 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYuFeng-XGuard: A Reasoning-Centric, Interpretable, and Flexible Guardrail Model for Large Language Models
Jan 22, 2026As large language models (LLMs) are increasingly deployed in real-world applications, safety guardrails are required to go beyond coarse-grained filtering and support fine-grained, interpretable, and adaptable risk assessment. However, existing solutions often rely on rapid classification schemes or post-hoc rules, resulting in limited transparency, inflexible policies, or prohibitive inference costs. To this end, we present YuFeng-XGuard, a reasoning-centric guardrail model family designed to perform multi-dimensional risk perception for LLM interactions. Instead of producing opaque binary judgments, YuFeng-XGuard generates structured risk predictions, including explicit risk categories and configurable confidence scores, accompanied by natural language explanations that expose the underlying reasoning process. This formulation enables safety decisions that are both actionable and interpretable. To balance decision latency and explanatory depth, we adopt a tiered inference paradigm that performs an initial risk decision based on the first decoded token, while preserving ondemand explanatory reasoning when required. In addition, we introduce a dynamic policy mechanism that decouples risk perception from policy enforcement, allowing safety policies to be adjusted without model retraining. Extensive experiments on a diverse set of public safety benchmarks demonstrate that YuFeng-XGuard achieves stateof-the-art performance while maintaining strong efficiency-efficacy trade-offs. We release YuFeng-XGuard as an open model family, including both a full-capacity variant and a lightweight version, to support a wide range of deployment scenarios.
Revisiting Multi-modal 3D Semantic Segmentation in Real-world Autonomous Driving
Oct 13, 2023LiDAR and camera are two critical sensors for multi-modal 3D semantic segmentation and are supposed to be fused efficiently and robustly to promise safety in various real-world scenarios. However, existing multi-modal methods face two key challenges: 1) difficulty with efficient deployment and real-time execution; and 2) drastic performance degradation under weak calibration between LiDAR and cameras. To address these challenges, we propose CPGNet-LCF, a new multi-modal fusion framework extending the LiDAR-only CPGNet. CPGNet-LCF solves the first challenge by inheriting the easy deployment and real-time capabilities of CPGNet. For the second challenge, we introduce a novel weak calibration knowledge distillation strategy during training to improve the robustness against the weak calibration. CPGNet-LCF achieves state-of-the-art performance on the nuScenes and SemanticKITTI benchmarks. Remarkably, it can be easily deployed to run in 20ms per frame on a single Tesla V100 GPU using TensorRT TF16 mode. Furthermore, we benchmark performance over four weak calibration levels, demonstrating the robustness of our proposed approach.
D^2ETR: Decoder-Only DETR with Computationally Efficient Cross-Scale Attention
Mar 02, 2022
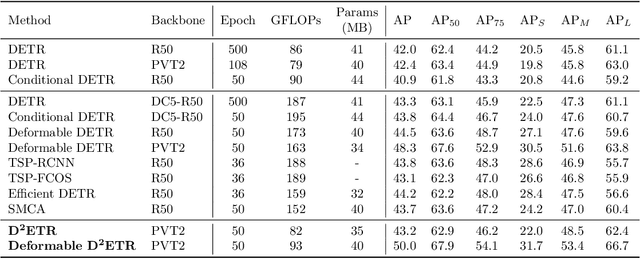
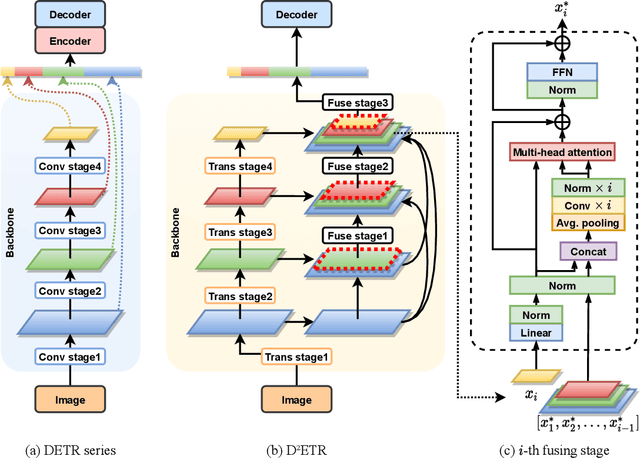
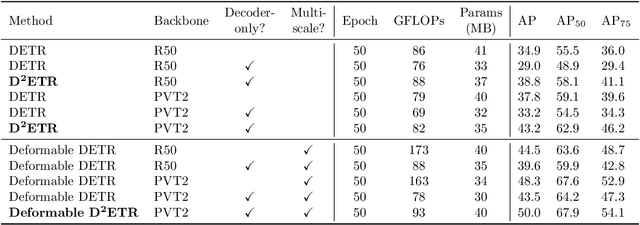
DETR is the first fully end-to-end detector that predicts a final set of predictions without post-processing. However, it suffers from problems such as low performance and slow convergence. A series of works aim to tackle these issues in different ways, but the computational cost is yet expensive due to the sophisticated encoder-decoder architecture. To alleviate this issue, we propose a decoder-only detector called D^2ETR. In the absence of encoder, the decoder directly attends to the fine-fused feature maps generated by the Transformer backbone with a novel computationally efficient cross-scale attention module. D^2ETR demonstrates low computational complexity and high detection accuracy in evaluations on the COCO benchmark, outperforming DETR and its variants.
