 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLSTM and GPT-2 Synthetic Speech Transfer Learning for Speaker Recognition to Overcome Data Scarcity
Paper and Code
Jul 03, 2020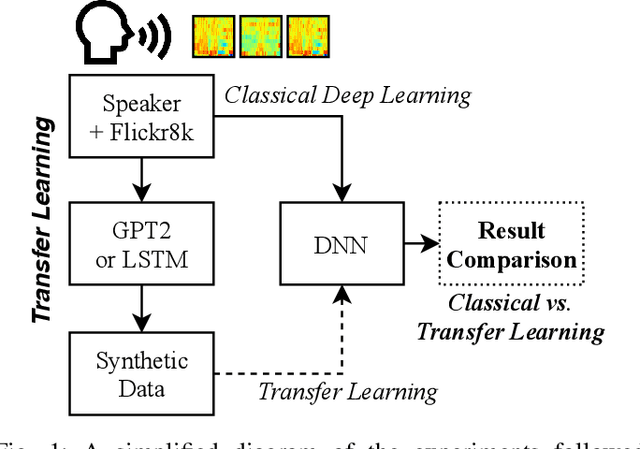
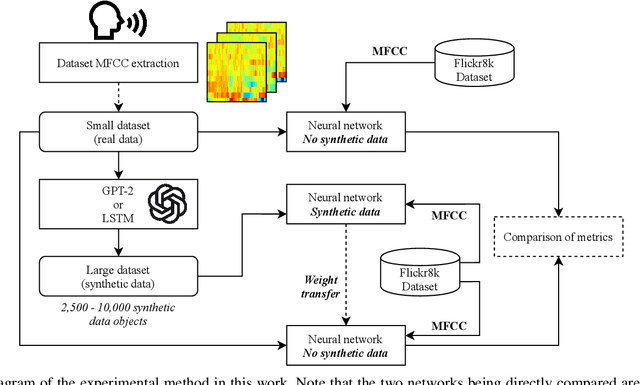
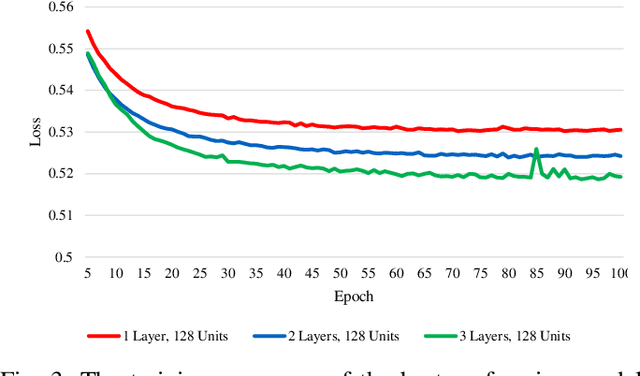
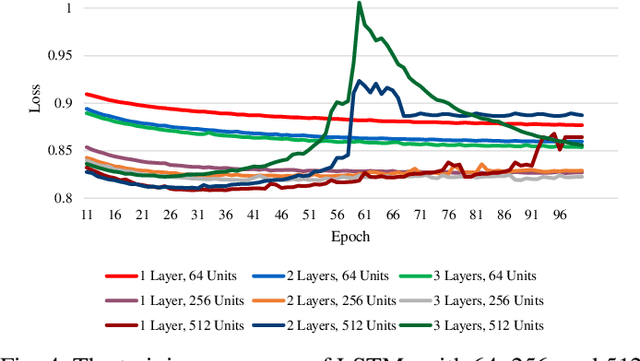
In speech recognition problems, data scarcity often poses an issue due to the willingness of humans to provide large amounts of data for learning and classification. In this work, we take a set of 5 spoken Harvard sentences from 7 subjects and consider their MFCC attributes. Using character level LSTMs (supervised learning) and OpenAI's attention-based GPT-2 models, synthetic MFCCs are generated by learning from the data provided on a per-subject basis. A neural network is trained to classify the data against a large dataset of Flickr8k speakers and is then compared to a transfer learning network performing the same task but with an initial weight distribution dictated by learning from the synthetic data generated by the two models. The best result for all of the 7 subjects were networks that had been exposed to synthetic data, the model pre-trained with LSTM-produced data achieved the best result 3 times and the GPT-2 equivalent 5 times (since one subject had their best result from both models at a draw). Through these results, we argue that speaker classification can be improved by utilising a small amount of user data but with exposure to synthetically-generated MFCCs which then allow the networks to achieve near maximum classification scores.