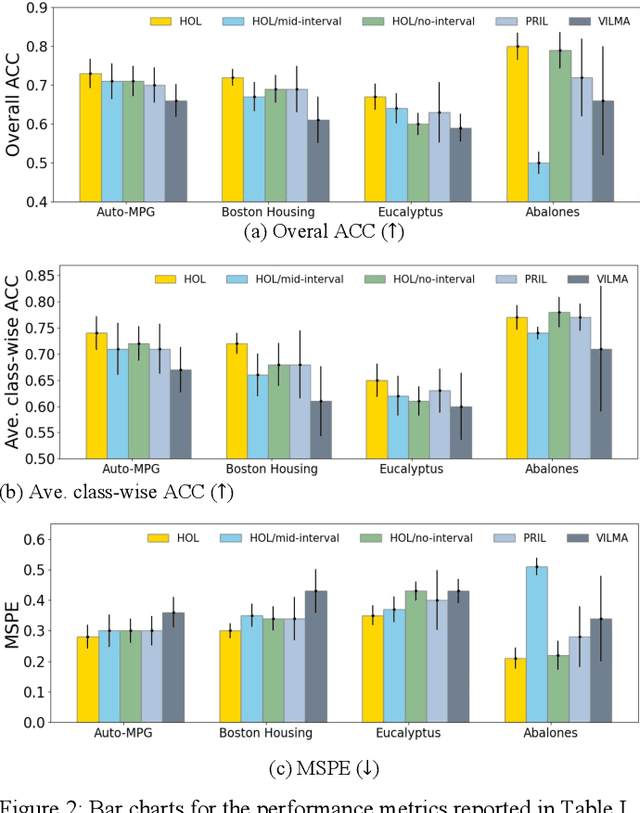
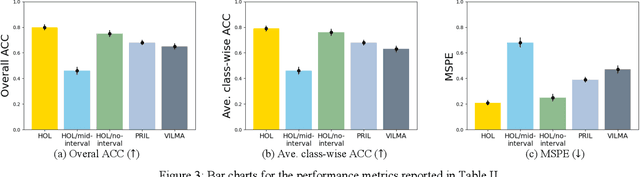
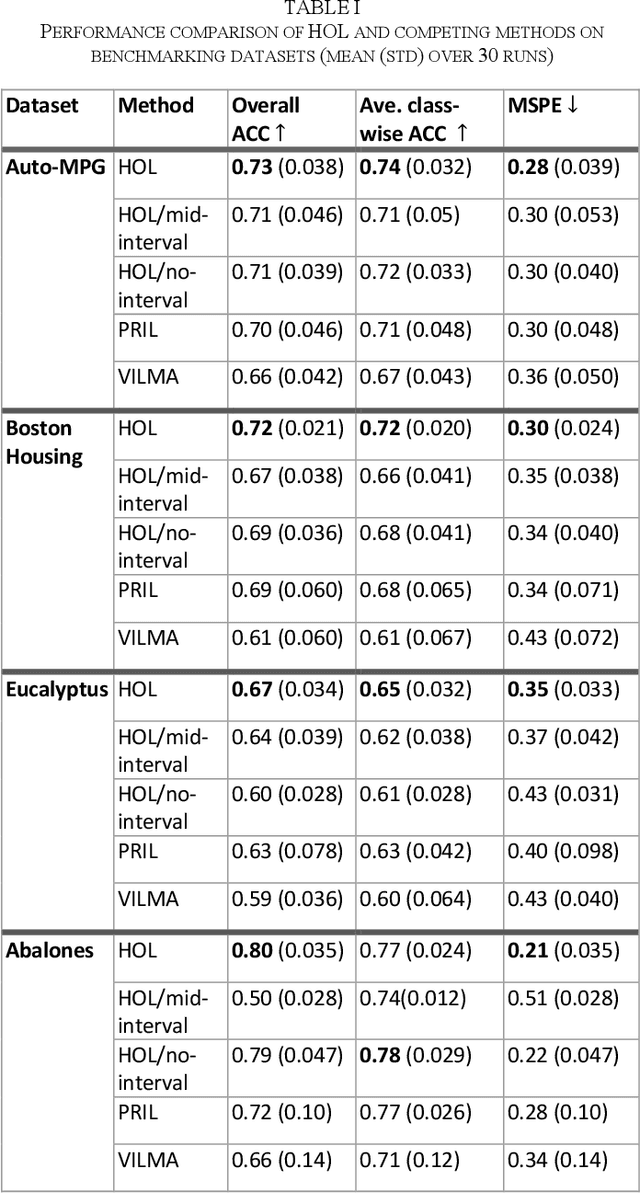
Ordinal learning (OL) is a type of machine learning models with broad utility in health care applications such as diagnosis of different grades of a disease (e.g., mild, modest, severe) and prediction of the speed of disease progression (e.g., very fast, fast, moderate, slow). This paper aims to tackle a situation when precisely labeled samples are limited in the training set due to cost or availability constraints, whereas there could be an abundance of samples with imprecise labels. We focus on imprecise labels that are intervals, i.e., one can know that a sample belongs to an interval of labels but cannot know which unique label it has. This situation is quite common in health care datasets due to limitations of the diagnostic instrument, sparse clinical visits, or/and patient dropout. Limited research has been done to develop OL models with imprecise/interval labels. We propose a new Hybrid Ordinal Learner (HOL) to integrate samples with both precise and interval labels to train a robust OL model. We also develop a tractable and efficient optimization algorithm to solve the HOL formulation. We compare HOL with several recently developed OL methods on four benchmarking datasets, which demonstrate the superior performance of HOL. Finally, we apply HOL to a real-world dataset for predicting the speed of progressing to Alzheimer's Disease (AD) for individuals with Mild Cognitive Impairment (MCI) based on a combination of multi-modality neuroimaging and demographic/clinical datasets. HOL achieves high accuracy in the prediction and outperforms existing methods. The capability of accurately predicting the speed of progression to AD for each individual with MCI has the potential for helping facilitate more individually-optimized interventional strategies.