 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTERGAD: Structure-Aware Text-Enhanced Representations for Graph Anomaly Detection
May 19, 2026Graph Anomaly Detection (GAD) aims to identify atypical graph entities, such as nodes, edges, or substructures, that deviate significantly from the majority. While existing text-rich approaches typically integrate structural context into the data representation pipeline using raw textual features, they often neglect the structural context of nodes. This limitation hinders their ability to detect sophisticated anomalies arising from inconsistencies between a node's inherent content and its topological role. To bridge this gap, we propose TERGAD (Structure-aware Text-enhanced Representations for Graph Anomaly Detection), A novel data augmentation framework that enriches structural semantics for GAD via the semantic reasoning capabilities of Large Language Models (LLMs). Specifically, TERGAD translates node-level topological properties into descriptive natural language narratives, which are subsequently processed by an LLM to derive high-level semantic embeddings. These embeddings are then adaptively fused with original node attributes through a gated dual-branch autoencoder to jointly reconstruct both graph structure and node features. The anomaly score is computed based on the integrated reconstruction error, effectively capturing deviations in both observable attributes and LLM-informed semantic expectations. Extensive experiments on six real-world datasets demonstrate that TERGAD consistently outperforms state-of-the-art baselines. Furthermore, our ablation studies validate the indispensable role of structural semantic guidance and the efficacy of the gated fusion mechanism. Code is available at https://github.com/Kantorakitty/TERGAD-main.
FairGC: Fairness-aware Graph Condensation
Mar 30, 2026Graph condensation (GC) has become a vital strategy for scaling Graph Neural Networks by compressing massive datasets into small, synthetic node sets. While current GC methods effectively maintain predictive accuracy, they are primarily designed for utility and often ignore fairness constraints. Because these techniques are bias-blind, they frequently capture and even amplify demographic disparities found in the original data. This leads to synthetic proxies that are unsuitable for sensitive applications like credit scoring or social recommendations. To solve this problem, we introduce FairGC, a unified framework that embeds fairness directly into the graph distillation process. Our approach consists of three key components. First, a Distribution-Preserving Condensation module synchronizes the joint distributions of labels and sensitive attributes to stop bias from spreading. Second, a Spectral Encoding module uses Laplacian eigen-decomposition to preserve essential global structural patterns. Finally, a Fairness-Enhanced Neural Architecture employs multi-domain fusion and a label-smoothing curriculum to produce equitable predictions. Rigorous evaluations on four real-world datasets, show that FairGC provides a superior balance between accuracy and fairness. Our results confirm that FairGC significantly reduces disparity in Statistical Parity and Equal Opportunity compared to existing state-of-the-art condensation models. The codes are available at https://github.com/LuoRenqiang/FairGC.
Bridging Semantic Understanding and Popularity Bias with LLMs
Jan 15, 2026Semantic understanding of popularity bias is a crucial yet underexplored challenge in recommender systems, where popular items are often favored at the expense of niche content. Most existing debiasing methods treat the semantic understanding of popularity bias as a matter of diversity enhancement or long-tail coverage, neglecting the deeper semantic layer that embodies the causal origins of the bias itself. Consequently, such shallow interpretations limit both their debiasing effectiveness and recommendation accuracy. In this paper, we propose FairLRM, a novel framework that bridges the gap in the semantic understanding of popularity bias with Recommendation via Large Language Model (RecLLM). FairLRM decomposes popularity bias into item-side and user-side components, using structured instruction-based prompts to enhance the model's comprehension of both global item distributions and individual user preferences. Unlike traditional methods that rely on surface-level features such as "diversity" or "debiasing", FairLRM improves the model's ability to semantically interpret and address the underlying bias. Through empirical evaluation, we show that FairLRM significantly enhances both fairness and recommendation accuracy, providing a more semantically aware and trustworthy approach to enhance the semantic understanding of popularity bias. The implementation is available at https://github.com/LuoRenqiang/FairLRM.
