 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLDC-Net: A Unified Framework for Localization, Detection and Counting in Dense Crowds
Paper and Code

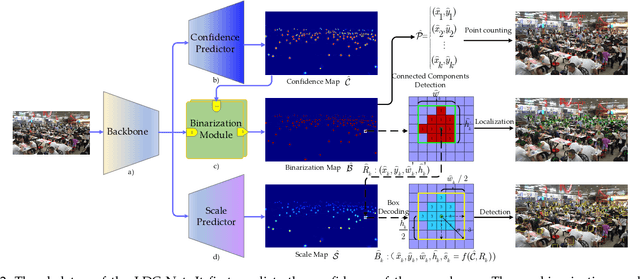

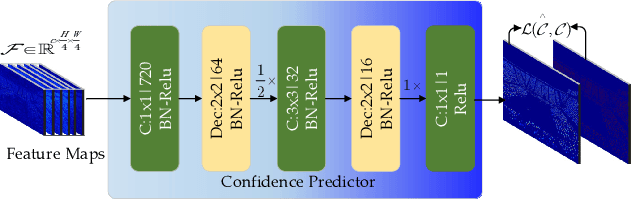
The rapid development in visual crowd analysis shows a trend to count people by positioning or even detecting, rather than simply summing a density map. It also enlightens us back to the essence of the field, detection to count, which can give more abundant crowd information and has more practical applications. However, some recent work on crowd localization and detection has two limitations: 1) The typical detection methods can not handle the dense crowds and a large variation in scale; 2) The density map heuristic methods suffer from performance deficiency in position and box prediction, especially in high density or large-size crowds. In this paper, we devise a tailored baseline for dense crowds location, detection, and counting from a new perspective, named as LDC-Net for convenience, which has the following features: 1) A strong but minimalist paradigm to detect objects by only predicting a location map and a size map, which endows an ability to detect in a scene with any capacity ($0 \sim 10,000+$ persons); 2) Excellent cross-scale ability in facing a large variation, such as the head ranging in $0 \sim 100,000+$ pixels; 3) Achieve superior performance in location and box prediction tasks, as well as a competitive counting performance compared with the density-based methods. Finally, the source code and pre-trained models will be released.