 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA short methodological review on social robot navigation benchmarking
Oct 25, 2025Social Robot Navigation is the skill that allows robots to move efficiently in human-populated environments while ensuring safety, comfort, and trust. Unlike other areas of research, the scientific community has not yet achieved an agreement on how Social Robot Navigation should be benchmarked. This is notably important, as the lack of a de facto standard to benchmark Social Robot Navigation can hinder the progress of the field and may lead to contradicting conclusions. Motivated by this gap, we contribute with a short review focused exclusively on benchmarking trends in the period from January 2020 to July 2025. Of the 130 papers identified by our search using IEEE Xplore, we analysed the 85 papers that met the criteria of the review. This review addresses the metrics used in the literature for benchmarking purposes, the algorithms employed in such benchmarks, the use of human surveys for benchmarking, and how conclusions are drawn from the benchmarking results, when applicable.
Goal-based Self-Adaptive Generative Adversarial Imitation Learning (Goal-SAGAIL) for Multi-goal Robotic Manipulation Tasks
Jun 15, 2025Reinforcement learning for multi-goal robot manipulation tasks poses significant challenges due to the diversity and complexity of the goal space. Techniques such as Hindsight Experience Replay (HER) have been introduced to improve learning efficiency for such tasks. More recently, researchers have combined HER with advanced imitation learning methods such as Generative Adversarial Imitation Learning (GAIL) to integrate demonstration data and accelerate training speed. However, demonstration data often fails to provide enough coverage for the goal space, especially when acquired from human teleoperation. This biases the learning-from-demonstration process toward mastering easier sub-tasks instead of tackling the more challenging ones. In this work, we present Goal-based Self-Adaptive Generative Adversarial Imitation Learning (Goal-SAGAIL), a novel framework specifically designed for multi-goal robot manipulation tasks. By integrating self-adaptive learning principles with goal-conditioned GAIL, our approach enhances imitation learning efficiency, even when limited, suboptimal demonstrations are available. Experimental results validate that our method significantly improves learning efficiency across various multi-goal manipulation scenarios -- including complex in-hand manipulation tasks -- using suboptimal demonstrations provided by both simulation and human experts.
Multi-Head Adaptive Graph Convolution Network for Sparse Point Cloud-Based Human Activity Recognition
Apr 03, 2025
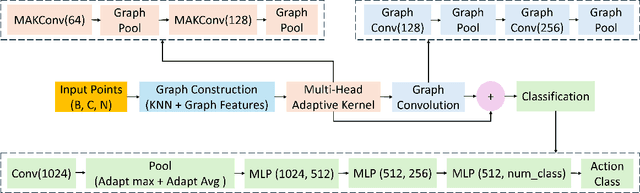


Human activity recognition is increasingly vital for supporting independent living, particularly for the elderly and those in need of assistance. Domestic service robots with monitoring capabilities can enhance safety and provide essential support. Although image-based methods have advanced considerably in the past decade, their adoption remains limited by concerns over privacy and sensitivity to low-light or dark conditions. As an alternative, millimetre-wave (mmWave) radar can produce point cloud data which is privacy-preserving. However, processing the sparse and noisy point clouds remains a long-standing challenge. While graph-based methods and attention mechanisms show promise, they predominantly rely on "fixed" kernels; kernels that are applied uniformly across all neighbourhoods, highlighting the need for adaptive approaches that can dynamically adjust their kernels to the specific geometry of each local neighbourhood in point cloud data. To overcome this limitation, we introduce an adaptive approach within the graph convolutional framework. Instead of a single shared weight function, our Multi-Head Adaptive Kernel (MAK) module generates multiple dynamic kernels, each capturing different aspects of the local feature space. By progressively refining local features while maintaining global spatial context, our method enables convolution kernels to adapt to varying local features. Experimental results on benchmark datasets confirm the effectiveness of our approach, achieving state-of-the-art performance in human activity recognition. Our source code is made publicly available at: https://github.com/Gbouna/MAK-GCN