A Motion Assessment Method for Reference Stack Selection in Fetal Brain MRI Reconstruction Based on Tensor Rank Approximation
Jun 30, 2023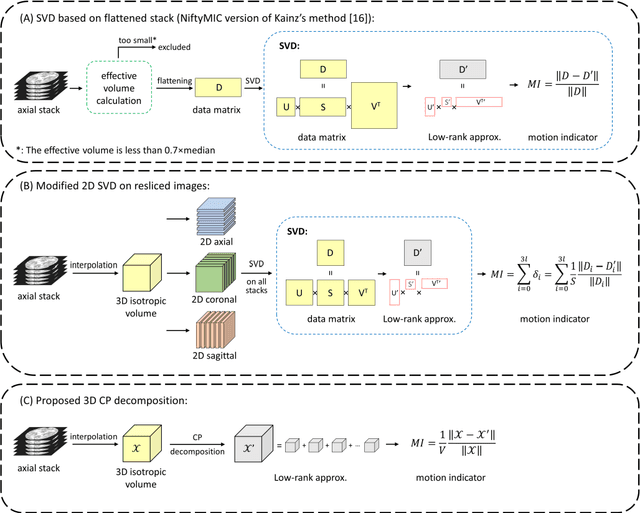
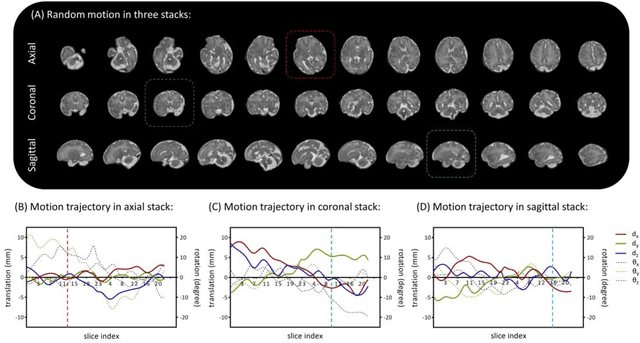
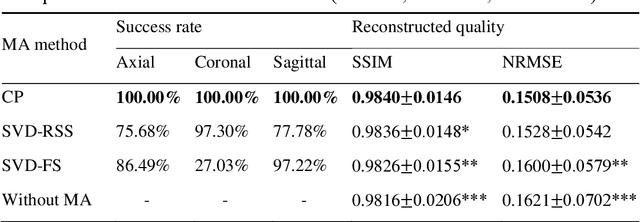
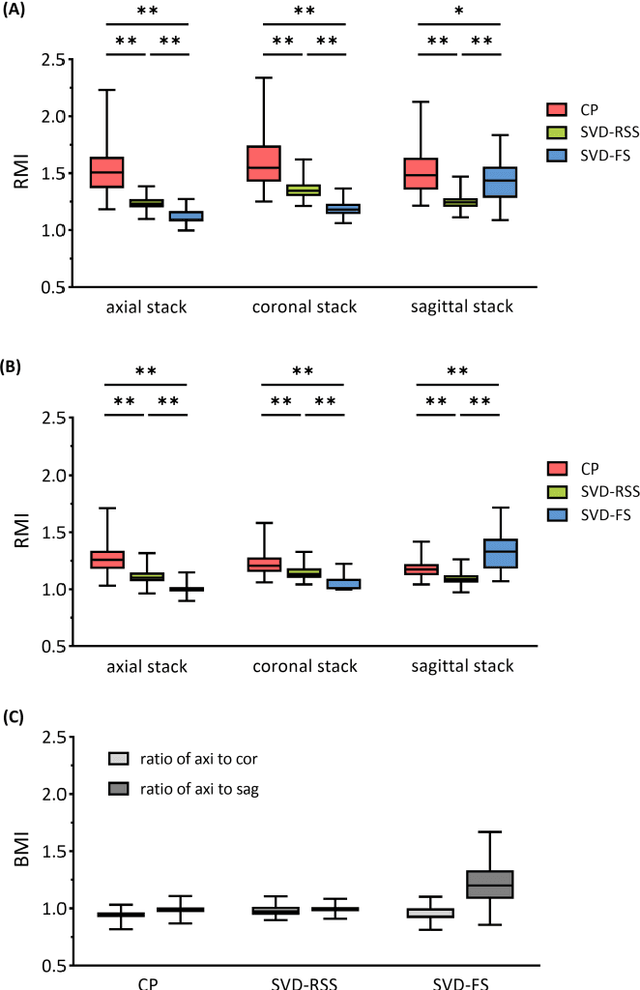
Purpose: Slice-to-volume registration and super-resolution reconstruction (SVR-SRR) is commonly used to generate 3D volumes of the fetal brain from 2D stacks of slices acquired in multiple orientations. A critical initial step in this pipeline is to select one stack with the minimum motion as a reference for registration. An accurate and unbiased motion assessment (MA) is thus crucial for successful selection. Methods: We presented a MA method that determines the minimum motion stack based on 3D low-rank approximation using CANDECOMP/PARAFAC (CP) decomposition. Compared to the current 2D singular value decomposition (SVD) based method that requires flattening stacks into matrices to obtain ranks, in which the spatial information is lost, the CP-based method can factorize 3D stack into low-rank and sparse components in a computationally efficient manner. The difference between the original stack and its low-rank approximation was proposed as the motion indicator. Results: Compared to SVD-based methods, our proposed CP-based MA demonstrated higher sensitivity in detecting small motion with a lower baseline bias. Experiments on randomly simulated motion illustrated that the proposed CP method achieved a higher success rate of 95.45% in identifying the minimum motion stack, compared to SVD-based method with a success rate of 58.18%. We further demonstrated that combining CP-based MA with existing SRR-SVR pipeline significantly improved 3D