 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Dict: Deep Learning-based Lossy Time Series Compressor for IoT Data
Paper and Code
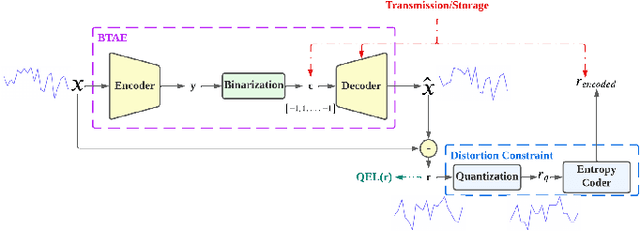
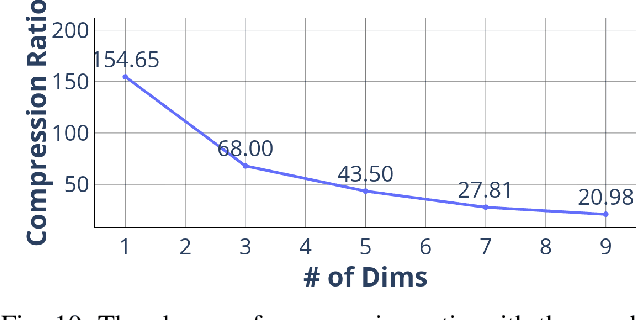
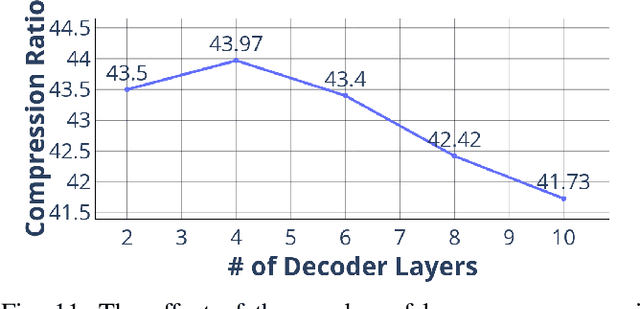
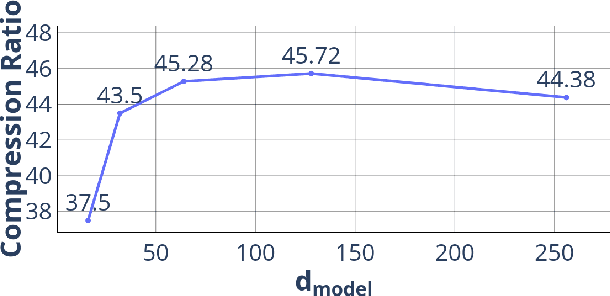
We propose Deep Dict, a deep learning-based lossy time series compressor designed to achieve a high compression ratio while maintaining decompression error within a predefined range. Deep Dict incorporates two essential components: the Bernoulli transformer autoencoder (BTAE) and a distortion constraint. BTAE extracts Bernoulli representations from time series data, reducing the size of the representations compared to conventional autoencoders. The distortion constraint limits the prediction error of BTAE to the desired range. Moreover, in order to address the limitations of common regression losses such as L1/L2, we introduce a novel loss function called quantized entropy loss (QEL). QEL takes into account the specific characteristics of the problem, enhancing robustness to outliers and alleviating optimization challenges. Our evaluation of Deep Dict across ten diverse time series datasets from various domains reveals that Deep Dict outperforms state-of-the-art lossy compressors in terms of compression ratio by a significant margin by up to 53.66%.