 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeD^2ETR: Decoder-Only DETR with Computationally Efficient Cross-Scale Attention
Paper and Code
Mar 02, 2022
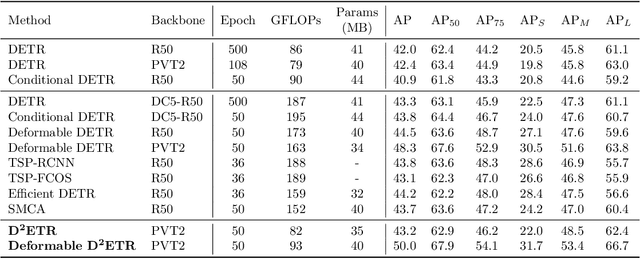
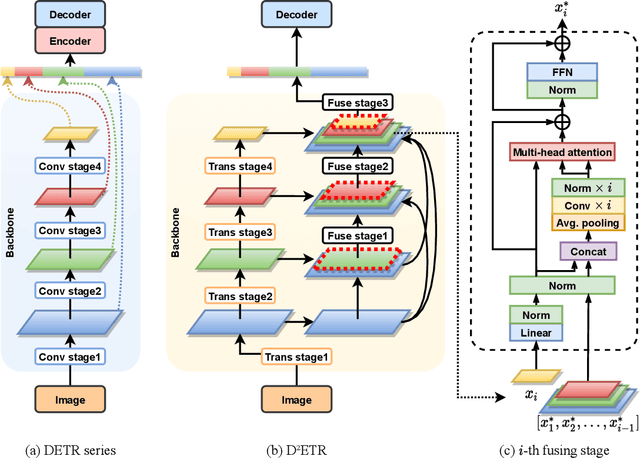
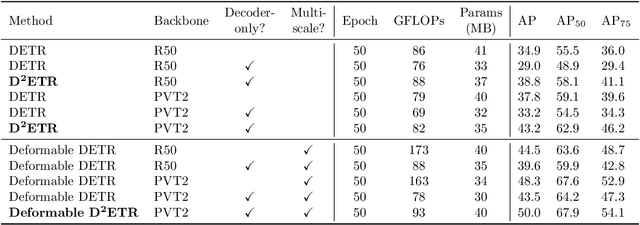
DETR is the first fully end-to-end detector that predicts a final set of predictions without post-processing. However, it suffers from problems such as low performance and slow convergence. A series of works aim to tackle these issues in different ways, but the computational cost is yet expensive due to the sophisticated encoder-decoder architecture. To alleviate this issue, we propose a decoder-only detector called D^2ETR. In the absence of encoder, the decoder directly attends to the fine-fused feature maps generated by the Transformer backbone with a novel computationally efficient cross-scale attention module. D^2ETR demonstrates low computational complexity and high detection accuracy in evaluations on the COCO benchmark, outperforming DETR and its variants.