volume reconstruction. Conclusion: The proposed CP-based MA method showed superior performance compared to SVD-based methods with higher sensitivity to motion, success rate, and lower baseline bias, and can be used as a prior step to improve fetal brain reconstruction.
A microstructure estimation Transformer inspired by sparse representation for diffusion MRI
May 13, 2022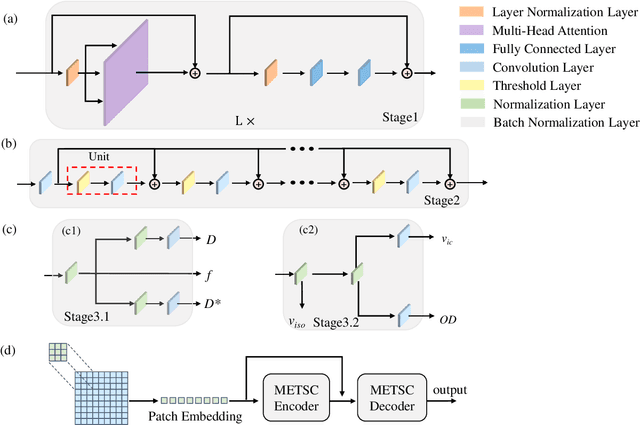
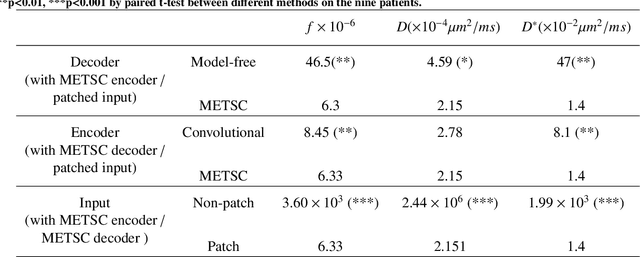
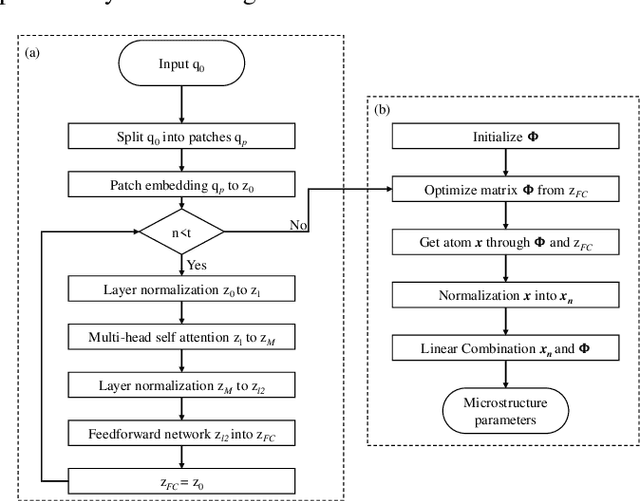

Diffusion magnetic resonance imaging (dMRI) is an important tool in characterizing tissue microstructure based on biophysical models, which are complex and highly non-linear. Resolving microstructures with optimization techniques is prone to estimation errors and requires dense sampling in the q-space. Deep learning based approaches have been proposed to overcome these limitations. Motivated by the superior performance of the Transformer, in this work, we present a learning-based framework based on Transformer, namely, a Microstructure Estimation Transformer with Sparse Coding (METSC) for dMRI-based microstructure estimation with downsampled q-space data. To take advantage of the Transformer while addressing its limitation in large training data requirements, we explicitly introduce an inductive bias - model bias into the Transformer using a sparse coding technique to facilitate the training process. Thus, the METSC is composed with three stages, an embedding stage, a sparse representation stage, and a mapping stage. The embedding stage is a Transformer-based structure that encodes the signal to ensure the voxel is represented effectively. In the sparse representation stage, a dictionary is constructed by solving a sparse reconstruction problem