Action Recognition in Real-World Ambient Assisted Living Environment
Mar 29, 2025


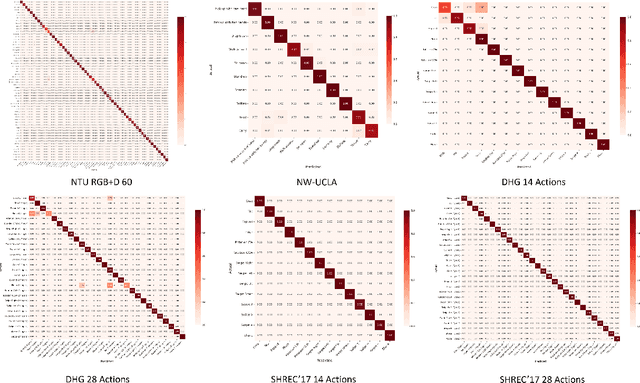
The growing ageing population and their preference to maintain independence by living in their own homes require proactive strategies to ensure safety and support. Ambient Assisted Living (AAL) technologies have emerged to facilitate ageing in place by offering continuous monitoring and assistance within the home. Within AAL technologies, action recognition plays a crucial role in interpreting human activities and detecting incidents like falls, mobility decline, or unusual behaviours that may signal worsening health conditions. However, action recognition in practical AAL applications presents challenges, including occlusions, noisy data, and the need for real-time performance. While advancements have been made in accuracy, robustness to noise, and computation efficiency, achieving a balance among them all remains a challenge. To address this challenge, this paper introduces the Robust and Efficient Temporal Convolution network (RE-TCN), which comprises three main elements: Adaptive Temporal Weighting (ATW), Depthwise Separable Convolutions (DSC), and data augmentation techniques. These elements aim to enhance the model's accuracy, robustness against noise and occlusion, and computational efficiency within real-world AAL contexts. RE-TCN outperforms existing models in terms of accuracy, noise and occlusion robustness, and has been validated on four benchmark datasets: NTU RGB+D 60, Northwestern-UCLA, SHREC'17, and DHG-14/28. The code is publicly available at: https://github.com/Gbouna/RE-TCN
BaseBoostDepth: Exploiting Larger Baselines For Self-supervised Monocular Depth Estimation
Jul 29, 2024
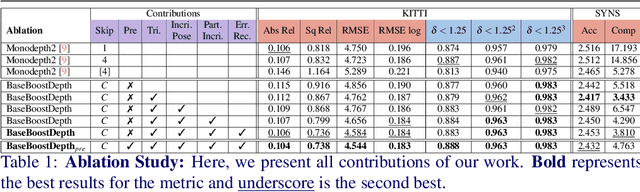
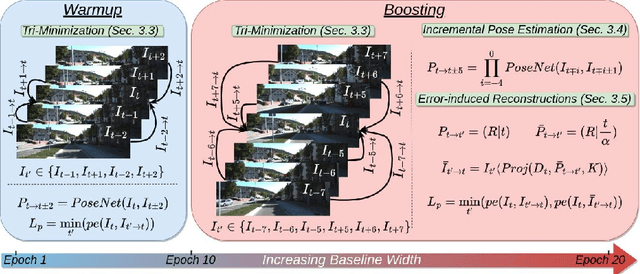
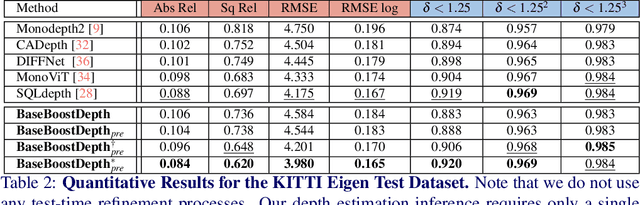
In the domain of multi-baseline stereo, the conventional understanding is that, in general, increasing baseline separation substantially enhances the accuracy of depth estimation. However, prevailing self-supervised depth estimation architectures primarily use minimal frame separation and a constrained stereo baseline. Larger frame separations can be employed; however, we show this to result in diminished depth quality due to various factors, including significant changes in brightness, and increased areas of occlusion. In response to these challenges, our proposed method, BaseBoostDepth, incorporates a curriculum learning-inspired optimization strategy to effectively leverage larger frame separations. However, we show that our curriculum learning-inspired strategy alone does not suffice, as larger baselines still cause pose estimation drifts. Therefore, we introduce incremental pose estimation to enhance the accuracy of pose estimations, resulting in significant improvements across all depth metrics. Additionally, to improve the robustness of the model, we introduce error-induced reconstructions, which optimize reconstructions with added error to the pose estimations. Ultimately, our final depth network achieves state-of-the-art performance on KITTI and SYNS-patches datasets across image-based, edge-based, and point cloud-based metrics without increasing computational complexity at test time. The project website can be found at https://kieran514.github.io/BaseBoostDepth-Project.
