 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDouble Targeted Universal Adversarial Perturbations
Paper and Code
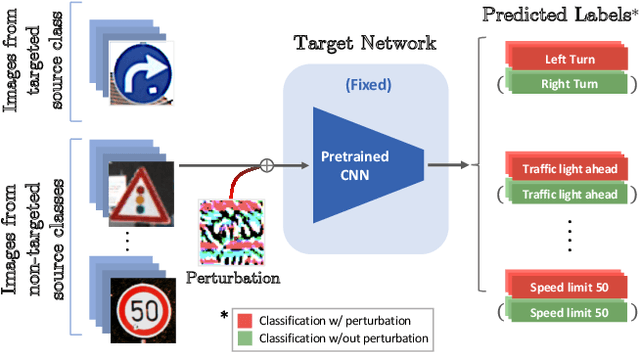



Despite their impressive performance, deep neural networks (DNNs) are widely known to be vulnerable to adversarial attacks, which makes it challenging for them to be deployed in security-sensitive applications, such as autonomous driving. Image-dependent perturbations can fool a network for one specific image, while universal adversarial perturbations are capable of fooling a network for samples from all classes without selection. We introduce a double targeted universal adversarial perturbations (DT-UAPs) to bridge the gap between the instance-discriminative image-dependent perturbations and the generic universal perturbations. This universal perturbation attacks one targeted source class to sink class, while having a limited adversarial effect on other non-targeted source classes, for avoiding raising suspicions. Targeting the source and sink class simultaneously, we term it double targeted attack (DTA). This provides an attacker with the freedom to perform precise attacks on a DNN model while raising little suspicion. We show the effectiveness of the proposed DTA algorithm on a wide range of datasets and also demonstrate its potential as a physical attack.