 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVerified Multi-Step Synthesis using Large Language Models and Monte Carlo Tree Search
Feb 13, 2024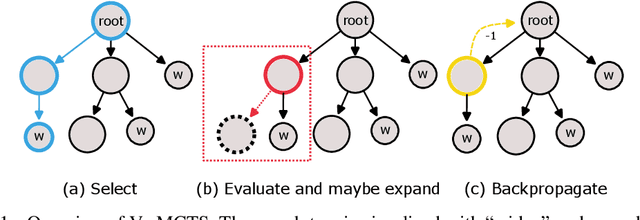
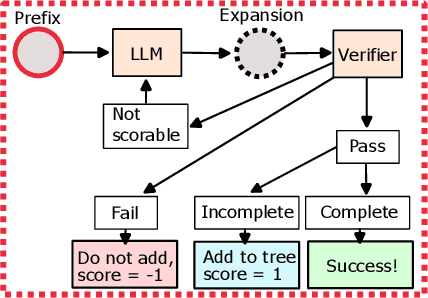
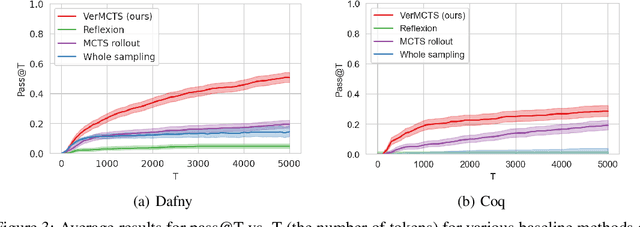
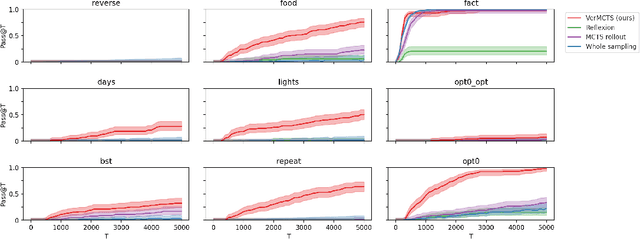
We present an approach using Monte Carlo Tree Search (MCTS) to guide Large Language Models (LLMs) to generate verified programs in Dafny, Lean and Coq. Our method, which we call VMCTS, leverages the verifier inside the search algorithm by checking partial programs at each step. In combination with the LLM prior, the verifier feedback raises the synthesis capabilities of open source models. On a set of five verified programming problems, we find that in four problems where the base model cannot solve the question even when re-sampling solutions for one hour, VMCTS can solve the problems within 6 minutes. The base model with VMCTS is even competitive with ChatGPT4 augmented with plugins and multiple re-tries on these problems. Our code and benchmarks are available at https://github.com/namin/llm-verified-with-monte-carlo-tree-search .
Amortized Rejection Sampling in Universal Probabilistic Programming
Nov 30, 2019
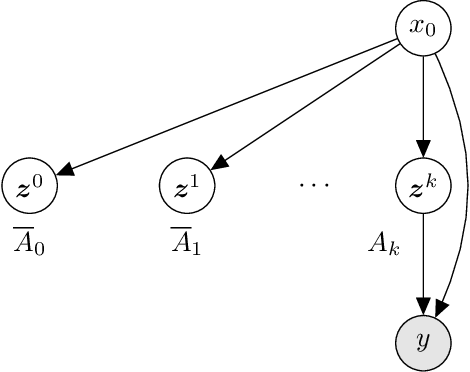
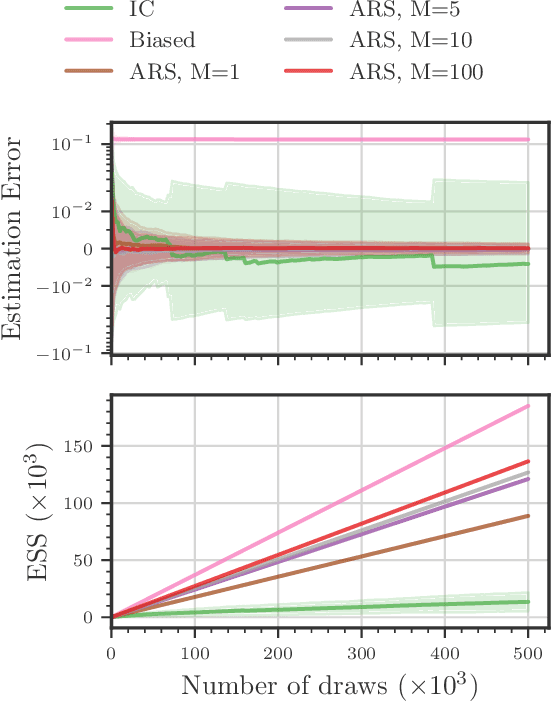
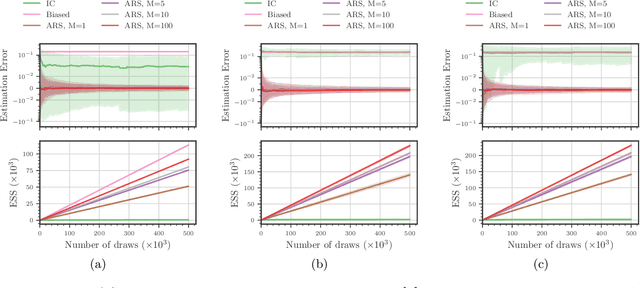
Existing approaches to amortized inference in probabilistic programs with unbounded loops can produce estimators with infinite variance. An instance of this is importance sampling inference in programs that explicitly include rejection sampling as part of the user-programmed generative procedure. In this paper