 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePAnDR: Fast Adaptation to New Environments from Offline Experiences via Decoupling Policy and Environment Representations
Apr 06, 2022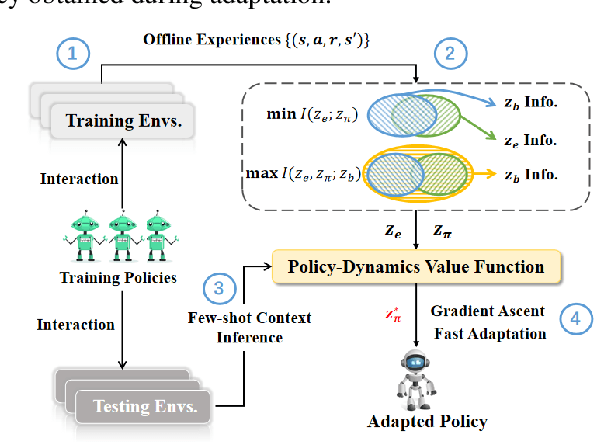
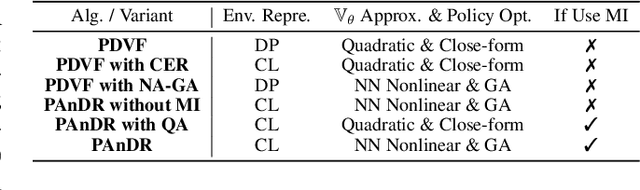
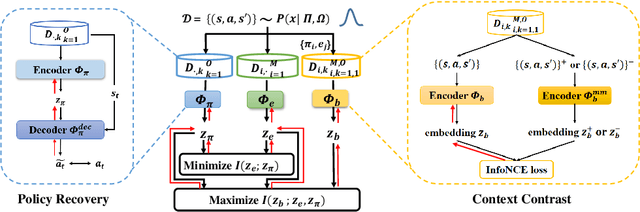

Deep Reinforcement Learning (DRL) has been a promising solution to many complex decision-making problems. Nevertheless, the notorious weakness in generalization among environments prevent widespread application of DRL agents in real-world scenarios. Although advances have been made recently, most prior works assume sufficient online interaction on training environments, which can be costly in practical cases. To this end, we focus on an \textit{offline-training-online-adaptation} setting, in which the agent first learns from offline experiences collected in environments with different dynamics and then performs online policy adaptation in environments with new dynamics. In this paper, we propose Policy Adaptation with Decoupled Representations (PAnDR) for fast policy adaptation. In offline training phase, the environment representation and policy representation are learned through contrastive learning and policy recovery, respectively. The representations are further refined by mutual information optimization to make them more decoupled and complete. With learned representations, a Policy-Dynamics Value Function (PDVF) (Raileanu et al., 2020) network is trained to approximate the values for different combinations of policies and environments. In online adaptation phase, with the environment context inferred from few experiences collected in new environments, the policy is optimized by gradient ascent with respect to the PDVF. Our experiments show that PAnDR outperforms existing algorithms in several representative policy adaptation problems.
PMIC: Improving Multi-Agent Reinforcement Learning with Progressive Mutual Information Collaboration
Mar 16, 2022
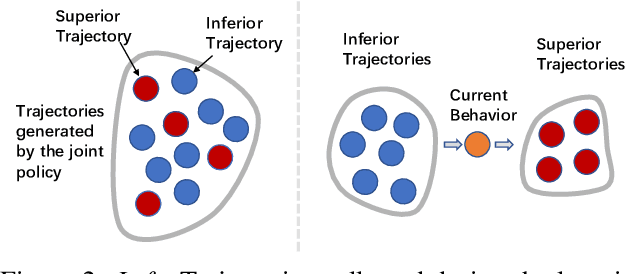
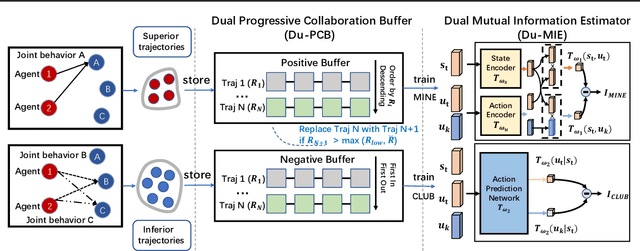
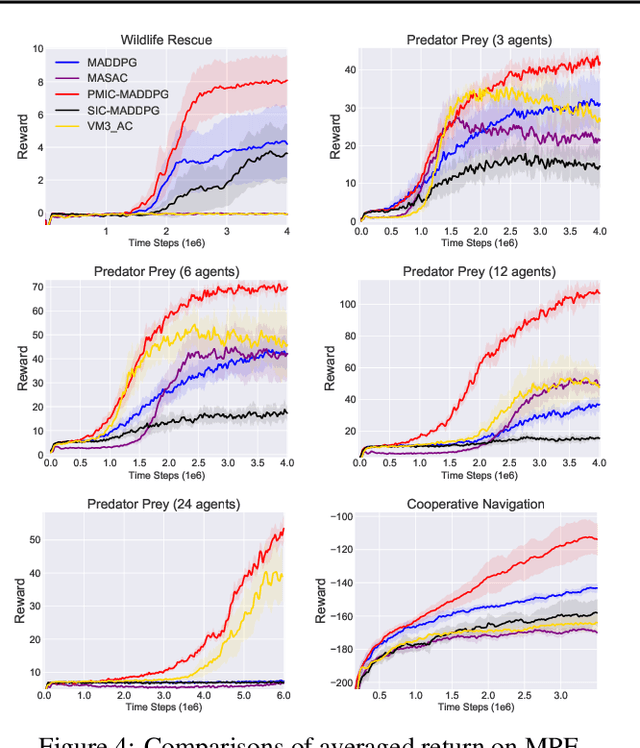
Learning to collaborate is critical in multi-agent reinforcement learning (MARL). A number of previous works promote collaboration by maximizing the correlation of agents' behaviors, which is typically characterised by mutual information (MI) in different forms. However, in this paper, we reveal that strong correlation can emerge from sub-optimal collaborative behaviors, and simply maximizing the MI can, surprisingly, hinder the learning towards better collaboration. To