 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGoal-based Self-Adaptive Generative Adversarial Imitation Learning (Goal-SAGAIL) for Multi-goal Robotic Manipulation Tasks
Jun 15, 2025Reinforcement learning for multi-goal robot manipulation tasks poses significant challenges due to the diversity and complexity of the goal space. Techniques such as Hindsight Experience Replay (HER) have been introduced to improve learning efficiency for such tasks. More recently, researchers have combined HER with advanced imitation learning methods such as Generative Adversarial Imitation Learning (GAIL) to integrate demonstration data and accelerate training speed. However, demonstration data often fails to provide enough coverage for the goal space, especially when acquired from human teleoperation. This biases the learning-from-demonstration process toward mastering easier sub-tasks instead of tackling the more challenging ones. In this work, we present Goal-based Self-Adaptive Generative Adversarial Imitation Learning (Goal-SAGAIL), a novel framework specifically designed for multi-goal robot manipulation tasks. By integrating self-adaptive learning principles with goal-conditioned GAIL, our approach enhances imitation learning efficiency, even when limited, suboptimal demonstrations are available. Experimental results validate that our method significantly improves learning efficiency across various multi-goal manipulation scenarios -- including complex in-hand manipulation tasks -- using suboptimal demonstrations provided by both simulation and human experts.
BaseBoostDepth: Exploiting Larger Baselines For Self-supervised Monocular Depth Estimation
Jul 29, 2024
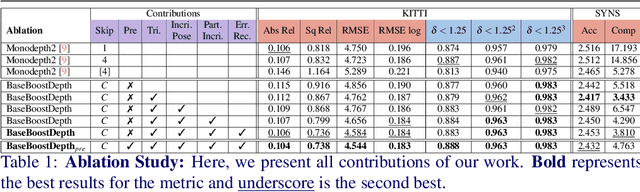
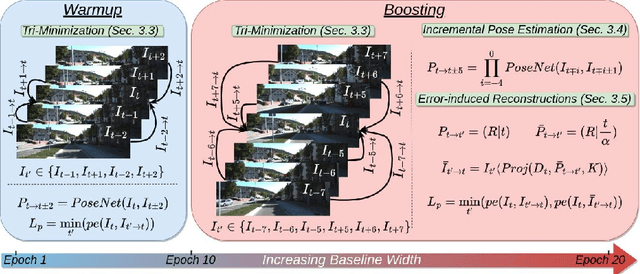
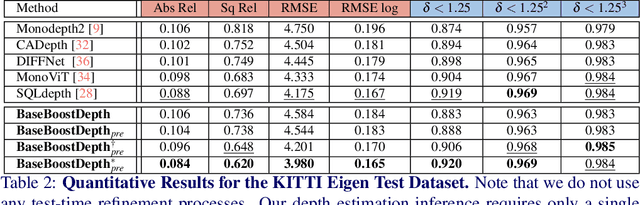
In the domain of multi-baseline stereo, the conventional understanding is that, in general, increasing baseline separation substantially enhances the accuracy of depth estimation. However, prevailing self-supervised depth estimation architectures primarily use minimal frame separation and a constrained stereo baseline. Larger frame separations can be employed; however, we show this to result in diminished depth quality due to various factors, including significant changes in brightness, and increased areas of occlusion. In response to these challenges, our proposed method, BaseBoostDepth, incorporates a curriculum learning-inspired optimization strategy to effectively leverage larger frame separations. However, we show that our curriculum learning-inspired strategy alone does not suffice, as larger baselines still cause pose estimation drifts. Therefore, we introduce incremental pose estimation to enhance the accuracy of pose estimations, resulting in significant improvements across all depth metrics. Additionally, to improve the robustness of the model, we introduce error-induced reconstructions, which optimize reconstructions with added error to the pose estimations. Ultimately, our final depth network achieves state-of-the-art performance on KITTI and SYNS-patches datasets across image-based, edge-based, and point cloud-based metrics without increasing computational complexity at test time. The project website can be found at https://kieran514.github.io/BaseBoostDepth-Project.
