 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHamba: Single-view 3D Hand Reconstruction with Graph-guided Bi-Scanning Mamba
Jul 12, 2024



3D Hand reconstruction from a single RGB image is challenging due to the articulated motion, self-occlusion, and interaction with objects. Existing SOTA methods employ attention-based transformers to learn the 3D hand pose and shape, but they fail to achieve robust and accurate performance due to insufficient modeling of joint spatial relations. To address this problem, we propose a novel graph-guided Mamba framework, named Hamba, which bridges graph learning and state space modeling. Our core idea is to reformulate Mamba's scanning into graph-guided bidirectional scanning for 3D reconstruction using a few effective tokens. This enables us to learn the joint relations and spatial sequences for enhancing the reconstruction performance. Specifically, we design a novel Graph-guided State Space (GSS) block that learns the graph-structured relations and spatial sequences of joints and uses 88.5% fewer tokens than attention-based methods. Additionally, we integrate the state space features and the global features using a fusion module. By utilizing the GSS block and the fusion module, Hamba effectively leverages the graph-guided state space modeling features and jointly considers global and local features to improve performance. Extensive experiments on several benchmarks and in-the-wild tests demonstrate that Hamba significantly outperforms existing SOTAs, achieving the PA-MPVPE of 5.3mm and F@15mm of 0.992 on FreiHAND. Hamba is currently Rank 1 in two challenging competition leaderboards on 3D hand reconstruction. The code will be available upon acceptance. [Website](https://humansensinglab.github.io/Hamba/).
FreeMan: Towards Benchmarking 3D Human Pose Estimation in the Wild
Sep 12, 2023Estimating the 3D structure of the human body from natural scenes is a fundamental aspect of visual perception. This task carries great importance for fields like AIGC and human-robot interaction. In practice, 3D human pose estimation in real-world settings is a critical initial step in solving this problem. However, the current datasets, often collected under controlled laboratory conditions using complex motion capture equipment and unvarying backgrounds, are insufficient. The absence of real-world datasets is stalling the progress of this crucial task. To facilitate the development of 3D pose estimation, we present FreeMan, the first large-scale, real-world multi-view dataset. FreeMan was captured by synchronizing 8 smartphones across diverse scenarios. It comprises 11M frames from 8000 sequences, viewed from different perspectives. These sequences cover 40 subjects across 10 different scenarios, each with varying lighting conditions. We have also established an automated, precise labeling pipeline that allows for large-scale processing efficiently. We provide comprehensive evaluation baselines for a range of tasks, underlining the significant challenges posed by FreeMan. Further evaluations of standard indoor/outdoor human sensing datasets reveal that FreeMan offers robust representation transferability in real and complex scenes. FreeMan is now publicly available at https://wangjiongw.github.io/freeman.
SNEAK: Synonymous Sentences-Aware Adversarial Attack on Natural Language Video Localization
Dec 08, 2021
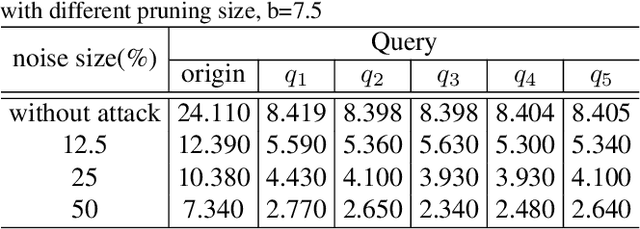

Natural language video localization (NLVL) is an important task in the vision-language understanding area, which calls for an in-depth understanding of not only computer vision and natural language side alone, but more importantly the interplay between both sides. Adversarial vulnerability has been well-recognized as a critical security issue of deep neural network models, which requires prudent investigation. Despite its extensive yet separated studies in video and language tasks, current understanding of the adversarial robustness in vision-language joint tasks like NLVL is less developed. This paper therefore aims to comprehensively investigate the adversarial robustness of NLVL models by examining three facets of vulnerabilities from both attack and defense aspects. To achieve the attack goal, we propose a new adversarial attack paradigm called synonymous sentences-aware adversarial attack on NLVL (SNEAK), which captures the cross-modality interplay between the vision and language sides.