Black-box Adversarial Sample Generation Based on Differential Evolution
Jul 30, 2020
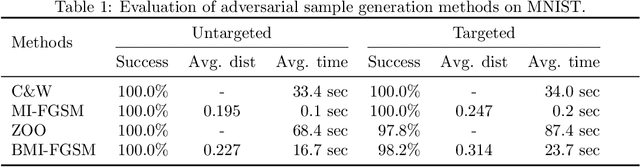
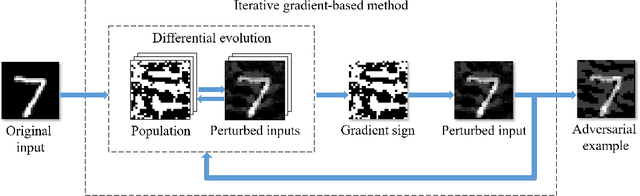
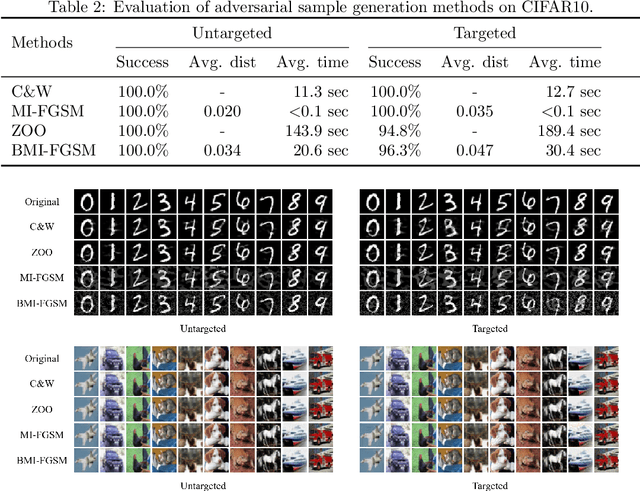
Deep Neural Networks (DNNs) are being used in various daily tasks such as object detection, speech processing, and machine translation. However, it is known that DNNs suffer from robustness problems -- perturbed inputs called adversarial samples leading to misbehaviors of DNNs. In this paper, we propose a black-box technique called Black-box Momentum Iterative Fast Gradient Sign Method (BMI-FGSM) to test the robustness of DNN models. The technique does not require any knowledge of the structure or weights of the target DNN. Compared to existing white-box testing techniques that require accessing model internal information such as gradients, our technique approximates gradients through Differential Evolution and uses approximated gradients to construct adversarial samples. Experimental results show that our technique can achieve 100% success in generating adversarial samples to trigger misclassification, and over 95% success in generating samples to trigger misclassification to a specific target output label. It also demonstrates better perturbation distance and better transferability. Compared to the state-of-the-art black-box technique, our technique is more efficient. Furthermore, we conduct testing on the commercial Aliyun API and successfully trigger its misbehavior within a limited number of queries, demonstrating the feasibility of real-world black-box attack.