that unfolds the Iterative Hard Thresholding (IHT) process. The mapping stage is essentially a decoder that computes the microstructural parameters from the output of the second stage, based on the weighted sum of normalized dictionary coefficients where the weights are also learned. We tested our framework on two dMRI models with downsampled q-space data, including the intravoxel incoherent motion (IVIM) model and the neurite orientation dispersion and density imaging (NODDI) model. The proposed method achieved up to 11.25 folds of acceleration in scan time and outperformed the other state-of-the-art learning-based methods.
AFFIRM: Affinity Fusion-based Framework for Iteratively Random Motion correction of multi-slice fetal brain MRI
May 12, 2022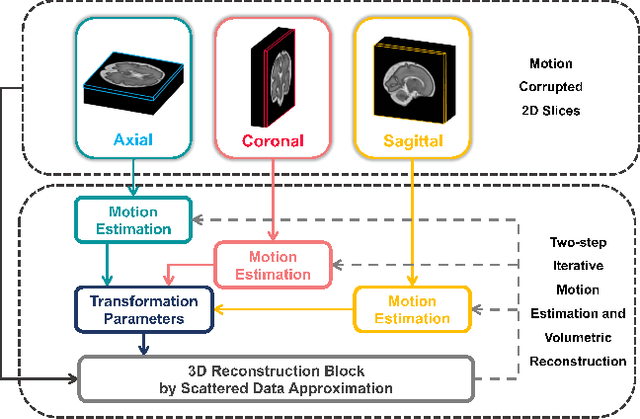
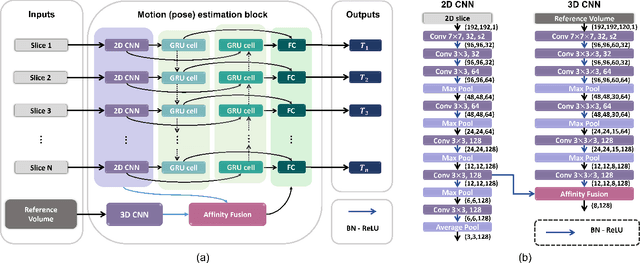
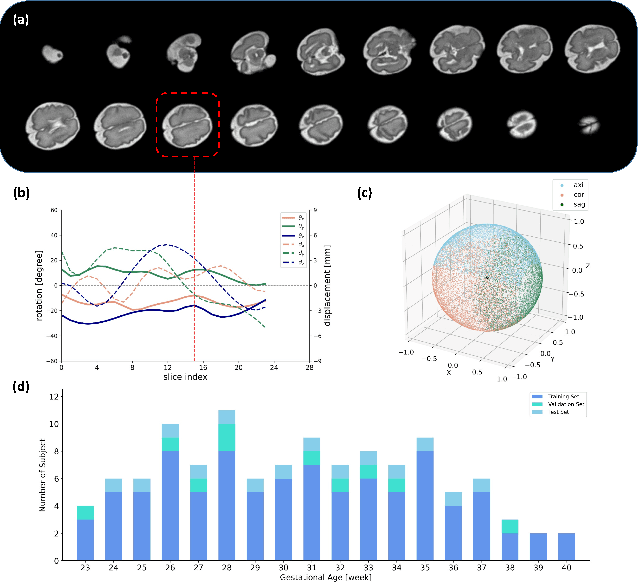
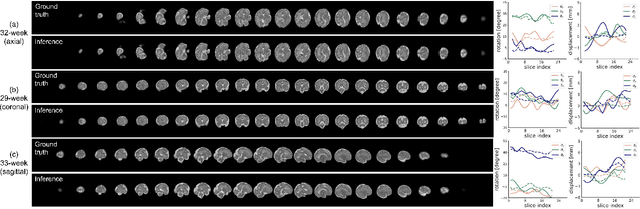
Multi-slice magnetic resonance images of the fetal brain are usually contaminated by severe and arbitrary fetal and maternal motion. Hence, stable and robust motion correction is necessary to reconstruct high-resolution 3D fetal brain volume for clinical diagnosis and quantitative analysis. However, the conventional registration-based correction has a limited capture range and is insufficient for detecting relatively large motions. Here, we present a novel Affinity Fusion-based Framework for Iteratively Random Motion (AFFIRM) correction of the multi-slice fetal brain MRI. It learns the sequential motion from multiple stacks of slices and integrates the features between 2D slices and reconstructed 3D volume using affinity fusion, which resembles the iterations between slice-to-volume registration and volumetric reconstruction in the