Synthesizing Traffic Datasets using Graph Neural Networks
Dec 08, 2023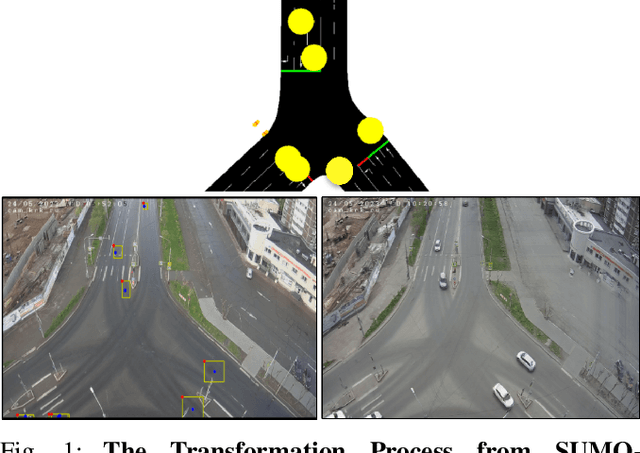
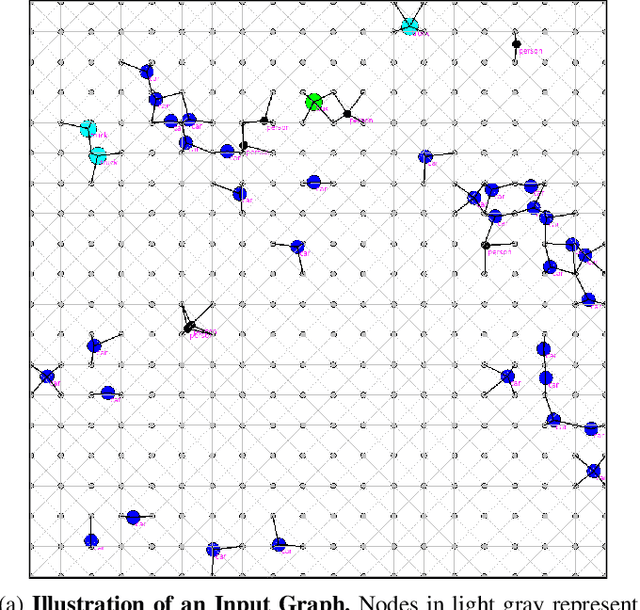
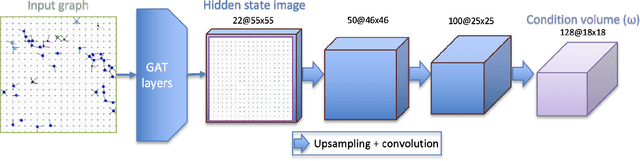
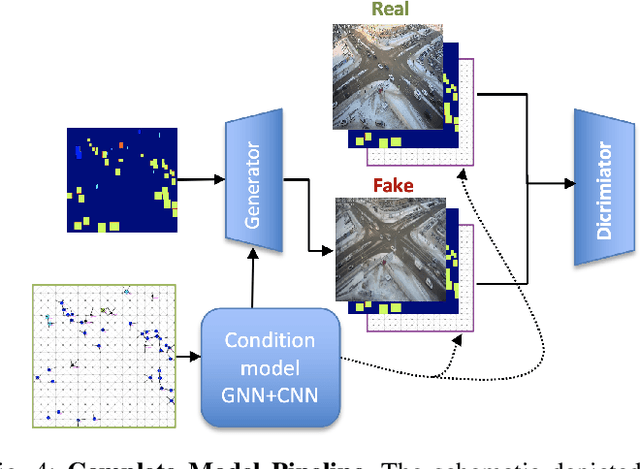
Traffic congestion in urban areas presents significant challenges, and Intelligent Transportation Systems (ITS) have sought to address these via automated and adaptive controls. However, these systems often struggle to transfer simulated experiences to real-world scenarios. This paper introduces a novel methodology for bridging this `sim-real' gap by creating photorealistic images from 2D traffic simulations and recorded junction footage. We propose a novel image generation approach, integrating a Conditional Generative Adversarial Network with a Graph Neural Network (GNN) to facilitate the creation of realistic urban traffic images. We harness GNNs' ability to process information at different levels of abstraction alongside segmented images for preserving locality data. The presented architecture leverages the power of SPADE and Graph ATtention (GAT) network models to create images based on simulated traffic scenarios. These images are conditioned by factors such as entity positions, colors, and time of day. The uniqueness of our approach lies in its ability to effectively translate structured and human-readable conditions, encoded as graphs, into realistic images. This advancement contributes to applications requiring rich traffic image datasets, from data augmentation to urban traffic solutions. We further provide an application to test the model's capabilities, including generating images with manually defined positions for various entities.
