 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTranslating Recursive Probabilistic Programs to Factor Graph Grammars
Oct 22, 2020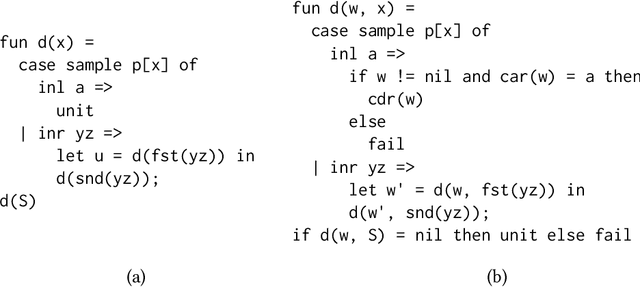
It is natural for probabilistic programs to use conditionals to express alternative substructures in models, and loops (recursion) to express repeated substructures in models. Thus, probabilistic programs with conditionals and recursion motivate ongoing interest in efficient and general inference. A factor graph grammar (FGG) generates a set of factor graphs that do not all need to be enumerated in order to perform inference. We provide a semantics-preserving translation from first-order probabilistic programs with conditionals and recursion to FGGs.
Composing inference algorithms as program transformations
Jul 12, 2017


Probabilistic inference procedures are usually coded painstakingly from scratch, for each target model and each inference algorithm. We reduce this effort by generating inference procedures from models automatically. We make this code generation modular by decomposing inference algorithms into reusable program-to-program transformations. These transformations perform exact inference as well as generate probabilistic programs that compute expectations, densities, and MCMC samples. The resulting inference procedures are about as accurate and fast as other probabilistic programming systems on real-world problems.
Monolingual Probabilistic Programming Using Generalized Coroutines
May 09, 2012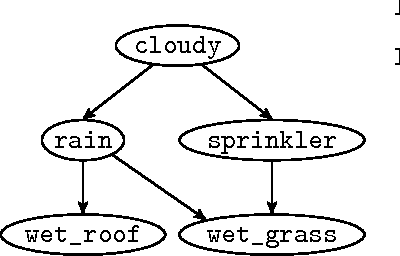
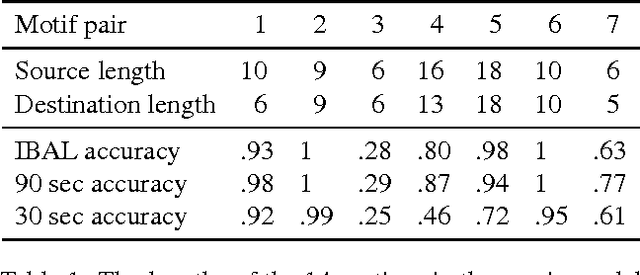
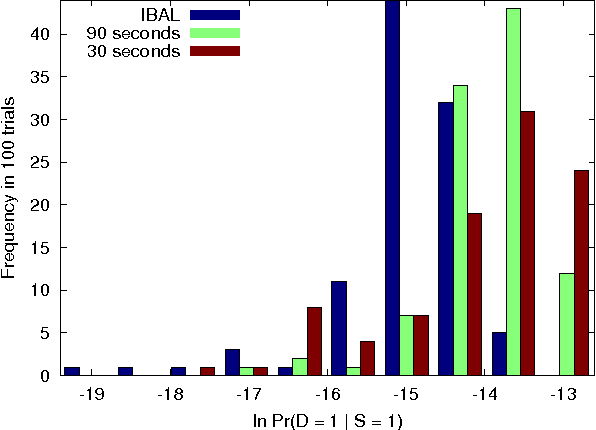
Probabilistic programming languages and modeling toolkits are two modular ways to build and reuse stochastic models and inference procedures. Combining strengths of both, we express models and inference as generalized coroutines in the same general-purpose language. We use existing facilities of the language, such as rich libraries, optimizing compilers, and types, to develop concise, declarative, and realistic models with competitive performance on exact and approximate inference. In particular, a wide range of models can be expressed using memoization. Because deterministic parts of models run at full speed, custom inference procedures are trivial to incorporate, and inference procedures can reason about themselves without interpretive overhead. Within this framework, we introduce a new, general algorithm for importance sampling with look-ahead.
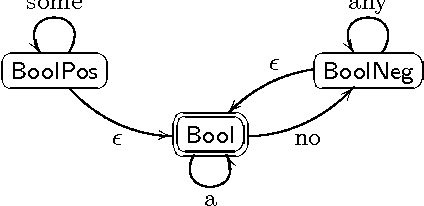
Polarity sensitivity and evaluation order in type-logical grammar
Apr 05, 2004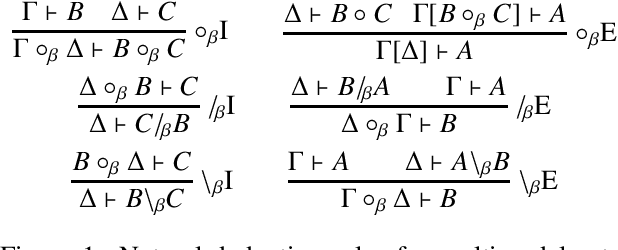



We present a novel, type-logical analysis of_polarity sensitivity_: how negative polarity items (like "any" and "ever") or positive ones (like "some") are licensed or prohibited. It takes not just scopal relations but also linear order into account, using the programming-language notions of delimited continuations and evaluation order, respectively. It thus achieves greater empirical coverage than previous proposals.
* 4 pages
Delimited continuations in natural language: quantification and polarity sensitivity
Apr 05, 2004


