 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFruit Quality and Defect Image Classification with Conditional GAN Data Augmentation
Apr 12, 2021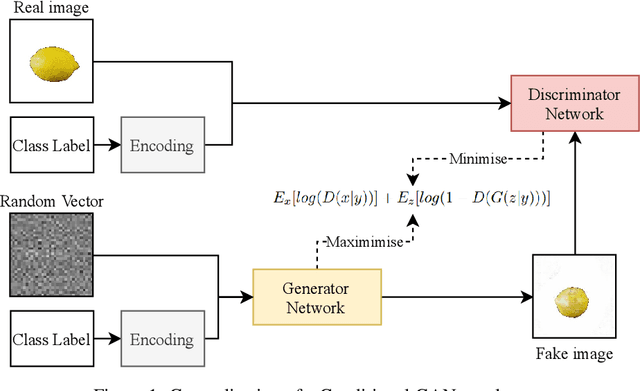
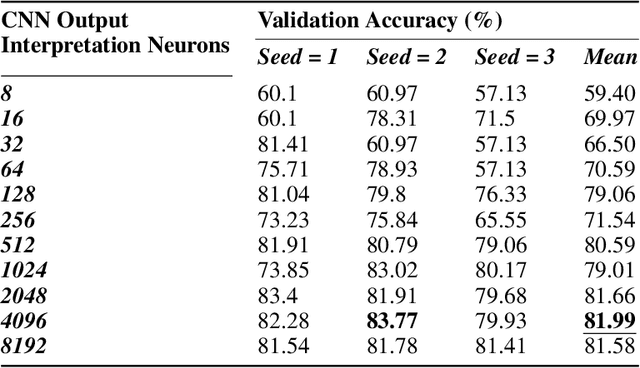
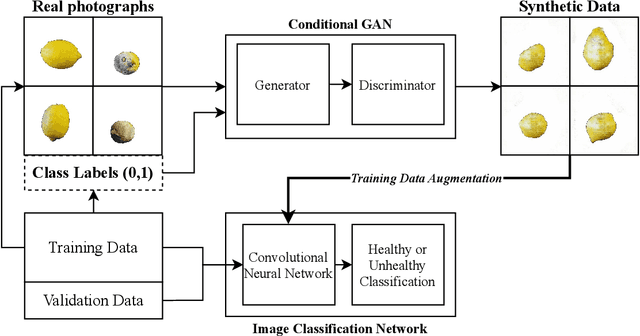
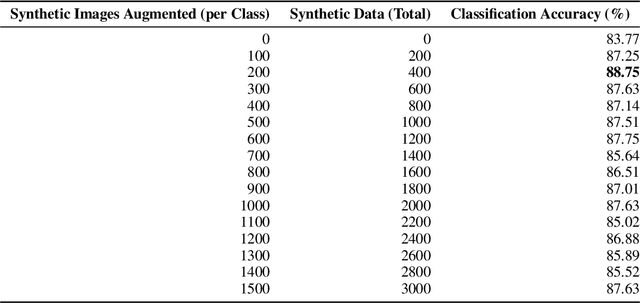
Contemporary Artificial Intelligence technologies allow for the employment of Computer Vision to discern good crops from bad, providing a step in the pipeline of selecting healthy fruit from undesirable fruit, such as those which are mouldy or gangrenous. State-of-the-art works in the field report high accuracy results on small datasets (<1000 images), which are not representative of the population regarding real-world usage. The goals of this study are to further enable real-world usage by improving generalisation with data augmentation as well as to reduce overfitting and energy usage through model pruning. In this work, we suggest a machine learning pipeline that combines the ideas of fine-tuning, transfer learning, and generative model-based training data augmentation towards improving fruit quality image classification. A linear network topology search is performed to tune a VGG16 lemon quality classification model using a publicly-available dataset of 2690 images. We find that appending a 4096 neuron fully connected layer to the convolutional layers leads to an image classification accuracy of 83.77%. We then train a Conditional Generative Adversarial Network on the training data for 2000 epochs, and it learns to generate relatively realistic images. Grad-CAM analysis of the model trained on real photographs shows that the synthetic images can exhibit classifiable characteristics such as shape, mould, and gangrene. A higher image classification accuracy of 88.75% is then attained by augmenting the training with synthetic images, arguing that Conditional Generative Adversarial Networks have the ability to produce new data to alleviate issues of data scarcity. Finally, model pruning is performed via polynomial decay, where we find that the Conditional GAN-augmented classification network can retain 81.16% classification accuracy when compressed to 50% of its original size.
