 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrounding Image Matching in 3D with MASt3R
Jun 14, 2024



Image Matching is a core component of all best-performing algorithms and pipelines in 3D vision. Yet despite matching being fundamentally a 3D problem, intrinsically linked to camera pose and scene geometry, it is typically treated as a 2D problem. This makes sense as the goal of matching is to establish correspondences between 2D pixel fields, but also seems like a potentially hazardous choice. In this work, we take a different stance and propose to cast matching as a 3D task with DUSt3R, a recent and powerful 3D reconstruction framework based on Transformers. Based on pointmaps regression, this method displayed impressive robustness in matching views with extreme viewpoint changes, yet with limited accuracy. We aim here to improve the matching capabilities of such an approach while preserving its robustness. We thus propose to augment the DUSt3R network with a new head that outputs dense local features, trained with an additional matching loss. We further address the issue of quadratic complexity of dense matching, which becomes prohibitively slow for downstream applications if not carefully treated. We introduce a fast reciprocal matching scheme that not only accelerates matching by orders of magnitude, but also comes with theoretical guarantees and, lastly, yields improved results. Extensive experiments show that our approach, coined MASt3R, significantly outperforms the state of the art on multiple matching tasks. In particular, it beats the best published methods by 30% (absolute improvement) in VCRE AUC on the extremely challenging Map-free localization dataset.
Improved Cross-view Completion Pre-training for Stereo Matching
Nov 18, 2022



Despite impressive performance for high-level downstream tasks, self-supervised pre-training methods have not yet fully delivered on dense geometric vision tasks such as stereo matching. The application of self-supervised learning concepts, such as instance discrimination or masked image modeling, to geometric tasks is an active area of research. In this work we build on the recent cross-view completion framework: this variation of masked image modeling leverages a second view from the same scene, which is well suited for binocular downstream tasks. However, the applicability of this concept has so far been limited in at least two ways: (a) by the difficulty of collecting real-world image pairs - in practice only synthetic data had been used - and (b) by the lack of generalization of vanilla transformers to dense downstream tasks for which relative position is more meaningful than absolute position. We explore three avenues of improvement: first, we introduce a method to collect suitable real-world image pairs at large scale. Second, we experiment with relative positional embeddings and demonstrate that they enable vision transformers to perform substantially better. Third, we scale up vision transformer based cross-completion architectures, which is made possible by the use of large amounts of data. With these improvements, we show for the first time that state-of-the-art results on deep stereo matching can be reached without using any standard task-specific techniques like correlation volume, iterative estimation or multi-scale reasoning.
CroCo: Self-Supervised Pre-training for 3D Vision Tasks by Cross-View Completion
Oct 19, 2022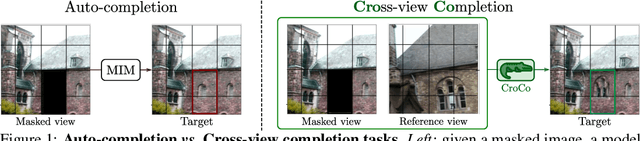



Masked Image Modeling (MIM) has recently been established as a potent pre-training paradigm. A pretext task is constructed by masking patches in an input image, and this masked content is then predicted by a neural network using visible patches as sole input. This pre-training leads to state-of-the-art performance when finetuned for high-level semantic tasks, e.g. image classification and object detection. In this paper we instead seek to learn representations that transfer well to a wide variety of 3D vision and lower-level geometric downstream tasks, such as depth prediction or optical flow estimation. Inspired by MIM, we propose an unsupervised representation learning task trained from pairs of images showing the same scene from different viewpoints. More precisely, we propose the pretext task of cross-view completion where the first input image is partially masked, and this masked content has to be reconstructed from the visible content and the second image. In single-view MIM, the masked content often cannot be inferred precisely from the visible portion only, so the model learns to act as a prior influenced by high-level semantics. In contrast, this ambiguity can be resolved with cross-view completion from the second unmasked image, on the condition that the model is able to understand the spatial relationship between the two images. Our experiments show that our pretext task leads to significantly improved performance for monocular 3D vision downstream tasks such as depth estimation. In addition, our model can be directly applied to binocular downstream tasks like optical flow or relative camera pose estimation, for which we obtain competitive results without bells and whistles, i.e., using a generic architecture without any task-specific design.
Robust Image Retrieval-based Visual Localization using Kapture
Aug 31, 2020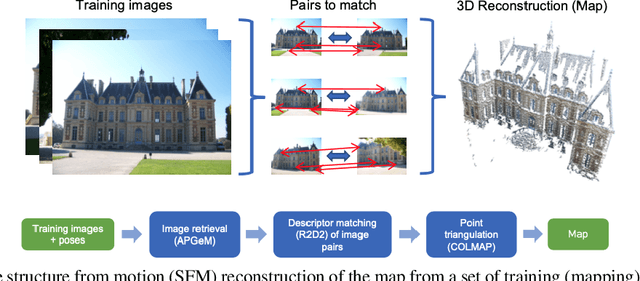
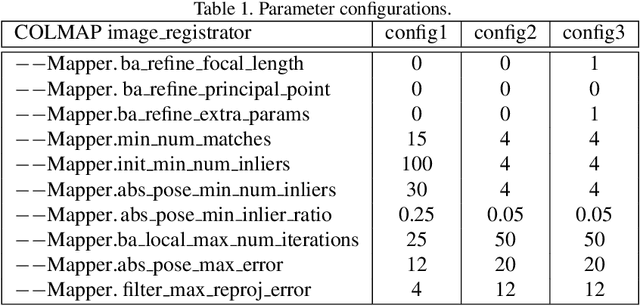
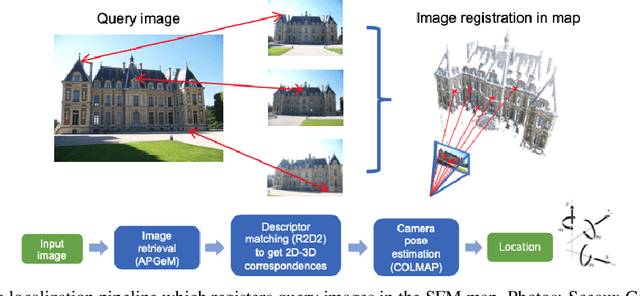

