 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePATMAT: Person Aware Tuning of Mask-Aware Transformer for Face Inpainting
Paper and Code
Apr 12, 2023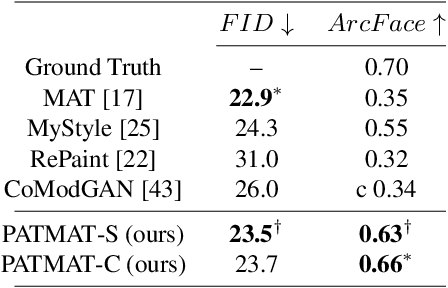
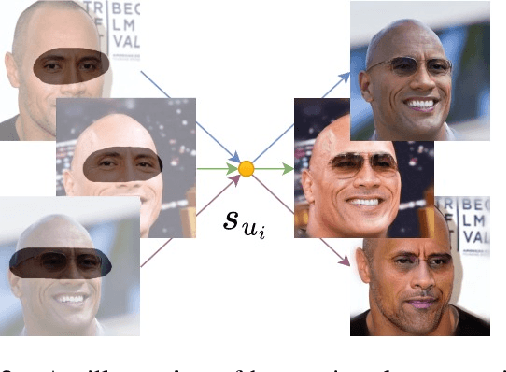
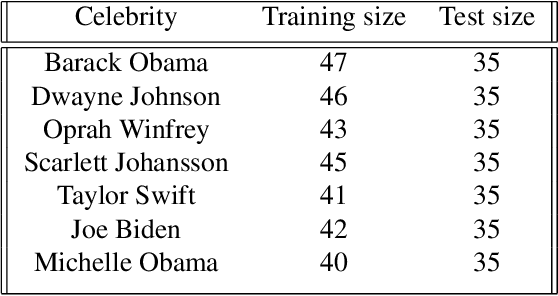

Generative models such as StyleGAN2 and Stable Diffusion have achieved state-of-the-art performance in computer vision tasks such as image synthesis, inpainting, and de-noising. However, current generative models for face inpainting often fail to preserve fine facial details and the identity of the person, despite creating aesthetically convincing image structures and textures. In this work, we propose Person Aware Tuning (PAT) of Mask-Aware Transformer (MAT) for face inpainting, which addresses this issue. Our proposed method, PATMAT, effectively preserves identity by incorporating reference images of a subject and fine-tuning a MAT architecture trained on faces. By using ~40 reference images, PATMAT creates anchor points in MAT's style module, and tunes the model using the fixed anchors to adapt the model to a new face identity. Moreover, PATMAT's use of multiple images per anchor during training allows the model to use fewer reference images than competing methods. We demonstrate that PATMAT outperforms state-of-the-art models in terms of image quality, the preservation of person-specific details, and the identity of the subject. Our results suggest that PATMAT can be a promising approach for improving the quality of personalized face inpainting.