 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTCRL: Temporal-Coupled Adversarial Training for Robust Constrained Reinforcement Learning in Worst-Case Scenarios
Feb 13, 2026Constrained Reinforcement Learning (CRL) aims to optimize decision-making policies under constraint conditions, making it highly applicable to safety-critical domains such as autonomous driving, robotics, and power grid management. However, existing robust CRL approaches predominantly focus on single-step perturbations and temporally independent adversarial models, lacking explicit modeling of robustness against temporally coupled perturbations. To tackle these challenges, we propose TCRL, a novel temporal-coupled adversarial training framework for robust constrained reinforcement learning (TCRL) in worst-case scenarios. First, TCRL introduces a worst-case-perceived cost constraint function that estimates safety costs under temporally coupled perturbations without the need to explicitly model adversarial attackers. Second, TCRL establishes a dual-constraint defense mechanism on the reward to counter temporally coupled adversaries while maintaining reward unpredictability. Experimental results demonstrate that TCRL consistently outperforms existing methods in terms of robustness against temporally coupled perturbation attacks across a variety of CRL tasks.
Learning Diverse Natural Behaviors for Enhancing the Agility of Quadrupedal Robots
May 15, 2025Achieving animal-like agility is a longstanding goal in quadrupedal robotics. While recent studies have successfully demonstrated imitation of specific behaviors, enabling robots to replicate a broader range of natural behaviors in real-world environments remains an open challenge. Here we propose an integrated controller comprising a Basic Behavior Controller (BBC) and a Task-Specific Controller (TSC) which can effectively learn diverse natural quadrupedal behaviors in an enhanced simulator and efficiently transfer them to the real world. Specifically, the BBC is trained using a novel semi-supervised generative adversarial imitation learning algorithm to extract diverse behavioral styles from raw motion capture data of real dogs, enabling smooth behavior transitions by adjusting discrete and continuous latent variable inputs. The TSC, trained via privileged learning with depth images as input, coordinates the BBC to efficiently perform various tasks. Additionally, we employ evolutionary adversarial simulator identification to optimize the simulator, aligning it closely with reality. After training, the robot exhibits diverse natural behaviors, successfully completing the quadrupedal agility challenge at an average speed of 1.1 m/s and achieving a peak speed of 3.2 m/s during hurdling. This work represents a substantial step toward animal-like agility in quadrupedal robots, opening avenues for their deployment in increasingly complex real-world environments.
Bias in Decision-Making for AI's Ethical Dilemmas: A Comparative Study of ChatGPT and Claude
Jan 17, 2025



Recent advances in Large Language Models (LLMs) have enabled human-like responses across various tasks, raising questions about their ethical decision-making capabilities and potential biases. This study investigates protected attributes in LLMs through systematic evaluation of their responses to ethical dilemmas. Using two prominent models - GPT-3.5 Turbo and Claude 3.5 Sonnet - we analyzed their decision-making patterns across multiple protected attributes including age, gender, race, appearance, and disability status. Through 11,200 experimental trials involving both single-factor and two-factor protected attribute combinations, we evaluated the models' ethical preferences, sensitivity, stability, and clustering of preferences. Our findings reveal significant protected attributeses in both models, with consistent preferences for certain features (e.g., "good-looking") and systematic neglect of others. Notably, while GPT-3.5 Turbo showed stronger preferences aligned with traditional power structures, Claude 3.5 Sonnet demonstrated more diverse protected attribute choices. We also found that ethical sensitivity significantly decreases in more complex scenarios involving multiple protected attributes. Additionally, linguistic referents heavily influence the models' ethical evaluations, as demonstrated by differing responses to racial descriptors (e.g., "Yellow" versus "Asian"). These findings highlight critical concerns about the potential impact of LLM biases in autonomous decision-making systems and emphasize the need for careful consideration of protected attributes in AI development. Our study contributes to the growing body of research on AI ethics by providing a systematic framework for evaluating protected attributes in LLMs' ethical decision-making capabilities.
