 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilling Self-Supervised Vision Transformers for Weakly-Supervised Few-Shot Classification & Segmentation
Paper and Code
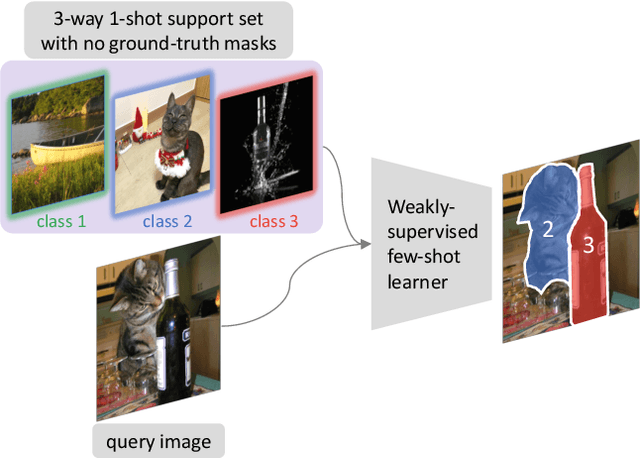

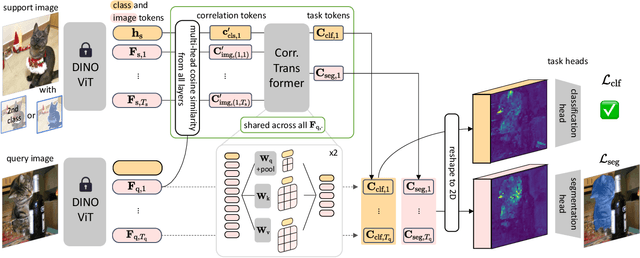

We address the task of weakly-supervised few-shot image classification and segmentation, by leveraging a Vision Transformer (ViT) pretrained with self-supervision. Our proposed method takes token representations from the self-supervised ViT and leverages their correlations, via self-attention, to produce classification and segmentation predictions through separate task heads. Our model is able to effectively learn to perform classification and segmentation in the absence of pixel-level labels during training, using only image-level labels. To do this it uses attention maps, created from tokens generated by the self-supervised ViT backbone, as pixel-level pseudo-labels. We also explore a practical setup with ``mixed" supervision, where a small number of training images contains ground-truth pixel-level labels and the remaining images have only image-level labels. For this mixed setup, we propose to improve the pseudo-labels using a pseudo-label enhancer that was trained using the available ground-truth pixel-level labels. Experiments on Pascal-5i and COCO-20i demonstrate significant performance gains in a variety of supervision settings, and in particular when little-to-no pixel-level labels are available.