 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Subjective Time-Series Data via Utopia Label Distribution Approximation
Paper and Code
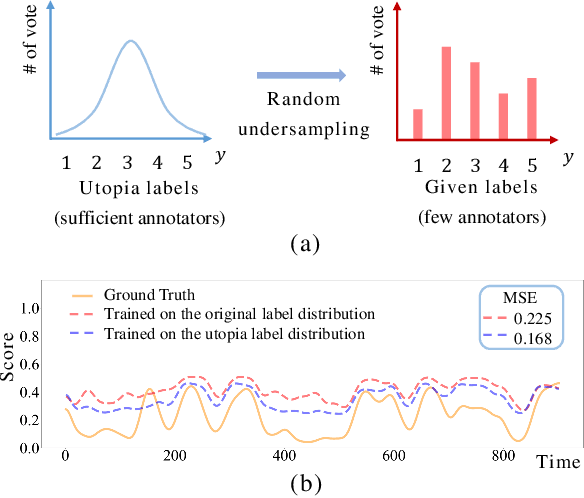
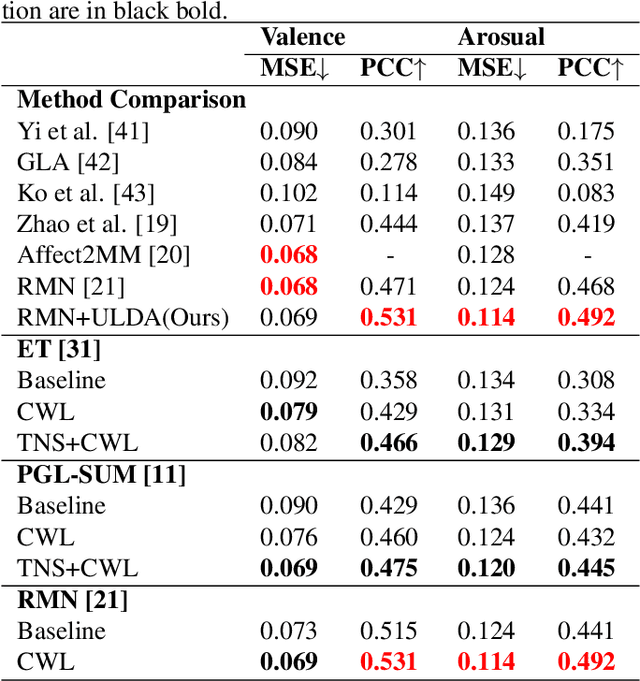
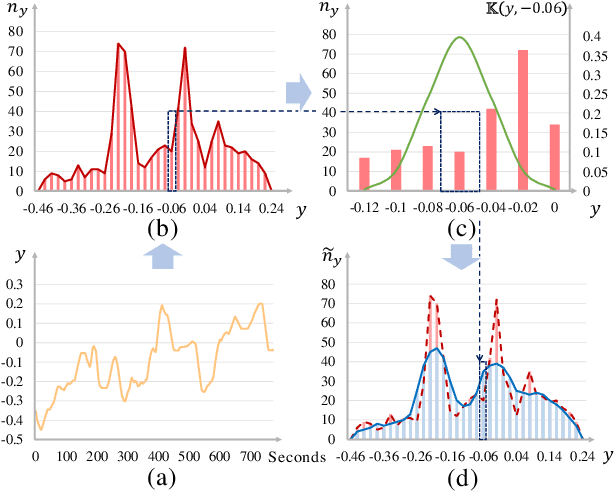
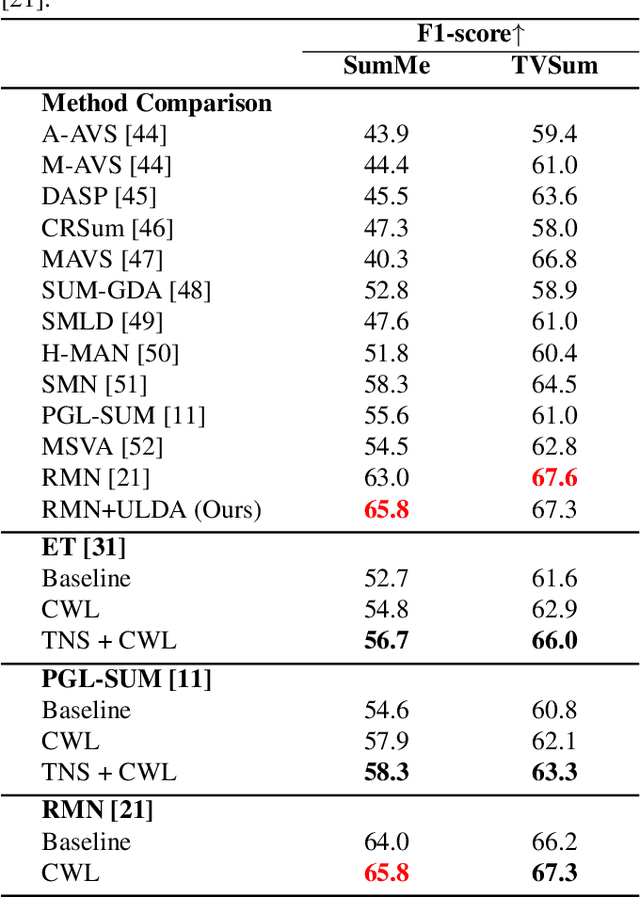
Subjective time-series regression (STR) tasks have gained increasing attention recently. However, most existing methods overlook the label distribution bias in STR data, which results in biased models. Emerging studies on imbalanced regression tasks, such as age estimation and depth estimation, hypothesize that the prior label distribution of the dataset is uniform. However, we observe that the label distributions of training and test sets in STR tasks are likely to be neither uniform nor identical. This distinct feature calls for new approaches that estimate more reasonable distributions to train a fair model. In this work, we propose Utopia Label Distribution Approximation (ULDA) for time-series data, which makes the training label distribution closer to real-world but unknown (utopia) label distribution. This would enhance the model's fairness. Specifically, ULDA first convolves the training label distribution by a Gaussian kernel. After convolution, the required sample quantity at each regression label may change. We further devise the Time-slice Normal Sampling (TNS) to generate new samples when the required sample quantity is greater than the initial sample quantity, and the Convolutional Weighted Loss (CWL) to lower the sample weight when the required sample quantity is less than the initial quantity. These two modules not only assist the model training on the approximated utopia label distribution, but also maintain the sample continuity in temporal context space. To the best of our knowledge, ULDA is the first method to address the label distribution bias in time-series data. Extensive experiments demonstrate that ULDA lifts the state-of-the-art performance on two STR tasks and three benchmark datasets.