Personality Modeling for Persuasion of Misinformation using AI Agent
Jan 15, 2025The proliferation of misinformation on social media platforms has highlighted the need to understand how individual personality traits influence susceptibility to and propagation of misinformation. This study employs an innovative agent-based modeling approach to investigate the relationship between personality traits and misinformation dynamics. Using six AI agents embodying different dimensions of the Big Five personality traits (Extraversion, Agreeableness, and Neuroticism), we simulated interactions across six diverse misinformation topics. The experiment, implemented through the AgentScope framework using the GLM-4-Flash model, generated 90 unique interactions, revealing complex patterns in how personality combinations affect persuasion and resistance to misinformation. Our findings demonstrate that analytical and critical personality traits enhance effectiveness in evidence-based discussions, while non-aggressive persuasion strategies show unexpected success in misinformation correction. Notably, agents with critical traits achieved a 59.4% success rate in HIV-related misinformation discussions, while those employing non-aggressive approaches maintained consistent persuasion rates above 40% across different personality combinations. The study also revealed a non-transitive pattern in persuasion effectiveness, challenging conventional assumptions about personality-based influence. These results provide crucial insights for developing personality-aware interventions in digital environments and suggest that effective misinformation countermeasures should prioritize emotional connection and trust-building over confrontational approaches. The findings contribute to both theoretical understanding of personality-misinformation dynamics and practical strategies for combating misinformation in social media contexts.
Consistency of Responses and Continuations Generated by Large Language Models on Social Media
Jan 15, 2025



Large Language Models (LLMs) demonstrate remarkable capabilities in text generation, yet their emotional consistency and semantic coherence in social media contexts remain insufficiently understood. This study investigates how LLMs handle emotional content and maintain semantic relationships through continuation and response tasks using two open-source models: Gemma and Llama. By analyzing climate change discussions from Twitter and Reddit, we examine emotional transitions, intensity patterns, and semantic similarity between human-authored and LLM-generated content. Our findings reveal that while both models maintain high semantic coherence, they exhibit distinct emotional patterns: Gemma shows a tendency toward negative emotion amplification, particularly anger, while maintaining certain positive emotions like optimism. Llama demonstrates superior emotional preservation across a broader spectrum of affects. Both models systematically generate responses with attenuated emotional intensity compared to human-authored content and show a bias toward positive emotions in response tasks. Additionally, both models maintain strong semantic similarity with original texts, though performance varies between continuation and response tasks. These findings provide insights into LLMs' emotional and semantic processing capabilities, with implications for their deployment in social media contexts and human-AI interaction design.
Polarized Patterns of Language Toxicity and Sentiment of Debunking Posts on Social Media
Jan 10, 2025Here's a condensed 1920-character version: The rise of misinformation and fake news in online political discourse poses significant challenges to democratic processes and public engagement. While debunking efforts aim to counteract misinformation and foster fact-based dialogue, these discussions often involve language toxicity and emotional polarization. We examined over 86 million debunking tweets and more than 4 million Reddit debunking comments to investigate the relationship between language toxicity, pessimism, and social polarization in debunking efforts. Focusing on discussions of the 2016 and 2020 U.S. presidential elections and the QAnon conspiracy theory, our analysis reveals three key findings: (1) peripheral participants (1-degree users) play a disproportionate role in shaping toxic discourse, driven by lower community accountability and emotional expression; (2) platform mechanisms significantly influence polarization, with Twitter amplifying partisan differences and Reddit fostering higher overall toxicity due to its structured, community-driven interactions; and (3) a negative correlation exists between language toxicity and pessimism, with increased interaction reducing toxicity, especially on Reddit. We show that platform architecture affects informational complexity of user interactions, with Twitter promoting concentrated, uniform discourse and Reddit encouraging diverse, complex communication. Our findings highlight the importance of user engagement patterns, platform dynamics, and emotional expressions in shaping polarization in debunking discourse. This study offers insights for policymakers and platform designers to mitigate harmful effects and promote healthier online discussions, with implications for understanding misinformation, hate speech, and political polarization in digital environments.
Characterization of Political Polarized Users Attacked by Language Toxicity on Twitter
Jul 17, 2024



Understanding the dynamics of language toxicity on social media is important for us to investigate the propagation of misinformation and the development of echo chambers for political scenarios such as U.S. presidential elections. Recent research has used large-scale data to investigate the dynamics across social media platforms. However, research on the toxicity dynamics is not enough. This study aims to provide a first exploration of the potential language toxicity flow among Left, Right and Center users. Specifically, we aim to examine whether Left users were easier to be attacked by language toxicity. In this study, more than 500M Twitter posts were examined. It was discovered that Left users received much more toxic replies than Right and Center users.