we develop a new and efficient amortized importance sampling estimator. We prove finite variance of our estimator and empirically demonstrate our method's correctness and efficiency compared to existing alternatives on generative programs containing rejection sampling loops and discuss how to implement our method in a generic probabilistic programming framework.
Faithful Inversion of Generative Models for Effective Amortized Inference
Oct 24, 2018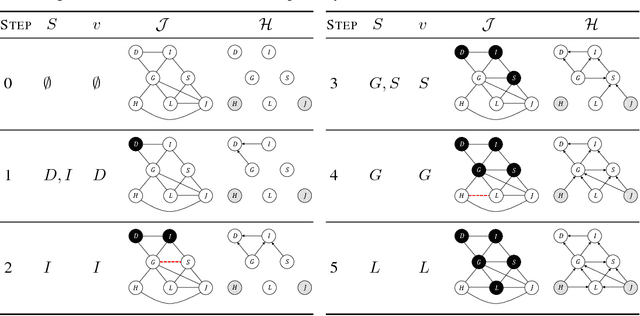
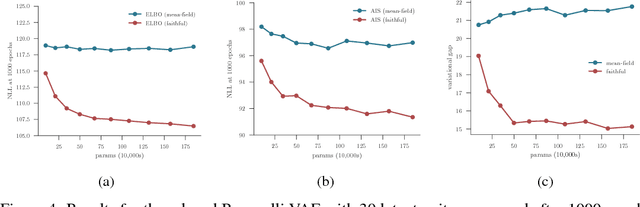

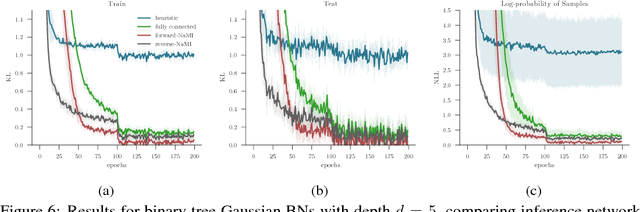
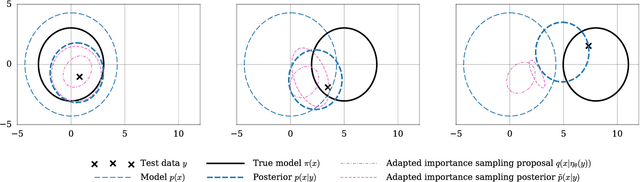
Inference amortization methods share information across multiple posterior-inference problems, allowing each to be carried out more efficiently. Generally, they require the inversion of the dependency structure in the generative model, as the modeller must learn a mapping from observations to distributions approximating the posterior. Previous approaches have involved inverting the dependency structure in a heuristic way that fails to capture these dependencies correctly, thereby limiting the achievable accuracy of the resulting approximations. We introduce an algorithm for faithfully, and minimally, inverting the graphical model structure of any generative model. Such inverses have two crucial properties: (a) they do not encode any independence assertions that are absent from the model and; (b) they are local maxima for the number of true independencies encoded. We prove the correctness of our approach and empirically show that the resulting minimally faithful inverses lead to better inference amortization than existing heuristic approaches.
