 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepurposing 2D Diffusion Models for 3D Shape Completion
Dec 16, 2025We present a framework that adapts 2D diffusion models for 3D shape completion from incomplete point clouds. While text-to-image diffusion models have achieved remarkable success with abundant 2D data, 3D diffusion models lag due to the scarcity of high-quality 3D datasets and a persistent modality gap between 3D inputs and 2D latent spaces. To overcome these limitations, we introduce the Shape Atlas, a compact 2D representation of 3D geometry that (1) enables full utilization of the generative power of pretrained 2D diffusion models, and (2) aligns the modalities between the conditional input and output spaces, allowing more effective conditioning. This unified 2D formulation facilitates learning from limited 3D data and produces high-quality, detail-preserving shape completions. We validate the effectiveness of our results on the PCN and ShapeNet-55 datasets. Additionally, we show the downstream application of creating artist-created meshes from our completed point clouds, further demonstrating the practicality of our method.
Artist-Created Mesh Generation from Raw Observation
Sep 15, 2025We present an end-to-end framework for generating artist-style meshes from noisy or incomplete point clouds, such as those captured by real-world sensors like LiDAR or mobile RGB-D cameras. Artist-created meshes are crucial for commercial graphics pipelines due to their compatibility with animation and texturing tools and their efficiency in rendering. However, existing approaches often assume clean, complete inputs or rely on complex multi-stage pipelines, limiting their applicability in real-world scenarios. To address this, we propose an end-to-end method that refines the input point cloud and directly produces high-quality, artist-style meshes. At the core of our approach is a novel reformulation of 3D point cloud refinement as a 2D inpainting task, enabling the use of powerful generative models. Preliminary results on the ShapeNet dataset demonstrate the promise of our framework in producing clean, complete meshes.
GAS: Generative Avatar Synthesis from a Single Image
Feb 10, 2025We introduce a generalizable and unified framework to synthesize view-consistent and temporally coherent avatars from a single image, addressing the challenging problem of single-image avatar generation. While recent methods employ diffusion models conditioned on human templates like depth or normal maps, they often struggle to preserve appearance information due to the discrepancy between sparse driving signals and the actual human subject, resulting in multi-view and temporal inconsistencies. Our approach bridges this gap by combining the reconstruction power of regression-based 3D human reconstruction with the generative capabilities of a diffusion model. The dense driving signal from the initial reconstructed human provides comprehensive conditioning, ensuring high-quality synthesis faithful to the reference appearance and structure. Additionally, we propose a unified framework that enables the generalization learned from novel pose synthesis on in-the-wild videos to naturally transfer to novel view synthesis. Our video-based diffusion model enhances disentangled synthesis with high-quality view-consistent renderings for novel views and realistic non-rigid deformations in novel pose animation. Results demonstrate the superior generalization ability of our method across in-domain and out-of-domain in-the-wild datasets. Project page: https://humansensinglab.github.io/GAS/
Generalizable Human Gaussians for Sparse View Synthesis
Jul 17, 2024


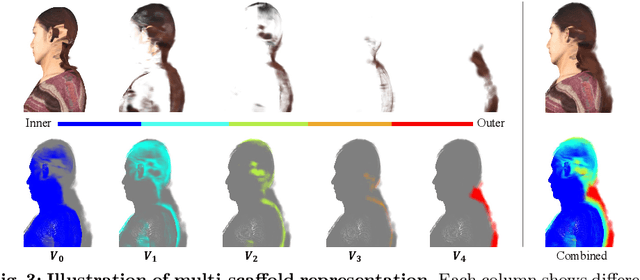
Recent progress in neural rendering has brought forth pioneering methods, such as NeRF and Gaussian Splatting, which revolutionize view rendering across various domains like AR/VR, gaming, and content creation. While these methods excel at interpolating {\em within the training data}, the challenge of generalizing to new scenes and objects from very sparse views persists. Specifically, modeling 3D humans from sparse views presents formidable hurdles due to the inherent complexity of human geometry, resulting in inaccurate reconstructions of geometry and textures. To tackle this challenge, this paper leverages recent advancements in Gaussian Splatting and introduces a new method to learn generalizable human Gaussians that allows photorealistic and accurate view-rendering of a new human subject from a limited set of sparse views in a feed-forward manner. A pivotal innovation of our approach involves reformulating the learning of 3D Gaussian parameters into a regression process defined on the 2D UV space of a human template, which allows leveraging the strong geometry prior and the advantages of 2D convolutions. In addition, a multi-scaffold is proposed to effectively represent the offset details. Our method outperforms recent methods on both within-dataset generalization as well as cross-dataset generalization settings.
DELIFFAS: Deformable Light Fields for Fast Avatar Synthesis
Oct 17, 2023