Synthesizing Traffic Datasets using Graph Neural Networks
Dec 08, 2023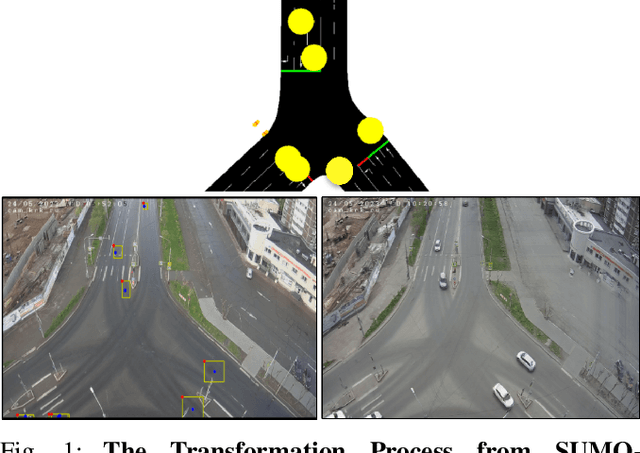
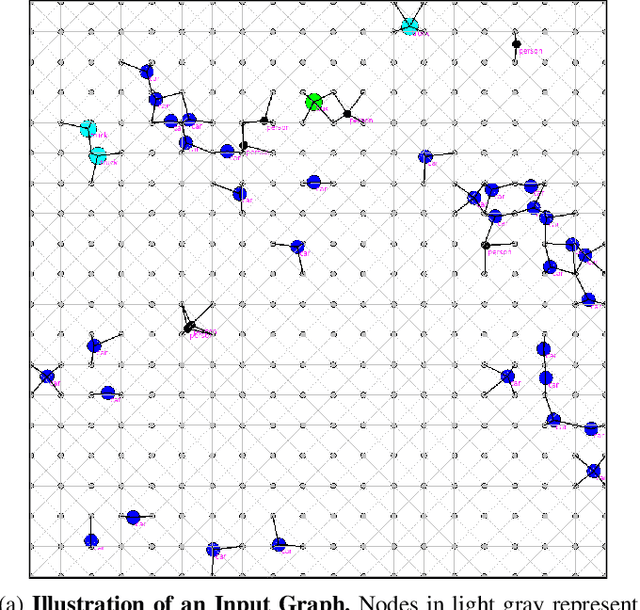
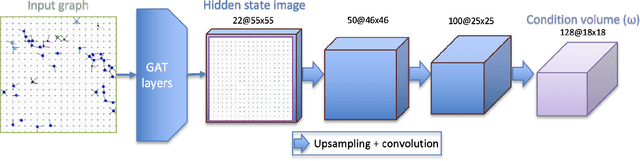
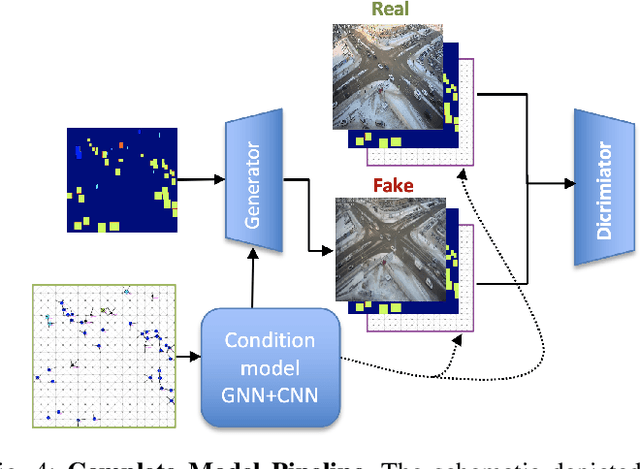
Traffic congestion in urban areas presents significant challenges, and Intelligent Transportation Systems (ITS) have sought to address these via automated and adaptive controls. However, these systems often struggle to transfer simulated experiences to real-world scenarios. This paper introduces a novel methodology for bridging this `sim-real' gap by creating photorealistic images from 2D traffic simulations and recorded junction footage. We propose a novel image generation approach, integrating a Conditional Generative Adversarial Network with a Graph Neural Network (GNN) to facilitate the creation of realistic urban traffic images. We harness GNNs' ability to process information at different levels of abstraction alongside segmented images for preserving locality data. The presented architecture leverages the power of SPADE and Graph ATtention (GAT) network models to create images based on simulated traffic scenarios. These images are conditioned by factors such as entity positions, colors, and time of day. The uniqueness of our approach lies in its ability to effectively translate structured and human-readable conditions, encoded as graphs, into realistic images. This advancement contributes to applications requiring rich traffic image datasets, from data augmentation to urban traffic solutions. We further provide an application to test the model's capabilities, including generating images with manually defined positions for various entities.