Chatbot Interaction with Artificial Intelligence: Human Data Augmentation with T5 and Language Transformer Ensemble for Text Classification
Oct 22, 2020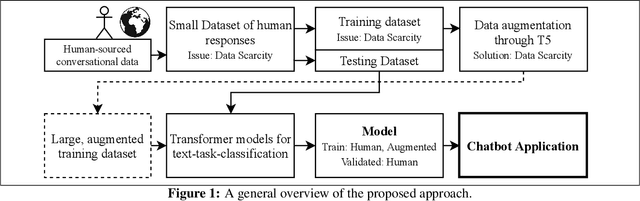

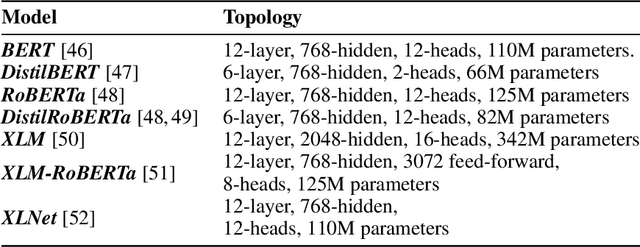
In this work, we present the Chatbot Interaction with Artificial Intelligence (CI-AI) framework as an approach to the training of deep learning chatbots for task classification. The intelligent system augments human-sourced data via artificial paraphrasing in order to generate a large set of training data for further classical, attention, and language transformation-based learning approaches for Natural Language Processing. Human beings are asked to paraphrase commands and questions for task identification for further execution of a machine. The commands and questions are split into training and validation sets. A total of 483 responses were recorded. Secondly, the training set is paraphrased by the T5 model in order to augment it with further data. Seven state-of-the-art transformer-based text classification algorithms (BERT, DistilBERT, RoBERTa, DistilRoBERTa, XLM, XLM-RoBERTa, and XLNet) are benchmarked for both sets after fine-tuning on the training data for two epochs. We find that all models are improved when training data is augmented by the T5 model, with an average increase of classification accuracy by 4.01%. The best result was the RoBERTa model trained on T5 augmented data which achieved 98.96% classification accuracy. Finally, we found that an ensemble of the five best-performing transformer models via Logistic Regression of output label predictions led to an accuracy of 99.59% on the dataset of human responses. A highly-performing model allows the intelligent system to interpret human commands at the social-interaction level through a chatbot-like interface (e.g. "Robot, can we have a conversation?") and allows for better accessibility to AI by non-technical users.