In this paper, we present a versatile method for visual localization. It is based on robust image retrieval for coarse camera pose estimation and robust local features for accurate pose refinement. Our method is top ranked on various public datasets showing its ability of generalization and its great variety of applications. To facilitate experiments, we introduce kapture, a flexible data format and processing pipeline for structure from motion and visual localization that is released open source. We furthermore provide all datasets used in this paper in the kapture format to facilitate research and data processing. Code and datasets can be found at https://github.com/naver/kapture, more information, updates, and news can be found at https://europe.naverlabs.com/research/3d-vision/kapture.
Circulant temporal encoding for video retrieval and temporal alignment
Nov 30, 2015
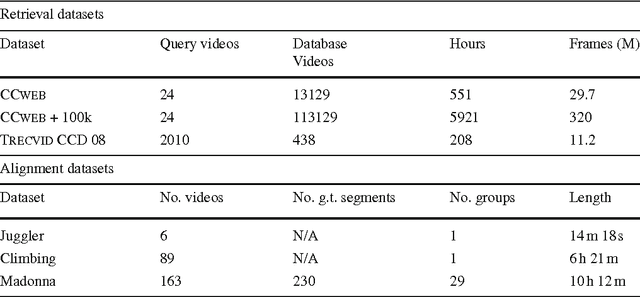
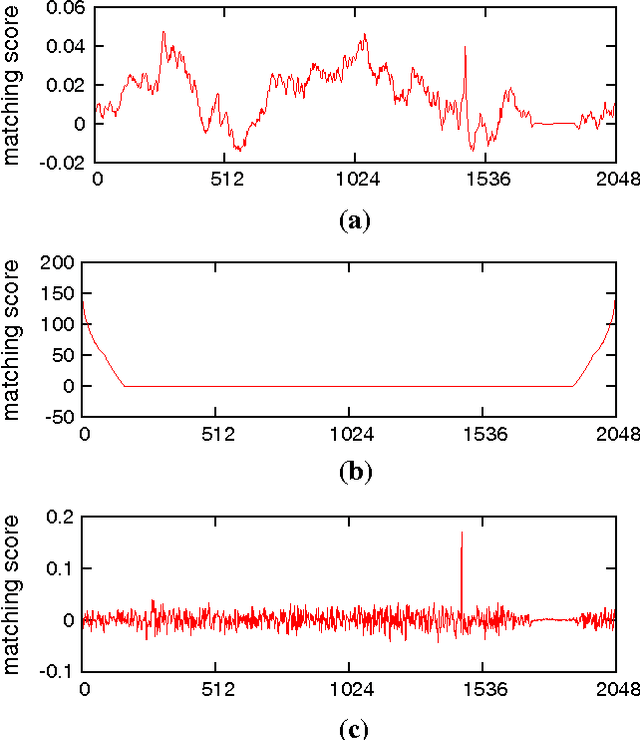
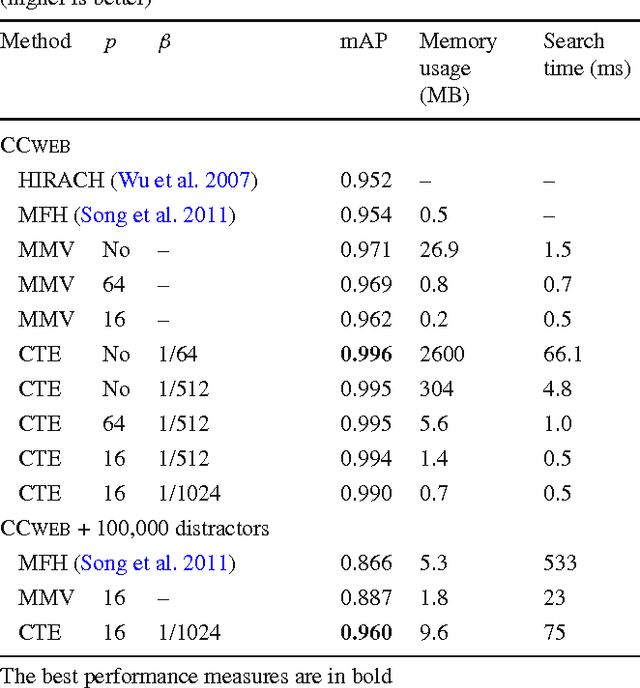
We address the problem of specific video event retrieval. Given a query video of a specific event, e.g., a concert of Madonna, the goal is to retrieve other videos of the same event that temporally overlap with the query. Our approach encodes the frame descriptors of a video to jointly represent their appearance and temporal order. It exploits the properties of circulant matrices to efficiently compare the videos in the frequency domain. This offers a significant gain in complexity and accurately localizes the matching parts of videos. The descriptors can be compressed in the frequency domain with a product quantizer adapted to complex numbers. In this case, video retrieval is performed without decompressing the descriptors. We also consider the temporal alignment of a set of videos. We exploit the matching confidence and an estimate of the temporal offset computed for all pairs of videos by our retrieval approach. Our robust algorithm aligns the videos on a global timeline by maximizing the set of temporally consistent matches. The global temporal alignment enables synchronous playback of the videos of a given scene.