A Survey on Socially Aware Robot Navigation: Taxonomy and Future Challenges
Nov 18, 2023Socially aware robot navigation is gaining popularity with the increase in delivery and assistive robots. The research is further fueled by a need for socially aware navigation skills in autonomous vehicles to move safely and appropriately in spaces shared with humans. Although most of these are ground robots, drones are also entering the field. In this paper, we present a literature survey of the works on socially aware robot navigation in the past 10 years. We propose four different faceted taxonomies to navigate the literature and examine the field from four different perspectives. Through the taxonomic review, we discuss the current research directions and the extending scope of applications in various domains. Further, we put forward a list of current research opportunities and present a discussion on possible future challenges that are likely to emerge in the field.
Principles and Guidelines for Evaluating Social Robot Navigation Algorithms
Jun 29, 2023



A major challenge to deploying robots widely is navigation in human-populated environments, commonly referred to as social robot navigation. While the field of social navigation has advanced tremendously in recent years, the fair evaluation of algorithms that tackle social navigation remains hard because it involves not just robotic agents moving in static environments but also dynamic human agents and their perceptions of the appropriateness of robot behavior. In contrast, clear, repeatable, and accessible benchmarks have accelerated progress in fields like computer vision, natural language processing and traditional robot navigation by enabling researchers to fairly compare algorithms, revealing limitations of existing solutions and illuminating promising new directions. We believe the same approach can benefit social navigation. In this paper, we pave the road towards common, widely accessible, and repeatable benchmarking criteria to evaluate social robot navigation. Our contributions include (a) a definition of a socially navigating robot as one that respects the principles of safety, comfort, legibility, politeness, social competency, agent understanding, proactivity, and responsiveness to context, (b) guidelines for the use of metrics, development of scenarios, benchmarks, datasets, and simulators to evaluate social navigation, and (c) a design of a social navigation metrics framework to make it easier to compare results from different simulators, robots and datasets.
Multi-person 3D pose estimation from unlabelled data
Dec 16, 2022Its numerous applications make multi-human 3D pose estimation a remarkably impactful area of research. Nevertheless, assuming a multiple-view system composed of several regular RGB cameras, 3D multi-pose estimation presents several challenges. First of all, each person must be uniquely identified in the different views to separate the 2D information provided by the cameras. Secondly, the 3D pose estimation process from the multi-view 2D information of each person must be robust against noise and potential occlusions in the scenario. In this work, we address these two challenges with the help of deep learning. Specifically, we present a model based on Graph Neural Networks capable of predicting the cross-view correspondence of the people in the scenario along with a Multilayer Perceptron that takes the 2D points to yield the 3D poses of each person. These two models are trained in a self-supervised manner, thus avoiding the need for large datasets with 3D annotations.
Dyna-DM: Dynamic Object-aware Self-supervised Monocular Depth Maps
Jun 23, 2022

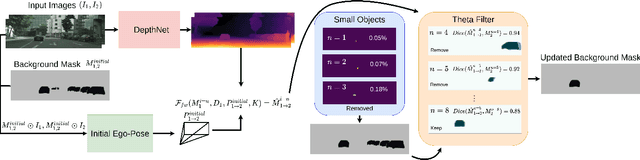
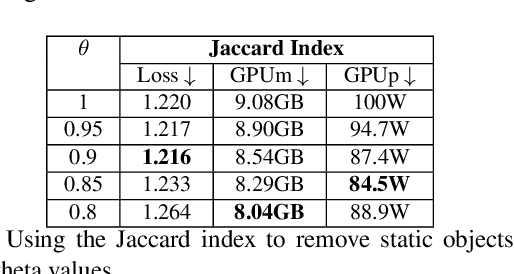
Self-supervised monocular depth estimation has been a subject of intense study in recent years, because of its applications in robotics and autonomous driving. Much of the recent work focuses on improving depth estimation by increasing architecture complexity. This paper shows that state-of-the-art performance can also be achieved by improving the learning process rather than increasing model complexity. More specifically, we propose (i) only using invariant pose loss for the first few epochs during training, (ii) disregarding small potentially dynamic objects when training, and (iii) employing an appearance-based approach to separately estimate object pose for truly dynamic objects. We demonstrate that these simplifications reduce GPU memory usage by 29% and result in qualitatively and quantitatively improved depth maps. The code is available at https://github.com/kieran514/Dyna-DM.