LSTM and GPT-2 Synthetic Speech Transfer Learning for Speaker Recognition to Overcome Data Scarcity
Jul 03, 2020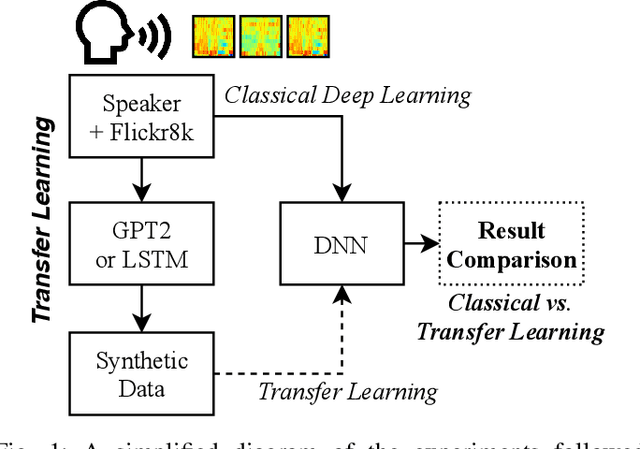
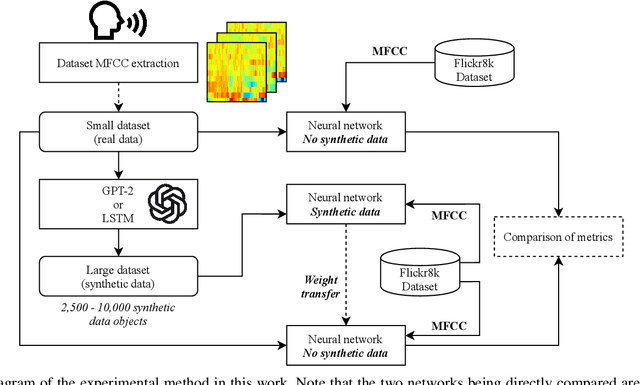
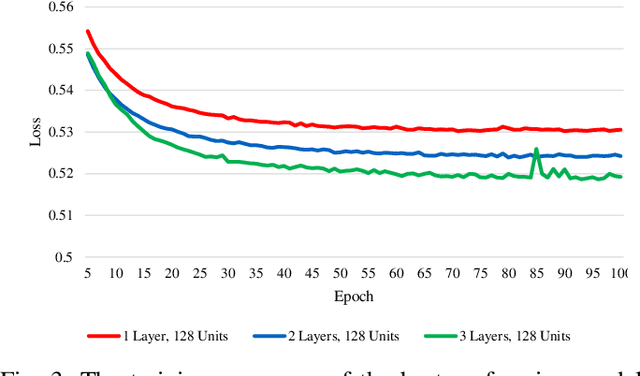
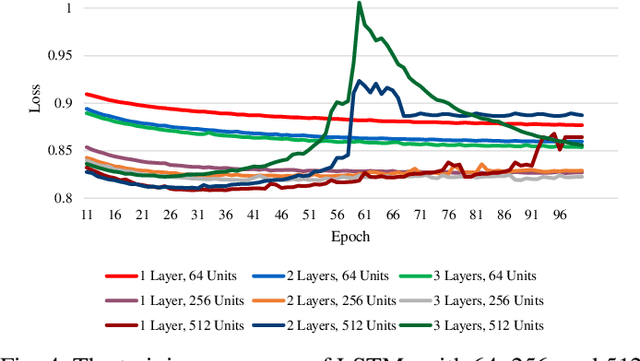
In speech recognition problems, data scarcity often poses an issue due to the willingness of humans to provide large amounts of data for learning and classification. In this work, we take a set of 5 spoken Harvard sentences from 7 subjects and consider their MFCC attributes. Using character level LSTMs (supervised learning) and OpenAI's attention-based GPT-2 models, synthetic MFCCs are generated by learning from the data provided on a per-subject basis. A neural network is trained to classify the data against a large dataset of Flickr8k speakers and is then compared to a transfer learning network performing the same task but with an initial weight distribution dictated by learning from the synthetic data generated by the two models. The best result for all of the 7 subjects were networks that had been exposed to synthetic data, the model pre-trained with LSTM-produced data achieved the best result 3 times and the GPT-2 equivalent 5 times (since one subject had their best result from both models at a draw). Through these results, we argue that speaker classification can be improved by utilising a small amount of user data but with exposure to synthetically-generated MFCCs which then allow the networks to achieve near maximum classification scores.