regular pipeline. The method accurately estimates the motion regardless of brain orientations and outperforms other state-of-the-art learning-based methods on the simulated motion-corrupted data, with a 48.4% reduction of mean absolute error for rotation and 61.3% for displacement. We then incorporated AFFIRM into the multi-resolution slice-to-volume registration and tested it on the real-world fetal MRI scans at different gestation stages. The results indicated that adding AFFIRM to the conventional pipeline improved the success rate of fetal brain super-resolution reconstruction from 77.2% to 91.9%.
SNEAK: Synonymous Sentences-Aware Adversarial Attack on Natural Language Video Localization
Dec 08, 2021
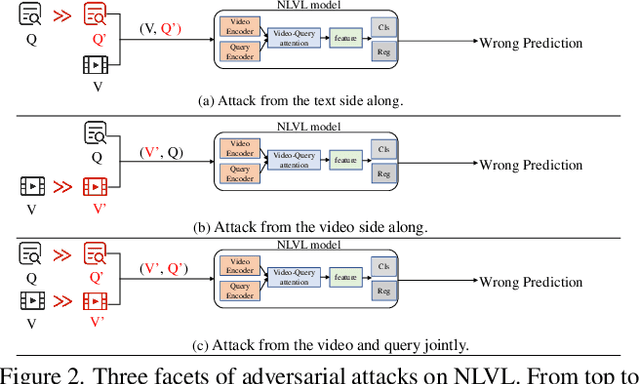

Natural language video localization (NLVL) is an important task in the vision-language understanding area, which calls for an in-depth understanding of not only computer vision and natural language side alone, but more importantly the interplay between both sides. Adversarial vulnerability has been well-recognized as a critical security issue of deep neural network models, which requires prudent investigation. Despite its extensive yet separated studies in video and language tasks, current understanding of the adversarial robustness in vision-language joint tasks like NLVL is less developed. This paper therefore aims to comprehensively investigate the adversarial robustness of NLVL models by examining three facets of vulnerabilities from both attack and defense aspects. To achieve the attack goal, we propose a new adversarial attack paradigm called synonymous sentences-aware adversarial attack on NLVL (SNEAK), which captures the cross-modality interplay between the vision and language sides.