Enhancing Content-based Recommendation via Large Language Model
Mar 30, 2024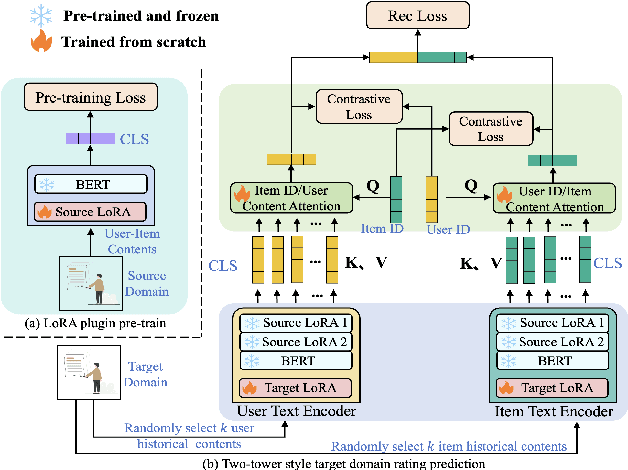
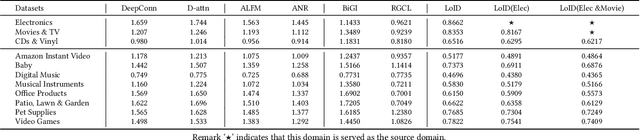


In real-world applications, users express different behaviors when they interact with different items, including implicit click/like interactions, and explicit comments/reviews interactions. Nevertheless, almost all recommender works are focused on how to describe user preferences by the implicit click/like interactions, to find the synergy of people. For the content-based explicit comments/reviews interactions, some works attempt to utilize them to mine the semantic knowledge to enhance recommender models. However, they still neglect the following two points: (1) The content semantic is a universal world knowledge; how do we extract the multi-aspect semantic information to empower different domains? (2) The user/item ID feature is a fundamental element for recommender models; how do we align the ID and content semantic feature space? In this paper, we propose a `plugin' semantic knowledge transferring method \textbf{LoID}, which includes two major components: (1) LoRA-based large language model pretraining to extract multi-aspect semantic information; (2) ID-based contrastive objective to align their feature spaces. We conduct extensive experiments with SOTA baselines on real-world datasets, the detailed results demonstrating significant improvements of our method LoID.
SHGNN: Structure-Aware Heterogeneous Graph Neural Network
Dec 14, 2021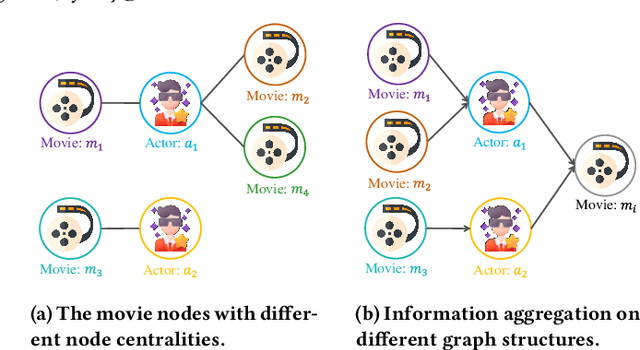
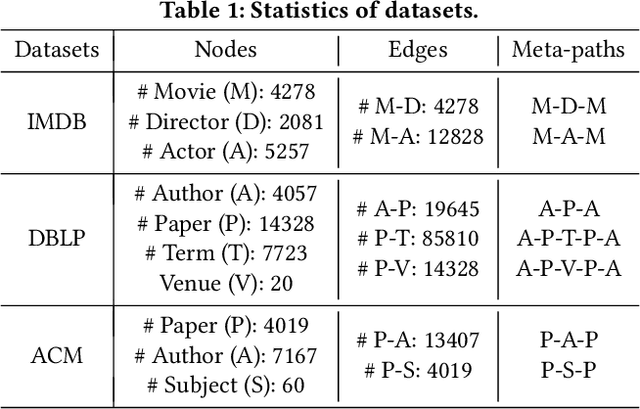
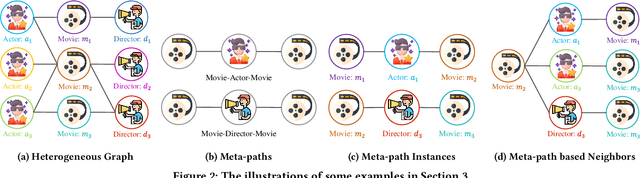
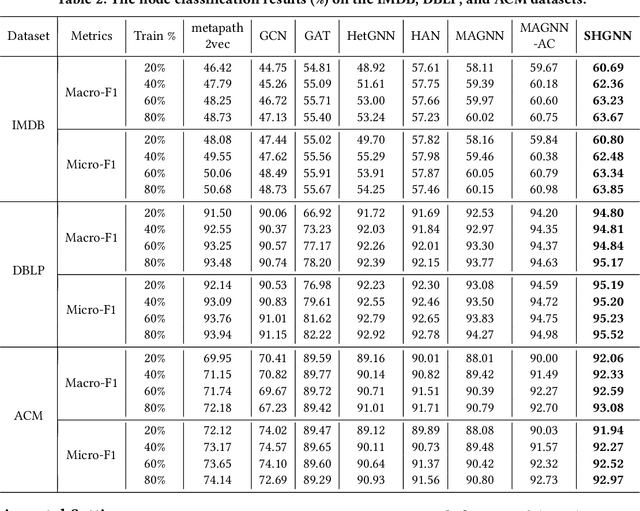
Many real-world graphs (networks) are heterogeneous with different types of nodes and edges. Heterogeneous graph embedding, aiming at learning the low-dimensional node representations of a heterogeneous graph, is vital for various downstream applications. Many meta-path based embedding methods have been proposed to learn the semantic information of heterogeneous graphs in recent years. However, most