 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthesizing Traffic Datasets using Graph Neural Networks
Dec 08, 2023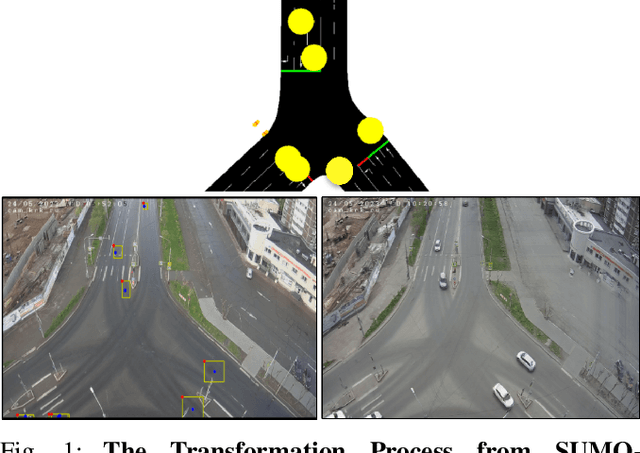
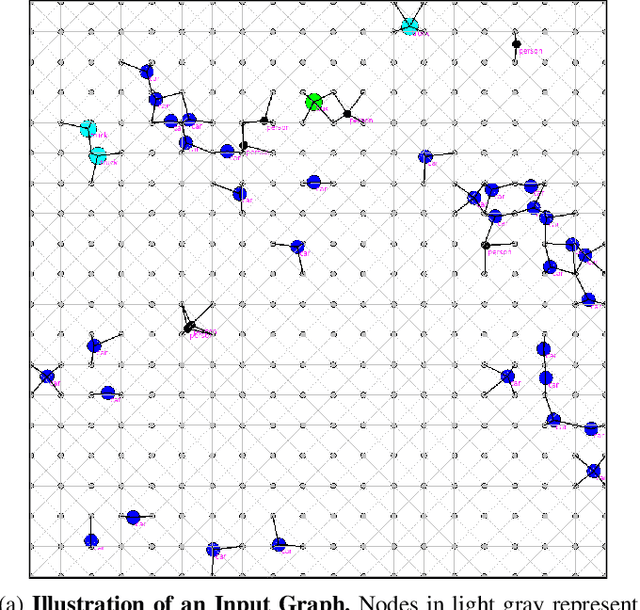
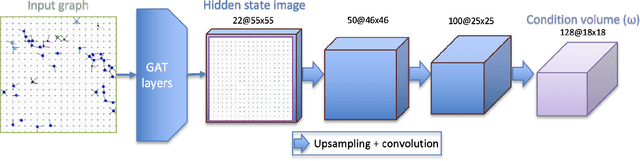
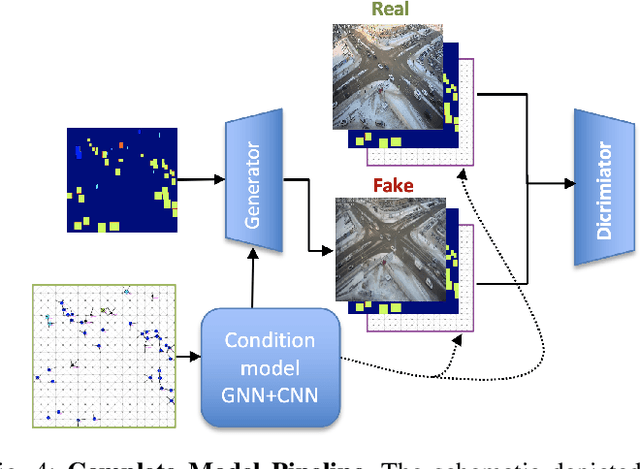
Traffic congestion in urban areas presents significant challenges, and Intelligent Transportation Systems (ITS) have sought to address these via automated and adaptive controls. However, these systems often struggle to transfer simulated experiences to real-world scenarios. This paper introduces a novel methodology for bridging this `sim-real' gap by creating photorealistic images from 2D traffic simulations and recorded junction footage. We propose a novel image generation approach, integrating a Conditional Generative Adversarial Network with a Graph Neural Network (GNN) to facilitate the creation of realistic urban traffic images. We harness GNNs' ability to process information at different levels of abstraction alongside segmented images for preserving locality data. The presented architecture leverages the power of SPADE and Graph ATtention (GAT) network models to create images based on simulated traffic scenarios. These images are conditioned by factors such as entity positions, colors, and time of day. The uniqueness of our approach lies in its ability to effectively translate structured and human-readable conditions, encoded as graphs, into realistic images. This advancement contributes to applications requiring rich traffic image datasets, from data augmentation to urban traffic solutions. We further provide an application to test the model's capabilities, including generating images with manually defined positions for various entities.
