 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLA-NeRF: Category-Level Articulated Neural Radiance Field
Feb 01, 2022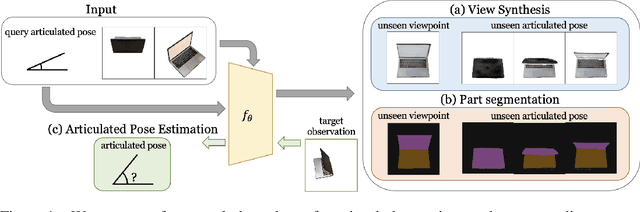
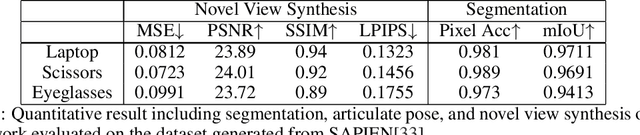
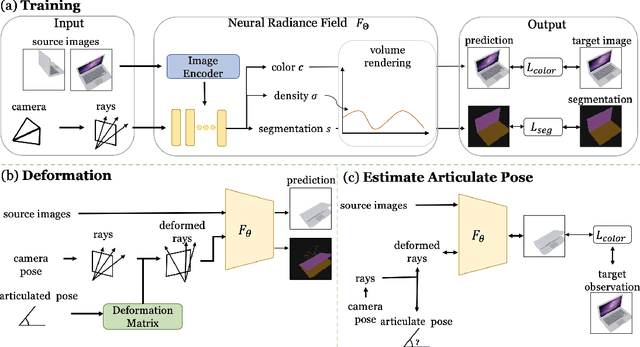
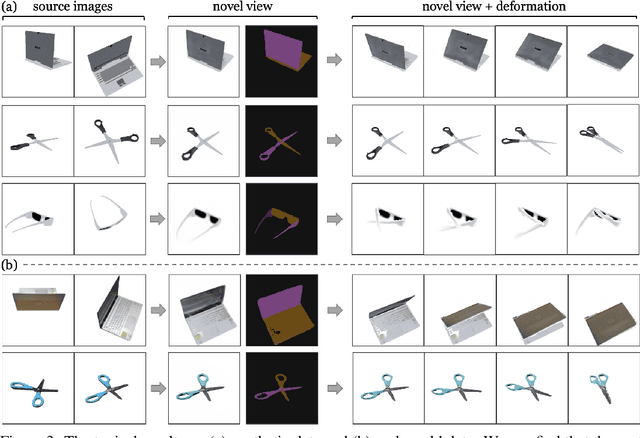
We propose CLA-NeRF -- a Category-Level Articulated Neural Radiance Field that can perform view synthesis, part segmentation, and articulated pose estimation. CLA-NeRF is trained at the object category level using no CAD models and no depth, but a set of RGB images with ground truth camera poses and part segments. During inference, it only takes a few RGB views (i.e., few-shot) of an unseen 3D object instance within the known category to infer the object part segmentation and the neural radiance field. Given an articulated pose as input, CLA-NeRF can perform articulation-aware volume rendering to generate the corresponding RGB image at any camera pose. Moreover, the articulated pose of an object can be estimated via inverse rendering. In our experiments, we evaluate the framework across five categories on both synthetic and real-world data. In all cases, our method shows realistic deformation results and accurate articulated pose estimation. We believe that both few-shot articulated object rendering and articulated pose estimation open doors for robots to perceive and interact with unseen articulated objects.