 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEconomic Policy Uncertainty: A Review on Applications and Measurement Methods with Focus on Text Mining Methods
Aug 20, 2023Economic Policy Uncertainty (EPU) represents the uncertainty realized by the investors during economic policy alterations. EPU is a critical indicator in economic studies to predict future investments, the unemployment rate, and recessions. EPU values can be estimated based on financial parameters directly or implied uncertainty indirectly using the text mining methods. Although EPU is a well-studied topic within the economy, the methods utilized to measure it are understudied. In this article, we define the EPU briefly and review the methods used to measure the EPU, and survey the areas influenced by the changes in EPU level. We divide the EPU measurement methods into three major groups with respect to their input data. Examples of each group of methods are enlisted, and the pros and cons of the groups are discussed. Among the EPU measures, text mining-based ones are dominantly studied. These methods measure the realized uncertainty by taking into account the uncertainty represented in the news and publicly available sources of financial information. Finally, we survey the research areas that rely on measuring the EPU index with the hope that studying the impacts of uncertainty would attract further attention of researchers from various research fields. In addition, we propose a list of future research approaches focusing on measuring EPU using textual material.
Measuring Economic Policy Uncertainty Using an Unsupervised Word Embedding-based Method
May 10, 2021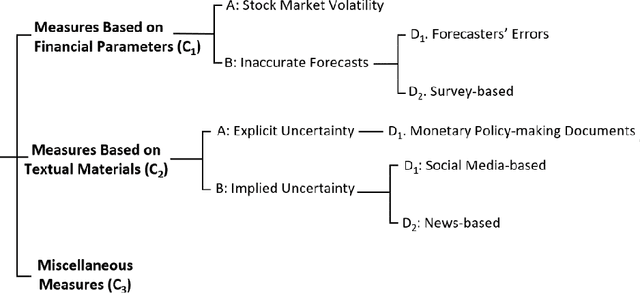
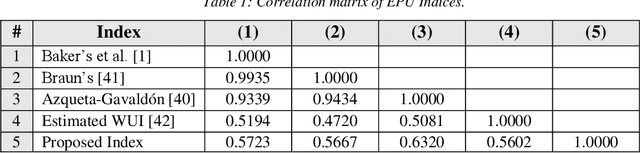

Economic Policy Uncertainty (EPU) is a critical indicator in economic studies, while it can be used to forecast a recession. Under higher levels of uncertainty, firms' owners cut their investment, which leads to a longer post-recession recovery. EPU index is computed by counting news articles containing pre-defined keywords related to policy-making and economy and convey uncertainty. Unfortunately, this method is sensitive to the original keyword set, its richness, and the news coverage. Thus, reproducing its results for different countries is challenging. In this paper, we propose an unsupervised text mining method that uses word-embedding representation space to select relevant keywords. This method is not strictly sensitive to the semantic similarity threshold applied to the word embedding vectors and does not require a pre-defined dictionary. Our experiments using a massive repository of Persian news show that the EPU series computed by the proposed method precisely follows major events affecting Iran's economy and is compatible with the World Uncertainty Index (WUI) of Iran.
Iterative Nearest Neighborhood Oversampling in Semisupervised Learning from Imbalanced Data
Dec 24, 2013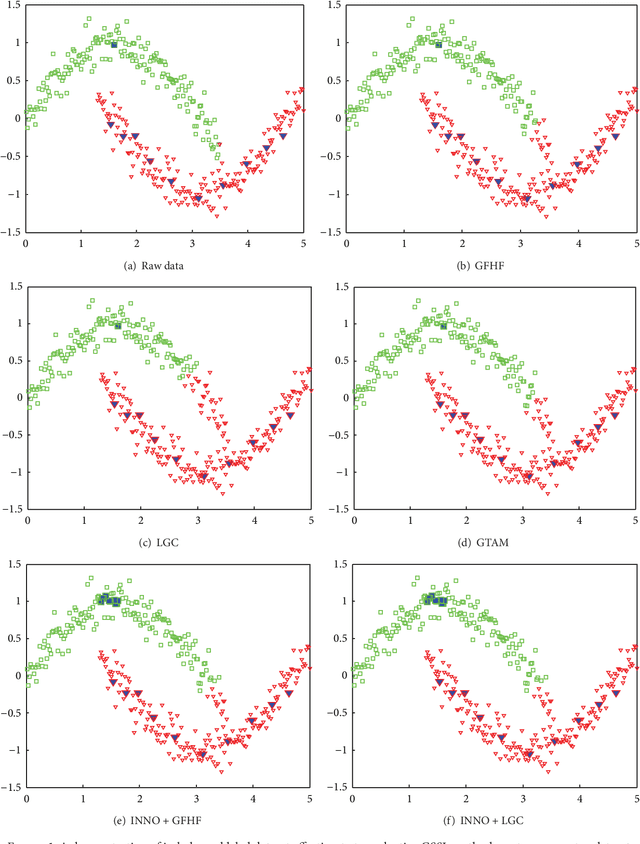


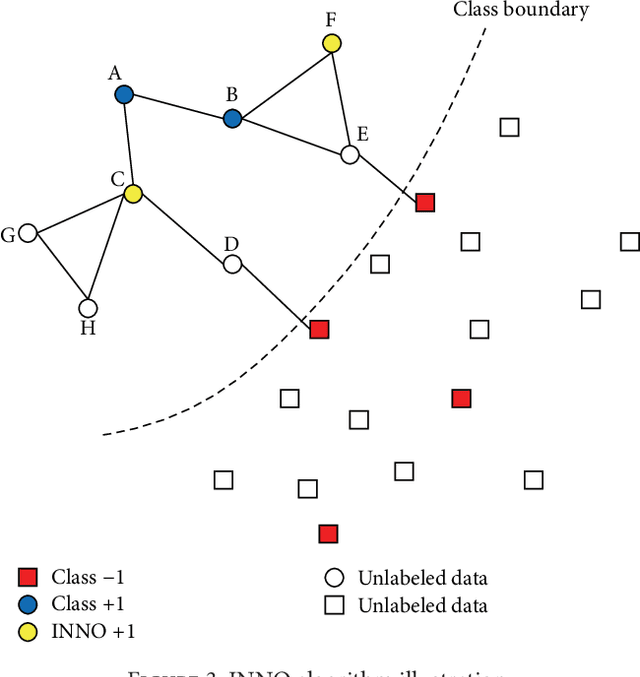
Transductive graph-based semi-supervised learning methods usually build an undirected graph utilizing both labeled and unlabeled samples as vertices. Those methods propagate label information of labeled samples to neighbors through their edges in order to get the predicted labels of unlabeled samples. Most popular semi-supervised learning approaches are sensitive to initial label distribution happened in imbalanced labeled datasets. The class boundary will be severely skewed by the majority classes in an imbalanced classification. In this paper, we proposed a simple and effective approach to alleviate the unfavorable influence of imbalance problem by iteratively selecting a few unlabeled samples and adding them into the minority classes to form a balanced labeled dataset for the learning methods afterwards. The experiments on UCI datasets and MNIST handwritten digits dataset showed that the proposed approach outperforms other existing state-of-art methods.