Making a linguistic theory is like making a programming language: one typically devises a type system to delineate the acceptable utterances and a denotational semantics to explain observations on their behavior. Via this connection, the programming language concept of delimited continuations can help analyze natural language phenomena such as quantification and polarity sensitivity. Using a logical metalanguage whose syntax includes control operators and whose semantics involves evaluation order, these analyses can be expressed in direct style rather than continuation-passing style, and these phenomena can be thought of as computational side effects.
* 10 pages
A continuation semantics of interrogatives that accounts for Baker's ambiguity
Jul 25, 2003
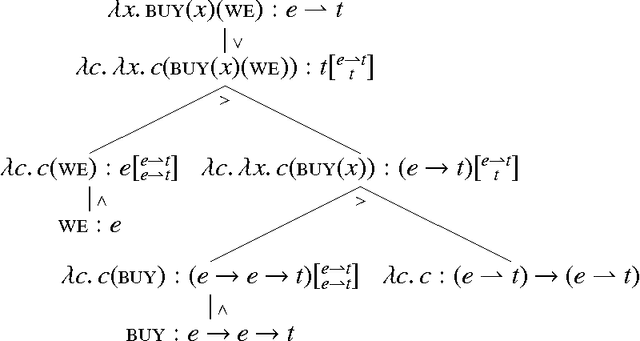
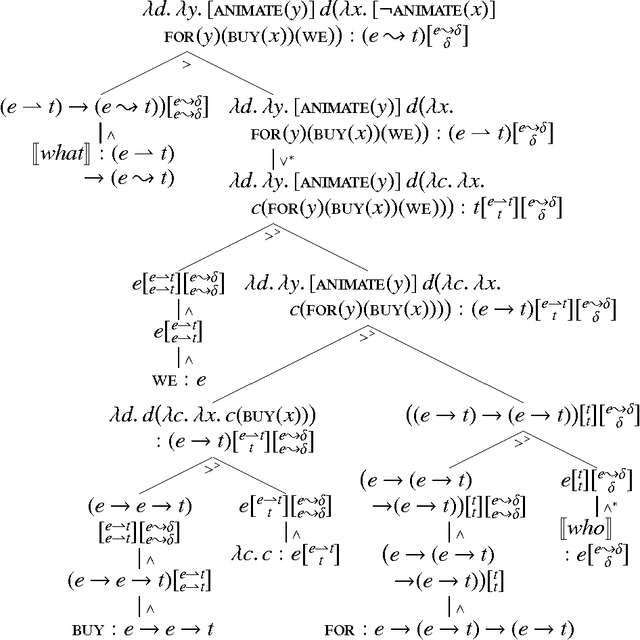
Wh-phrases in English can appear both raised and in-situ. However, only in-situ wh-phrases can take semantic scope beyond the immediately enclosing clause. I present a denotational semantics of interrogatives that naturally accounts for these two properties. It neither invokes movement or economy, nor posits lexical ambiguity between raised and in-situ occurrences of the same wh-phrase. My analysis is based on the concept of continuations. It uses a novel type system for higher-order continuations to handle wide-scope wh-phrases while remaining strictly compositional. This treatment sheds light on the combinatorics of interrogatives as well as other kinds of so-called A'-movement.
* 20 pages; typo fixed
Question answering: from partitions to Prolog
Sep 04, 2002
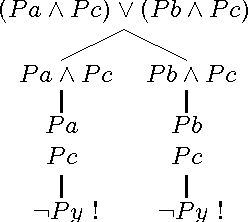
We implement Groenendijk and Stokhof's partition semantics of questions in a simple question answering algorithm. The algorithm is sound, complete, and based on tableau theorem proving. The algorithm relies on a syntactic characterization of answerhood: Any answer to a question is equivalent to some formula built up only from instances of the question. We prove this characterization by translating the logic of interrogation to classical predicate logic and applying Craig's interpolation theorem.
* 15 pages
The partition semantics of questions, syntactically
Sep 04, 2002Groenendijk and Stokhof (1984, 1996; Groenendijk 1999) provide a logically attractive theory of the semantics of natural language questions, commonly referred to as the partition theory. Two central notions in this theory are entailment between questions and answerhood. For example, the question "Who is going to the party?" entails the question "Is John going to the party?", and "John is going to the party" counts as an answer to both. Groenendijk and Stokhof define these two notions in terms of partitions of a set of possible worlds. We provide a syntactic characterization of entailment between questions and answerhood . We show that answers are, in some sense, exactly those formulas that are built up from instances of the question. This result lets us compare the partition theory with other approaches to interrogation -- both linguistic analyses, such as Hamblin's and Karttunen's semantics, and computational systems, such as Prolog. Our comparison separates a notion of answerhood into three aspects: equivalence (when two questions or answers are interchangeable), atomic answers (what instances of a question count as answers), and compound answers (how answers compose).
* 14 pages
A variable-free dynamic semantics
May 17, 2002I propose a variable-free treatment of dynamic semantics. By "dynamic semantics" I mean analyses of donkey sentences ("Every farmer who owns a donkey beats it") and other binding and anaphora phenomena in natural language where meanings of constituents are updates to information states, for instance as proposed by Groenendijk and Stokhof. By "variable-free" I mean denotational semantics in which functional combinators replace variable indices and assignment functions, for instance as advocated by Jacobson. The new theory presented here achieves a compositional treatment of dynamic anaphora that does not involve assignment functions, and separates the combinatorics of variable-free semantics from the particular linguistic phenomena it treats. Integrating variable-free semantics and dynamic semantics gives rise to interactions that make new empirical predictions, for example "donkey weak crossover" effects.
* 6 pages
Monads for natural language semantics
May 17, 2002Accounts of semantic phenomena often involve extending types of meanings and revising composition rules at the same time. The concept of monads allows many such accounts -- for intensionality, variable binding, quantification and focus -- to be stated uniformly and compositionally.
* 14 pages