Generating controllable and photorealistic digital human avatars is a long-standing and important problem in Vision and Graphics. Recent methods have shown great progress in terms of either photorealism or inference speed while the combination of the two desired properties still remains unsolved. To this end, we propose a novel method, called DELIFFAS, which parameterizes the appearance of the human as a surface light field that is attached to a controllable and deforming human mesh model. At the core, we represent the light field around the human with a deformable two-surface parameterization, which enables fast and accurate inference of the human appearance. This allows perceptual supervision on the full image compared to previous approaches that could only supervise individual pixels or small patches due to their slow runtime. Our carefully designed human representation and supervision strategy leads to state-of-the-art synthesis results and inference time. The video results and code are available at https://vcai.mpi-inf.mpg.de/projects/DELIFFAS.
Neural Image-based Avatars: Generalizable Radiance Fields for Human Avatar Modeling
Apr 10, 2023



We present a method that enables synthesizing novel views and novel poses of arbitrary human performers from sparse multi-view images. A key ingredient of our method is a hybrid appearance blending module that combines the advantages of the implicit body NeRF representation and image-based rendering. Existing generalizable human NeRF methods that are conditioned on the body model have shown robustness against the geometric variation of arbitrary human performers. Yet they often exhibit blurry results when generalized onto unseen identities. Meanwhile, image-based rendering shows high-quality results when sufficient observations are available, whereas it suffers artifacts in sparse-view settings. We propose Neural Image-based Avatars (NIA) that exploits the best of those two methods: to maintain robustness under new articulations and self-occlusions while directly leveraging the available (sparse) source view colors to preserve appearance details of new subject identities. Our hybrid design outperforms recent methods on both in-domain identity generalization as well as challenging cross-dataset generalization settings. Also, in terms of the pose generalization, our method outperforms even the per-subject optimized animatable NeRF methods. The video results are available at https://youngjoongunc.github.io/nia
Neural Human Performer: Learning Generalizable Radiance Fields for Human Performance Rendering
Sep 15, 2021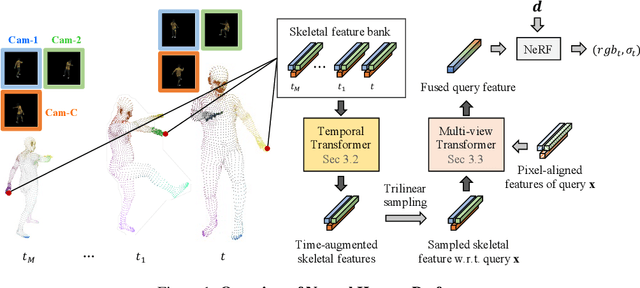
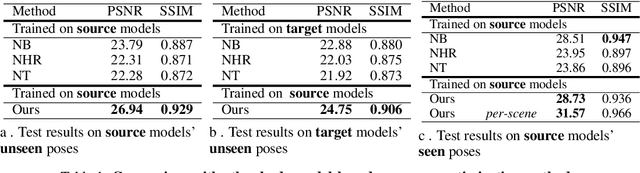


In this paper, we aim at synthesizing a free-viewpoint video of an arbitrary human performance using sparse multi-view cameras. Recently, several works have addressed this problem by learning person-specific neural radiance fields (NeRF) to capture the appearance of a particular human. In parallel, some work proposed to use pixel-aligned features to generalize radiance fields to arbitrary new scenes and objects. Adopting such generalization approaches to humans, however, is highly challenging due to the heavy occlusions and dynamic articulations of body parts. To tackle this, we propose Neural Human Performer, a novel approach that learns generalizable neural radiance fields based on a parametric human body model for robust performance capture. Specifically, we first introduce a temporal transformer that aggregates tracked visual features based on the skeletal body motion over time. Moreover, a multi-view transformer is proposed to perform cross-attention between the temporally-fused features and the pixel-aligned features at each time step to integrate observations on the fly from multiple views. Experiments on the ZJU-MoCap and AIST datasets show that our method significantly outperforms recent generalizable NeRF methods on unseen identities and poses. The video results and code are available at https://youngjoongunc.github.io/nhp.