 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDYAN: A Dynamical Atoms-Based Network for Video Prediction
Paper and Code
Sep 14, 2018

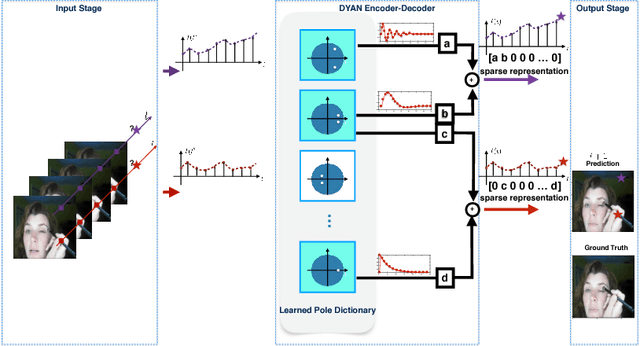

The ability to anticipate the future is essential when making real time critical decisions, provides valuable information to understand dynamic natural scenes, and can help unsupervised video representation learning. State-of-art video prediction is based on LSTM recursive networks and/or generative adversarial network learning. These are complex architectures that need to learn large numbers of parameters, are potentially hard to train, slow to run, and may produce blurry predictions. In this paper, we introduce DYAN, a novel network with very few parameters and easy to train, which produces accurate, high quality frame predictions, significantly faster than previous approaches. DYAN owes its good qualities to its encoder and decoder, which are designed following concepts from systems identification theory and exploit the dynamics-based invariants of the data. Extensive experiments using several standard video datasets show that DYAN is superior generating frames and that it generalizes well across domains.