Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Nested Optimization for Deep Learning
Paper and Code


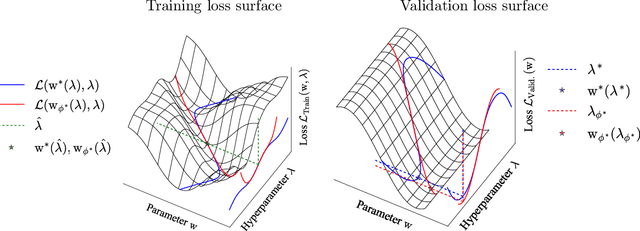
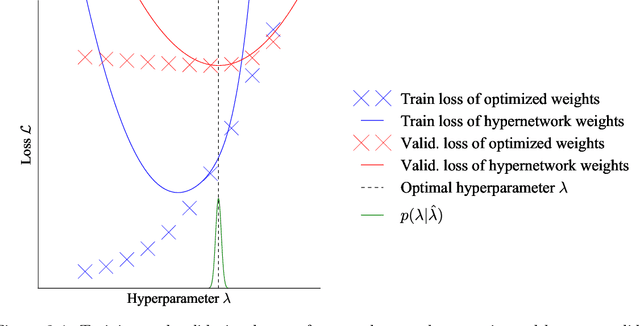
Gradient-based optimization has been critical to the success of machine learning, updating a single set of parameters to minimize a single loss. A growing number of applications rely on a generalization of this, where we have a bilevel or nested optimization of which subsets of parameters update on different objectives nested inside each other. We focus on motivating examples of hyperparameter optimization and generative adversarial networks. However, naively applying classical methods often fails when we look at solving these nested problems on a large scale. In this thesis, we build tools for nested optimization that scale to deep learning setups.
* View more research details at https://www.jonlorraine.com/
View paper on