On the Effects of Pseudo and Quantum Random Number Generators in Soft Computing
Oct 10, 2019
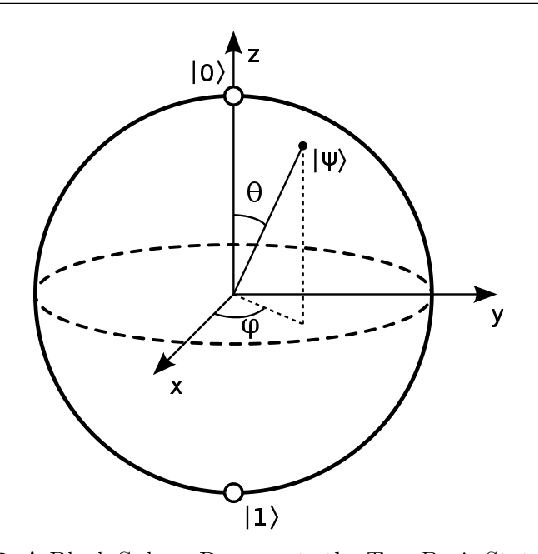
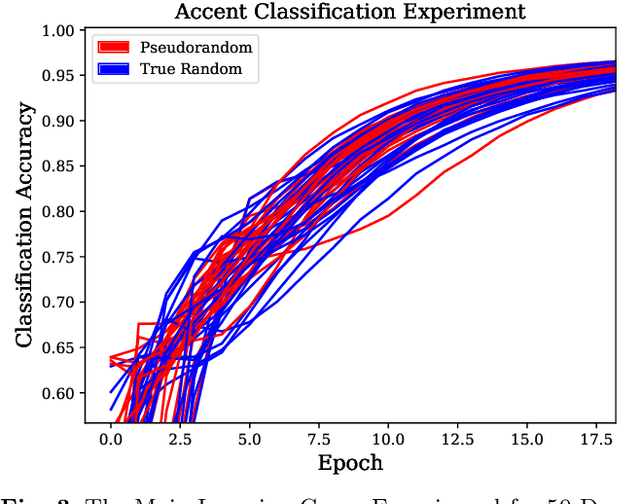
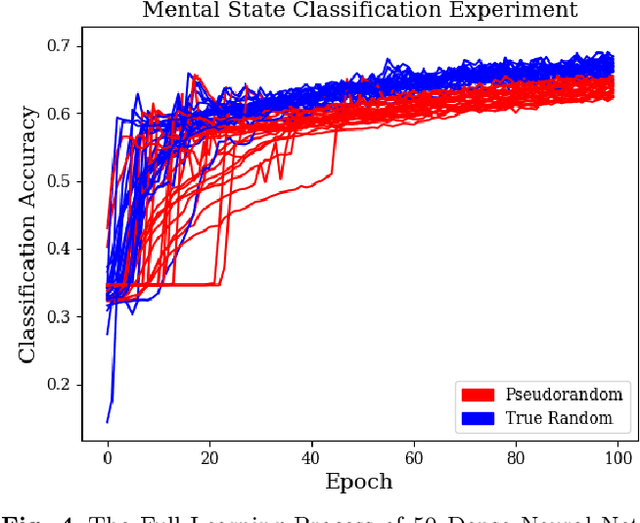
In this work, we argue that the implications of Pseudo and Quantum Random Number Generators (PRNG and QRNG) inexplicably affect the performances and behaviours of various machine learning models that require a random input. These implications are yet to be explored in Soft Computing until this work. We use a CPU and a QPU to generate random numbers for multiple Machine Learning techniques. Random numbers are employed in the random initial weight distributions of Dense and Convolutional Neural Networks, in which results show a profound difference in learning patterns for the two. In 50 Dense Neural Networks (25 PRNG/25 QRNG), QRNG increases over PRNG for accent classification at +0.1%, and QRNG exceeded PRNG for mental state EEG classification by +2.82%. In 50 Convolutional Neural Networks (25 PRNG/25 QRNG), the MNIST and CIFAR-10 problems are benchmarked, in MNIST the QRNG experiences a higher starting accuracy than the PRNG but ultimately only exceeds it by 0.02%. In CIFAR-10, the QRNG outperforms PRNG by +0.92%. The n-random split of a Random Tree is enhanced towards and new Quantum Random Tree (QRT) model, which has differing classification abilities to its classical counterpart, 200 trees are trained and compared (100 PRNG/100 QRNG). Using the accent and EEG classification datasets, a QRT seemed inferior to a RT as it performed on average worse by -0.12%. This pattern is also seen in the EEG classification problem, where a QRT performs worse than a RT by -0.28%. Finally, the QRT is ensembled into a Quantum Random Forest (QRF), which also has a noticeable effect when compared to the standard Random Forest (RF)... ABSTRACT SHORTENED DUE TO ARXIV LIMIT