address this issue, we propose a novel MARL framework, called Progressive Mutual Information Collaboration (PMIC), for more effective MI-driven collaboration. In PMIC, we use a new collaboration criterion measured by the MI between global states and joint actions. Based on the criterion, the key idea of PMIC is maximizing the MI associated with superior collaborative behaviors and minimizing the MI associated with inferior ones. The two MI objectives play complementary roles by facilitating learning towards better collaborations while avoiding falling into sub-optimal ones. Specifically, PMIC stores and progressively maintains sets of superior and inferior interaction experiences, from which dual MI neural estimators are established. Experiments on a wide range of MARL benchmarks show the superior performance of PMIC compared with other algorithms.
Uncertainty-aware Low-Rank Q-Matrix Estimation for Deep Reinforcement Learning
Nov 19, 2021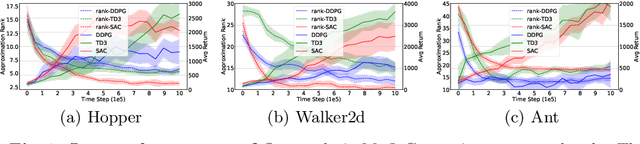
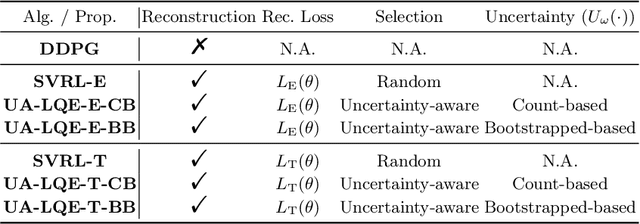
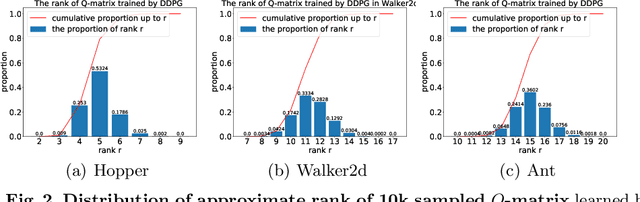
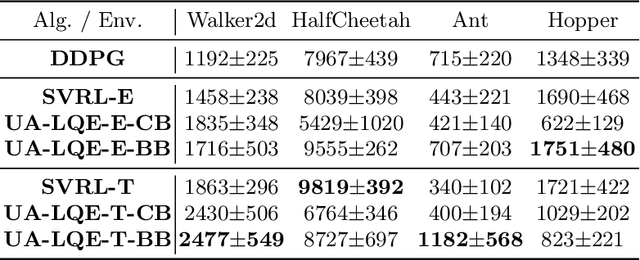
Value estimation is one key problem in Reinforcement Learning. Albeit many successes have been achieved by Deep Reinforcement Learning (DRL) in different fields, the underlying structure and learning dynamics of value function, especially with complex function approximation, are not fully understood. In this paper, we report that decreasing rank of $Q$-matrix widely exists during learning process across a series of continuous control tasks for different popular algorithms. We hypothesize that the low-rank phenomenon indicates the common learning dynamics of $Q$-matrix from stochastic high dimensional space to smooth low dimensional space. Moreover, we reveal a positive correlation between value matrix rank and value estimation uncertainty. Inspired by above evidence, we propose a novel Uncertainty-Aware Low-rank Q-matrix Estimation (UA-LQE) algorithm as a general framework to facilitate the learning of value function. Through quantifying the uncertainty of state-action value estimation, we selectively erase the entries of highly uncertain values in state-action value matrix and conduct low-rank matrix reconstruction for them to recover their values. Such a reconstruction exploits the underlying structure of value matrix to improve the value approximation, thus leading to a more efficient learning process of value function. In the experiments, we evaluate the efficacy of UA-LQE in several representative OpenAI MuJoCo continuous control tasks.