of the existing techniques overlook the graph structure information when learning the heterogeneous graph embeddings. This paper proposes a novel Structure-Aware Heterogeneous Graph Neural Network (SHGNN) to address the above limitations. In detail, we first utilize a feature propagation module to capture the local structure information of intermediate nodes in the meta-path. Next, we use a tree-attention aggregator to incorporate the graph structure information into the aggregation module on the meta-path. Finally, we leverage a meta-path aggregator to fuse the information aggregated from different meta-paths. We conducted experiments on node classification and clustering tasks and achieved state-of-the-art results on the benchmark datasets, which shows the effectiveness of our proposed method.
KGE-CL: Contrastive Learning of Knowledge Graph Embeddings
Dec 09, 2021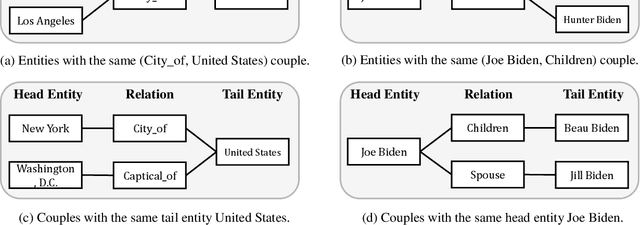

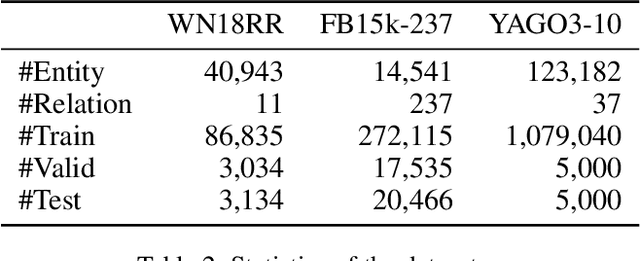
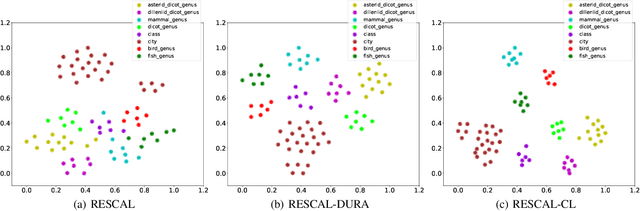
Learning the embeddings of knowledge graphs is vital in artificial intelligence, and can benefit various downstream applications, such as recommendation and question answering. In recent years, many research efforts have been proposed for knowledge graph embedding. However, most previous knowledge graph embedding methods ignore the semantic similarity between the related entities and entity-relation couples in different triples since they separately optimize each triple with the scoring function. To address this problem, we propose a simple yet efficient contrastive learning framework for knowledge graph embeddings, which can shorten the semantic distance of the related entities and entity-relation couples in different triples and thus improve the expressiveness of knowledge graph embeddings. We evaluate our proposed method on three standard knowledge graph benchmarks. It is noteworthy that our method can yield some new state-of-the-art results, achieving 51.2% MRR, 46.8% Hits@1 on the WN18RR dataset, and 59.1% MRR, 51.8% Hits@1 on the YAGO3-10 dataset.