Self-supervised Monocular Depth Estimation: Let's Talk About The Weather
Jul 17, 2023
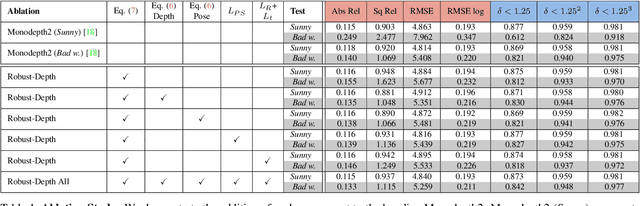

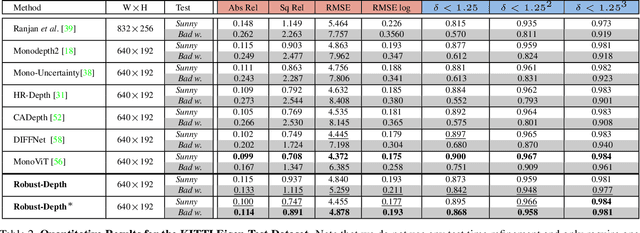
Current, self-supervised depth estimation architectures rely on clear and sunny weather scenes to train deep neural networks. However, in many locations, this assumption is too strong. For example in the UK (2021), 149 days consisted of rain. For these architectures to be effective in real-world applications, we must create models that can generalise to all weather conditions, times of the day and image qualities. Using a combination of computer graphics and generative models, one can augment existing sunny-weather data in a variety of ways that simulate adverse weather effects. While it is tempting to use such data augmentations for self-supervised depth, in the past this was shown to degrade performance instead of improving it. In this paper, we put forward a method that uses augmentations to remedy this problem. By exploiting the correspondence between unaugmented and augmented data we introduce a pseudo-supervised loss for both depth and pose estimation. This brings back some of the benefits of supervised learning while still not requiring any labels. We also make a series of practical recommendations which collectively offer a reliable, efficient framework for weather-related augmentation of self-supervised depth from monocular video. We present extensive testing to show that our method, Robust-Depth, achieves SotA performance on the KITTI dataset while significantly surpassing SotA on challenging, adverse condition data such as DrivingStereo, Foggy CityScape and NuScenes-Night. The project website can be found here https://kieran514.github.io/Robust-Depth-Project/.
Multi-person 3D pose estimation from unlabelled data
Dec 16, 2022Its numerous applications make multi-human 3D pose estimation a remarkably impactful area of research. Nevertheless, assuming a multiple-view system composed of several regular RGB cameras, 3D multi-pose estimation presents several challenges. First of all, each person must be uniquely identified in the different views to separate the 2D information provided by the cameras. Secondly, the 3D pose estimation process from the multi-view 2D information of each person must be robust against noise and potential occlusions in the scenario. In this work, we address these two challenges with the help of deep learning. Specifically, we present a model based on Graph Neural Networks capable of predicting the cross-view correspondence of the people in the scenario along with a Multilayer Perceptron that takes the 2D points to yield the 3D poses of each person. These two models are trained in a self-supervised manner, thus avoiding the need for large datasets with 3D annotations.