A Deep Evolutionary Approach to Bioinspired Classifier Optimisation for Brain-Machine Interaction
Aug 13, 2019
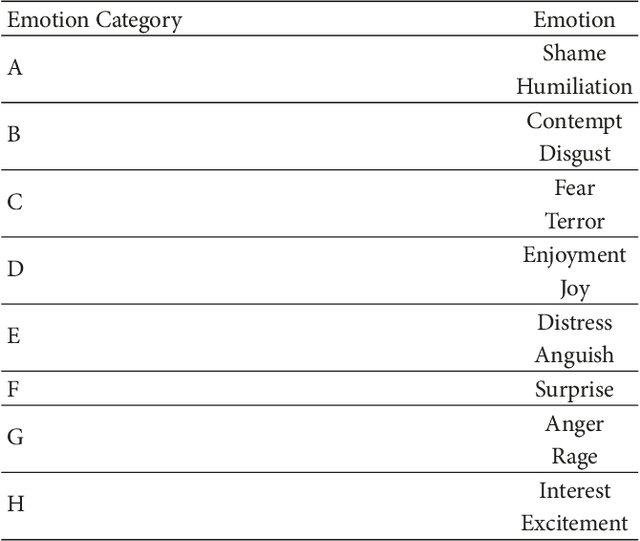
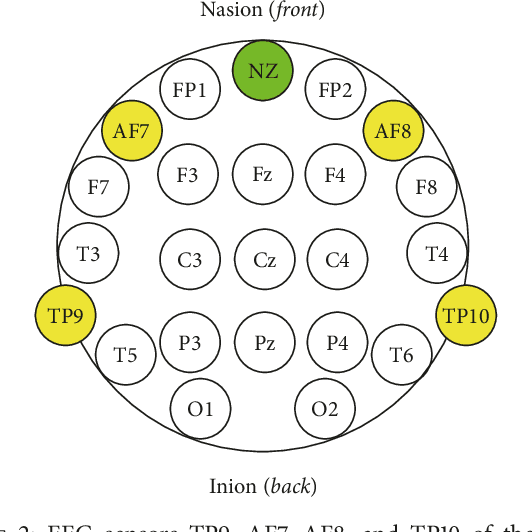

This study suggests a new approach to EEG data classification by exploring the idea of using evolutionary computation to both select useful discriminative EEG features and optimise the topology of Artificial Neural Networks. An evolutionary algorithm is applied to select the most informative features from an initial set of 2550 EEG statistical features. Optimisation of a Multilayer Perceptron (MLP) is performed with an evolutionary approach before classification to estimate the best hyperparameters of the network. Deep learning and tuning with Long Short-Term Memory (LSTM) are also explored, and Adaptive Boosting of the two types of models is tested for each problem. Three experiments are provided for comparison using different classifiers: one for attention state classification, one for emotional sentiment classification, and a third experiment in which the goal is to guess the number a subject is thinking of. The obtained results show that an Adaptive Boosted LSTM can achieve an accuracy of 84.44%, 97.06%, and 9.94% on the attentional, emotional, and number datasets, respectively. An evolutionary-optimised MLP achieves results close to the Adaptive Boosted LSTM for the two first experiments and significantly higher for the number-guessing experiment with an Adaptive Boosted DEvo MLP reaching 31.35%, while being significantly quicker to train and classify. In particular, the accuracy of the nonboosted DEvo MLP was of 79.81%, 96.11%, and 27.07% in the same benchmarks. Two datasets for the experiments were gathered using a Muse EEG headband with four electrodes corresponding to TP9, AF7, AF8, and TP10 locations of the international EEG placement standard. The EEG MindBigData digits dataset was gathered from the TP9, FP1, FP2, and TP10 locations.