 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring Economic Policy Uncertainty Using an Unsupervised Word Embedding-based Method
Paper and Code
May 10, 2021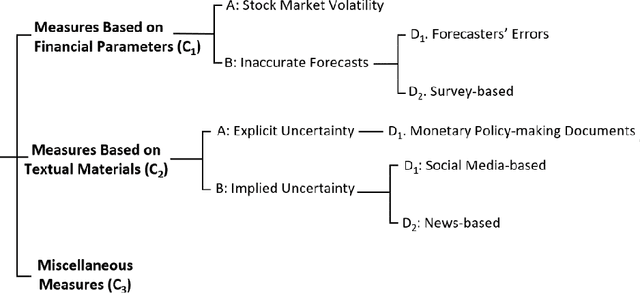

Economic Policy Uncertainty (EPU) is a critical indicator in economic studies, while it can be used to forecast a recession. Under higher levels of uncertainty, firms' owners cut their investment, which leads to a longer post-recession recovery. EPU index is computed by counting news articles containing pre-defined keywords related to policy-making and economy and convey uncertainty. Unfortunately, this method is sensitive to the original keyword set, its richness, and the news coverage. Thus, reproducing its results for different countries is challenging. In this paper, we propose an unsupervised text mining method that uses word-embedding representation space to select relevant keywords. This method is not strictly sensitive to the semantic similarity threshold applied to the word embedding vectors and does not require a pre-defined dictionary. Our experiments using a massive repository of Persian news show that the EPU series computed by the proposed method precisely follows major events affecting Iran's economy and is compatible with the World Uncertainty Index (WUI) of Iran.