Dyna-DM: Dynamic Object-aware Self-supervised Monocular Depth Maps
Jun 23, 2022

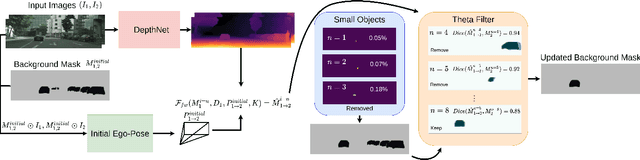
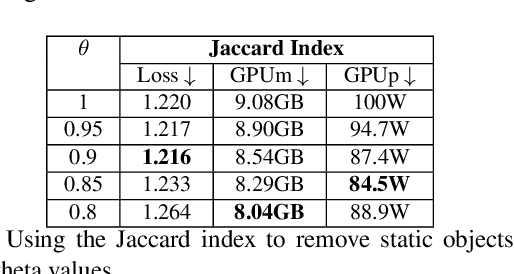
Self-supervised monocular depth estimation has been a subject of intense study in recent years, because of its applications in robotics and autonomous driving. Much of the recent work focuses on improving depth estimation by increasing architecture complexity. This paper shows that state-of-the-art performance can also be achieved by improving the learning process rather than increasing model complexity. More specifically, we propose (i) only using invariant pose loss for the first few epochs during training, (ii) disregarding small potentially dynamic objects when training, and (iii) employing an appearance-based approach to separately estimate object pose for truly dynamic objects. We demonstrate that these simplifications reduce GPU memory usage by 29% and result in qualitatively and quantitatively improved depth maps. The code is available at https://github.com/kieran514/Dyna-DM.
Multi-camera Torso Pose Estimation using Graph Neural Networks
Jul 28, 2020
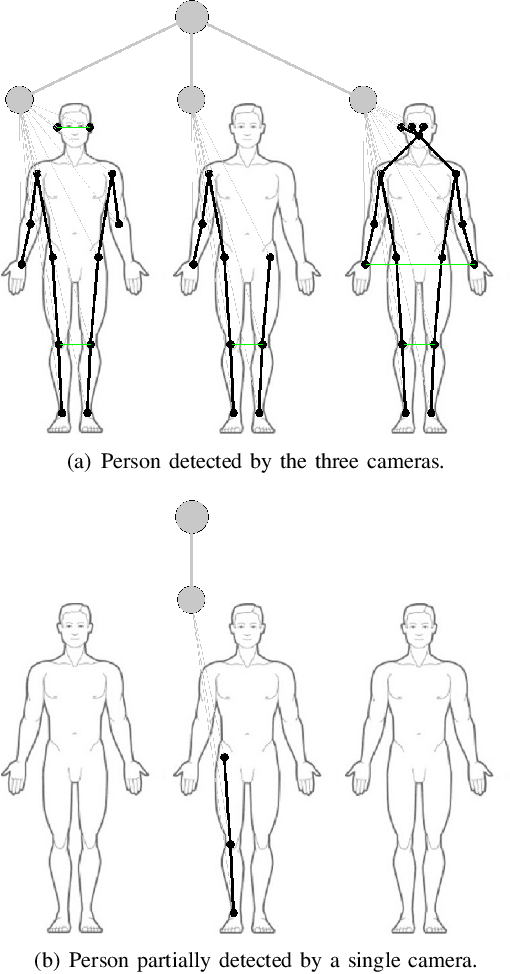
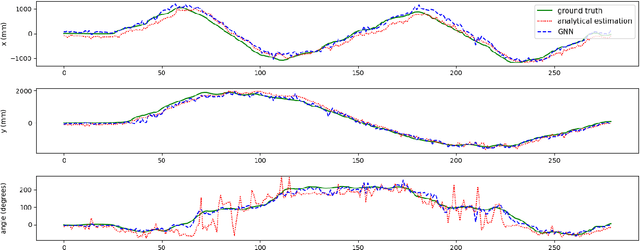
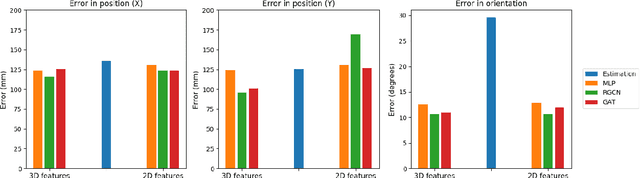
Estimating the location and orientation of humans is an essential skill for service and assistive robots. To achieve a reliable estimation in a wide area such as an apartment, multiple RGBD cameras are frequently used. Firstly, these setups are relatively expensive. Secondly, they seldom perform an effective data fusion using the multiple camera sources at an early stage of the processing pipeline. Occlusions and partial views make this second point very relevant in these scenarios. The proposal presented in this paper makes use of graph neural networks to merge the information acquired from multiple camera sources, achieving a mean absolute error below 125 mm for the location and 10 degrees for the orientation using low-resolution RGB images. The experiments, conducted in an apartment with three cameras, benchmarked two different graph neural network implementations and a third architecture based on fully connected layers. The software used has been released as open-source in a public repository (https://github.com/vangiel/WheresTheFellow).