Optimal Auction Design for the Gradual Procurement of Strategic Service Provider Agents
Oct 25, 2021


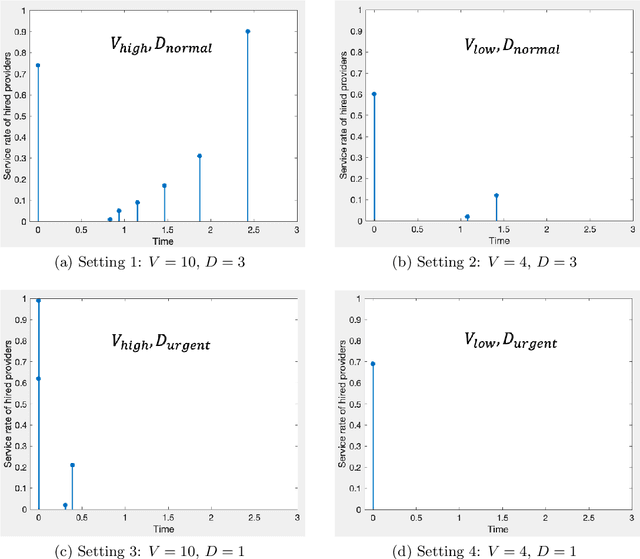
We consider an outsourcing problem where a software agent procures multiple services from providers with uncertain reliabilities to complete a computational task before a strict deadline. The service consumer requires a procurement strategy that achieves the optimal balance between success probability and invocation cost. However, the service providers are self-interested and may misrepresent their private cost information if it benefits them. For such settings, we design a novel procurement auction that provides the consumer with the highest possible revenue, while giving sufficient incentives to providers to tell the truth about their costs. This auction creates a contingent plan for gradual service procurement that suggests recruiting a new provider only when the success probability of the already hired providers drops below a time-dependent threshold. To make this auction incentive compatible, we propose a novel weighted threshold payment scheme which pays the minimum among all truthful mechanisms. Using the weighted payment scheme, we also design a low-complexity near-optimal auction that reduces the computational complexity of the optimal mechanism by 99% with only marginal performance loss (less than 1%). We demonstrate the effectiveness and strength of our proposed auctions through both game theoretical and numerical analysis. The experiment results confirm that the proposed auctions exhibit 59% improvement in performance over the current state-of-the-art, by increasing success probability up to 79% and reducing invocation cost by up to 11%.
Domain Adaptation for Reinforcement Learning on the Atari
Dec 18, 2018
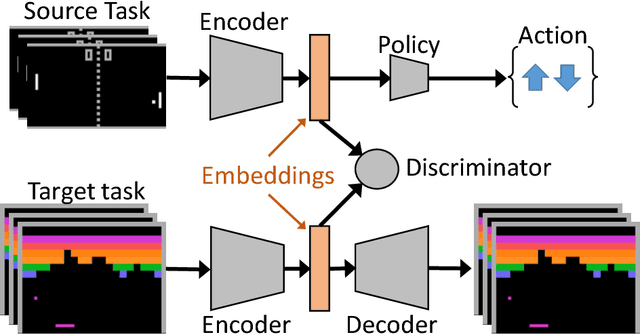


Deep reinforcement learning agents have recently been successful across a variety of discrete and continuous control tasks; however, they can be slow to train and require a large number of interactions with the environment to learn a suitable policy. This is borne out by the fact that a reinforcement learning agent has no prior knowledge of the world, no pre-existing data to depend on and so must devote considerable time to exploration. Transfer learning can alleviate some of the problems by leveraging learning done on some source task to help learning on some target task. Our work presents an algorithm for initialising the hidden feature representation of the target task. We propose a domain adaptation method to transfer state representations and demonstrate transfer across domains, tasks and action spaces. We utilise adversarial domain adaptation ideas combined with an adversarial autoencoder architecture. We align our new policies' representation space with a pre-trained source policy, taking target task data generated from a random policy. We demonstrate that this initialisation step provides significant improvement when learning a new reinforcement learning task, which highlights the wide applicability of adversarial adaptation methods; even as the task and label/action space also changes.