 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDyna-DM: Dynamic Object-aware Self-supervised Monocular Depth Maps
Paper and Code


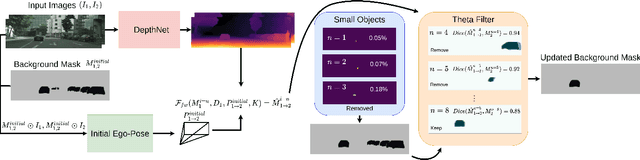
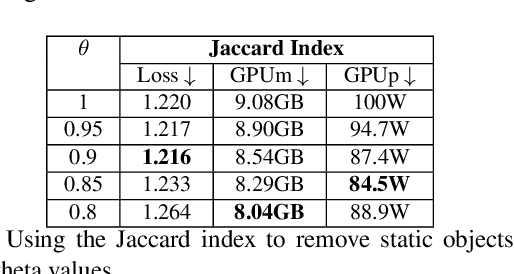
Self-supervised monocular depth estimation has been a subject of intense study in recent years, because of its applications in robotics and autonomous driving. Much of the recent work focuses on improving depth estimation by increasing architecture complexity. This paper shows that state-of-the-art performance can also be achieved by improving the learning process rather than increasing model complexity. More specifically, we propose (i) only using invariant pose loss for the first few epochs during training, (ii) disregarding small potentially dynamic objects when training, and (iii) employing an appearance-based approach to separately estimate object pose for truly dynamic objects. We demonstrate that these simplifications reduce GPU memory usage by 29% and result in qualitatively and quantitatively improved depth maps. The code is available at https://github.com/kieran514/Dyna-DM.