Domain Adaptation for Reinforcement Learning on the Atari
Dec 18, 2018
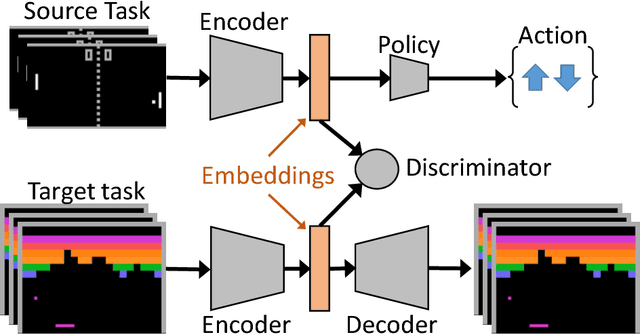


Deep reinforcement learning agents have recently been successful across a variety of discrete and continuous control tasks; however, they can be slow to train and require a large number of interactions with the environment to learn a suitable policy. This is borne out by the fact that a reinforcement learning agent has no prior knowledge of the world, no pre-existing data to depend on and so must devote considerable time to exploration. Transfer learning can alleviate some of the problems by leveraging learning done on some source task to help learning on some target task. Our work presents an algorithm for initialising the hidden feature representation of the target task. We propose a domain adaptation method to transfer state representations and demonstrate transfer across domains, tasks and action spaces. We utilise adversarial domain adaptation ideas combined with an adversarial autoencoder architecture. We align our new policies' representation space with a pre-trained source policy, taking target task data generated from a random policy. We demonstrate that this initialisation step provides significant improvement when learning a new reinforcement learning task, which highlights the wide applicability of adversarial adaptation methods; even as the task and label/action space also changes.
How to Read Paintings: Semantic Art Understanding with Multi-Modal Retrieval
Oct 23, 2018
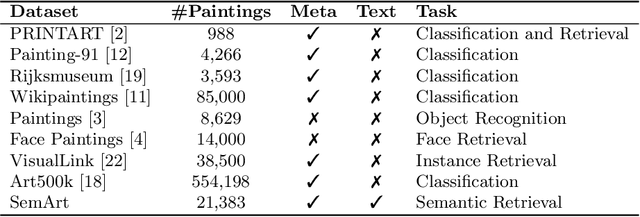
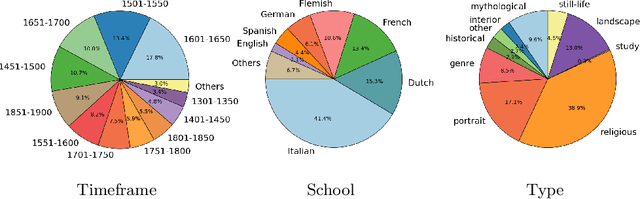
Automatic art analysis has been mostly focused on classifying artworks into different artistic styles. However, understanding an artistic representation involves more complex processes, such as identifying the elements in the scene or recognizing author influences. We present SemArt, a multi-modal dataset for semantic art understanding. SemArt is a collection of fine-art painting images in which each image is associated to a number of attributes and a textual artistic comment, such as those that appear in art catalogues or museum collections. To evaluate semantic art understanding, we envisage the Text2Art challenge, a multi-modal retrieval task where relevant paintings are retrieved according to an artistic text, and vice versa. We also propose several models for encoding visual and textual artistic representations into a common semantic space. Our best approach is able to find the correct image within the top 10 ranked images in the 45.5% of the test samples. Moreover, our models show remarkable levels of art understanding when compared against human evaluation.