Composing inference algorithms as program transformations
Jul 12, 2017


Probabilistic inference procedures are usually coded painstakingly from scratch, for each target model and each inference algorithm. We reduce this effort by generating inference procedures from models automatically. We make this code generation modular by decomposing inference algorithms into reusable program-to-program transformations. These transformations perform exact inference as well as generate probabilistic programs that compute expectations, densities, and MCMC samples. The resulting inference procedures are about as accurate and fast as other probabilistic programming systems on real-world problems.
Using Synthetic Data to Train Neural Networks is Model-Based Reasoning
Mar 02, 2017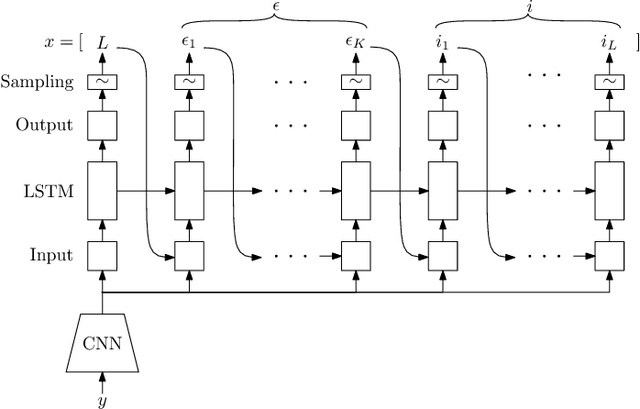

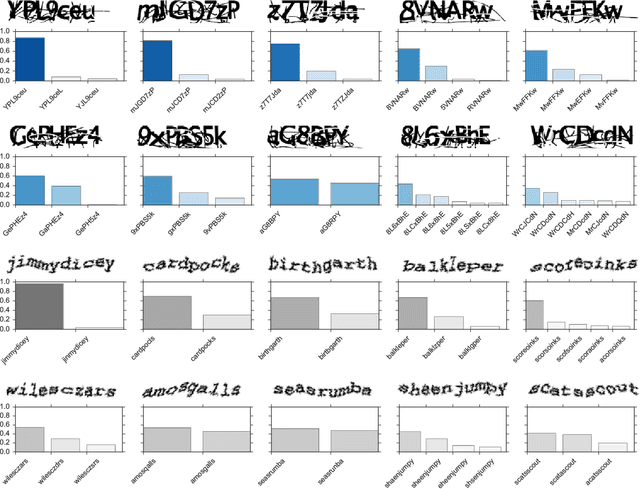
We draw a formal connection between using synthetic training data to optimize neural network parameters and approximate, Bayesian, model-based reasoning. In particular, training a neural network using synthetic data can be viewed as learning a proposal distribution generator for approximate inference in the synthetic-data generative model. We demonstrate this connection in a recognition task where we develop a novel Captcha-breaking architecture and train it using synthetic data, demonstrating both state-of-the-art performance and a way of computing task-specific posterior uncertainty. Using a neural network trained this way, we also demonstrate successful breaking of real-world Captchas currently used by Facebook and Wikipedia. Reasoning from these empirical results and drawing connections with Bayesian modeling, we discuss the robustness of synthetic data results and suggest important considerations for ensuring good neural network generalization when training with synthetic data.