 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeterministic Guidance Diffusion Model for Probabilistic Weather Forecasting
Dec 05, 2023



Weather forecasting requires not only accuracy but also the ability to perform probabilistic prediction. However, deterministic weather forecasting methods do not support probabilistic predictions, and conversely, probabilistic models tend to be less accurate. To address these challenges, in this paper, we introduce the \textbf{\textit{D}}eterministic \textbf{\textit{G}}uidance \textbf{\textit{D}}iffusion \textbf{\textit{M}}odel (DGDM) for probabilistic weather forecasting, integrating benefits of both deterministic and probabilistic approaches. During the forward process, both the deterministic and probabilistic models are trained end-to-end. In the reverse process, weather forecasting leverages the predicted result from the deterministic model, using as an intermediate starting point for the probabilistic model. By fusing deterministic models with probabilistic models in this manner, DGDM is capable of providing accurate forecasts while also offering probabilistic predictions. To evaluate DGDM, we assess it on the global weather forecasting dataset (WeatherBench) and the common video frame prediction benchmark (Moving MNIST). We also introduce and evaluate the Pacific Northwest Windstorm (PNW)-Typhoon weather satellite dataset to verify the effectiveness of DGDM in high-resolution regional forecasting. As a result of our experiments, DGDM achieves state-of-the-art results not only in global forecasting but also in regional forecasting. The code is available at: \url{https://github.com/DongGeun-Yoon/DGDM}.
Lightweight Alpha Matting Network Using Distillation-Based Channel Pruning
Oct 14, 2022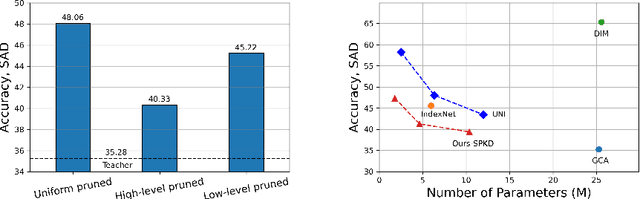

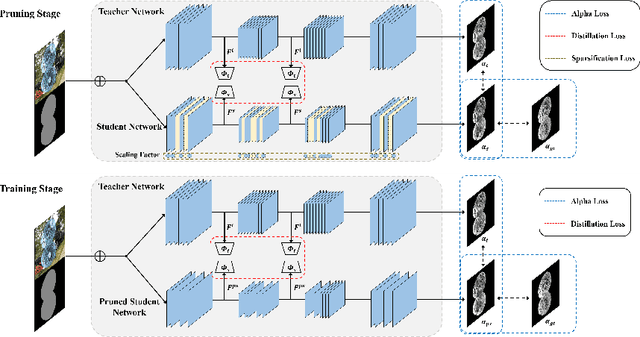
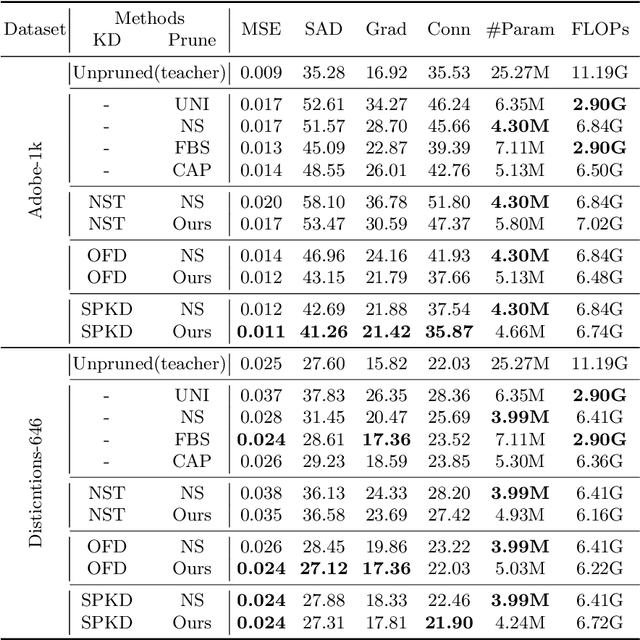
Recently, alpha matting has received a lot of attention because of its usefulness in mobile applications such as selfies. Therefore, there has been a demand for a lightweight alpha matting model due to the limited computational resources of commercial portable devices. To this end, we suggest a distillation-based channel pruning method for the alpha matting networks. In the pruning step, we remove channels of a student network having fewer impacts on mimicking the knowledge of a teacher network. Then, the pruned lightweight student network is trained by the same distillation loss. A lightweight alpha matting model from the proposed method outperforms existing lightweight methods. To show superiority of our algorithm, we provide various quantitative and qualitative experiments with in-depth analyses. Furthermore, we demonstrate the versatility of the proposed distillation-based channel pruning method by applying it to semantic segmentation.