Dress like a Star: Retrieving Fashion Products from Videos
Oct 19, 2017
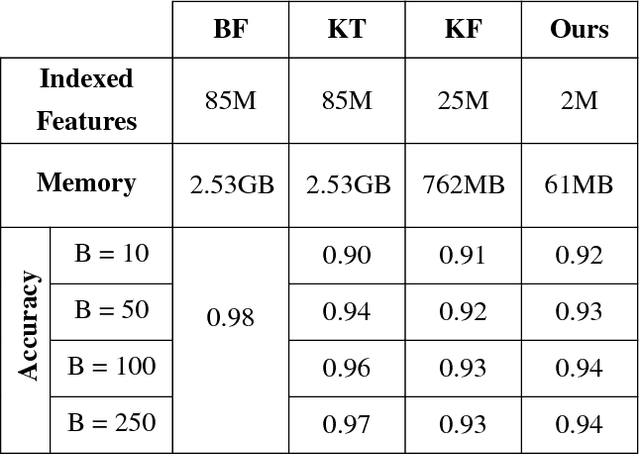
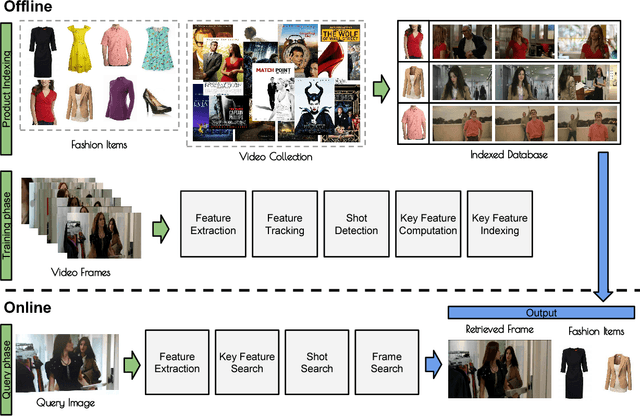
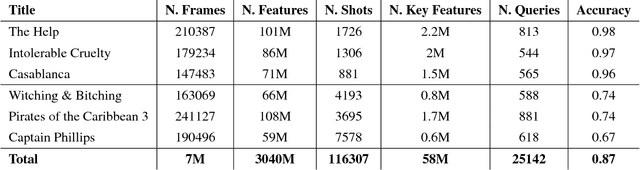
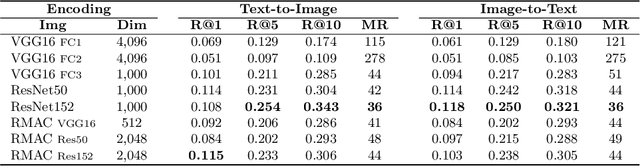
This work proposes a system for retrieving clothing and fashion products from video content. Although films and television are the perfect showcase for fashion brands to promote their products, spectators are not always aware of where to buy the latest trends they see on screen. Here, a framework for breaking the gap between fashion products shown on videos and users is presented. By relating clothing items and video frames in an indexed database and performing frame retrieval with temporal aggregation and fast indexing techniques, we can find fashion products from videos in a simple and non-intrusive way. Experiments in a large-scale dataset conducted here show that, by using the proposed framework, memory requirements can be reduced by 42.5X with respect to linear search, whereas accuracy is maintained at around 90%.