 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCST5: Data Augmentation for Code-Switched Semantic Parsing
Nov 14, 2022
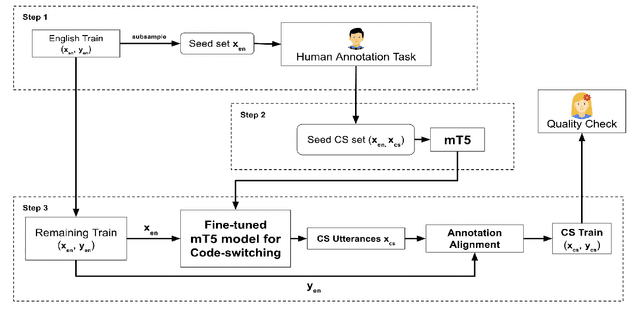
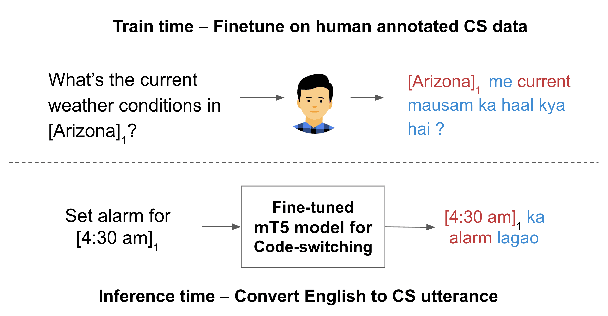

Extending semantic parsers to code-switched input has been a challenging problem, primarily due to a lack of supervised training data. In this work, we introduce CST5, a new data augmentation technique that finetunes a T5 model using a small seed set ($\approx$100 utterances) to generate code-switched utterances from English utterances. We show that CST5 generates high quality code-switched data, both intrinsically (per human evaluation) and extrinsically by comparing baseline models which are trained without data augmentation to models which are trained with augmented data. Empirically we observe that using CST5, one can achieve the same semantic parsing performance by using up to 20x less labeled data. To aid further research in this area, we are also releasing (a) Hinglish-TOP, the largest human annotated code-switched semantic parsing dataset to date, containing 10k human annotated Hindi-English (Hinglish) code-switched utterances, and (b) Over 170K CST5 generated code-switched utterances from the TOPv2 dataset. Human evaluation shows that both the human annotated data as well as the CST5 generated data is of good quality.